 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Improving the Use of Graph Information in Graph Neural Networks
Jun 27, 2022
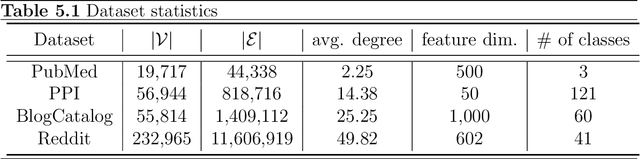
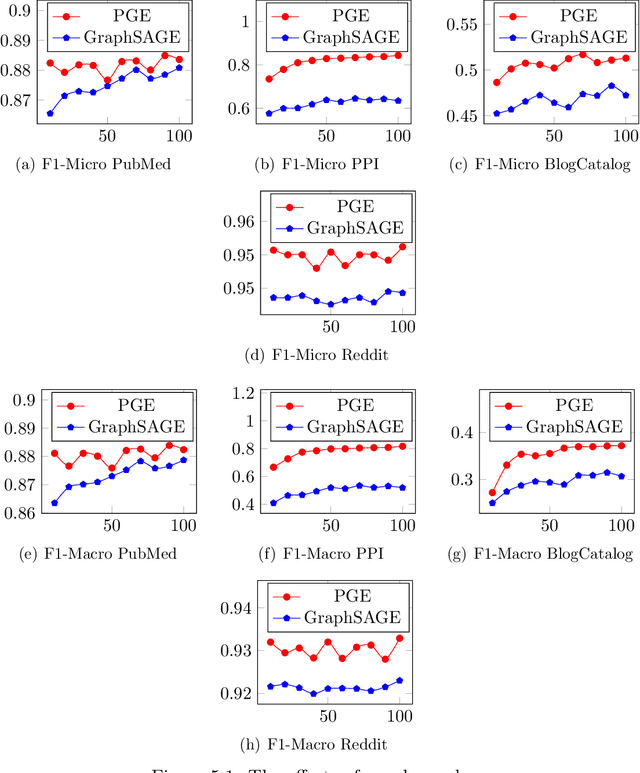
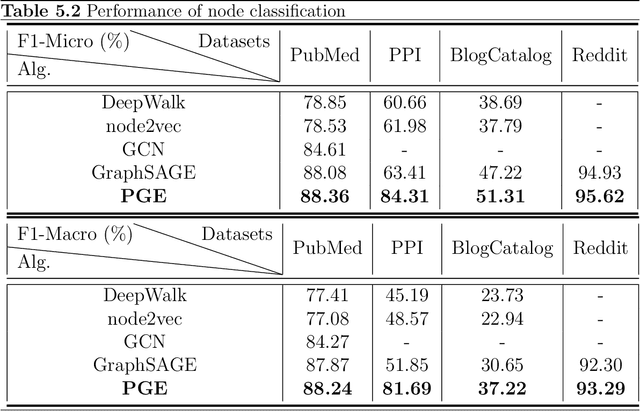
Graph neural networks (GNNs) have been widely used for representation learning on graph data. However, there is limited understanding on how much performance GNNs actually gain from graph data. This paper introduces a context-surrounding GNN framework and proposes two smoothness metrics to measure the quantity and quality of information obtained from graph data. A new GNN model, called CS-GNN, is then designed to improve the use of graph information based on the smoothness values of a graph. CS-GNN is shown to achieve better performance than existing methods in different types of real graphs.
Efficient Private SCO for Heavy-Tailed Data via Clipping
Jun 27, 2022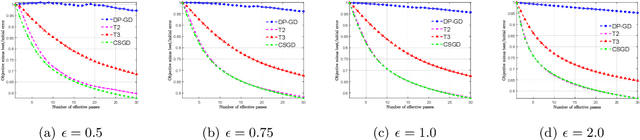
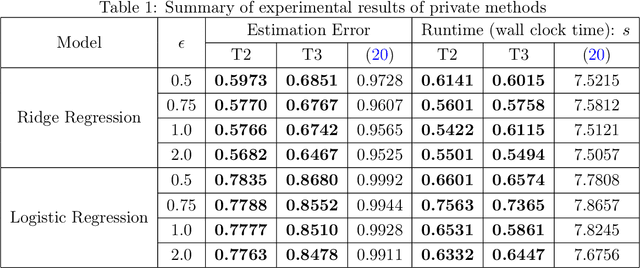
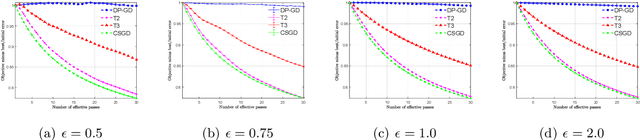
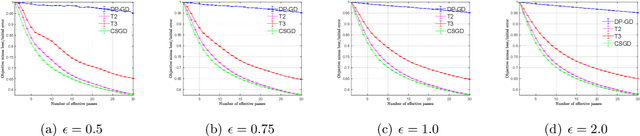
We consider stochastic convex optimization for heavy-tailed data with the guarantee of being differentially private (DP). Prior work on this problem is restricted to the gradient descent (GD) method, which is inefficient for large-scale problems. In this paper, we resolve this issue and derive the first high-probability bounds for private stochastic method with clipping. For general convex problems, we derive excess population risks $\Tilde{O}\left(\frac{d^{1/7}\sqrt{\ln\frac{(n \epsilon)^2}{\beta d}}}{(n\epsilon)^{2/7}}\right)$ and $\Tilde{O}\left(\frac{d^{1/7}\ln\frac{(n\epsilon)^2}{\beta d}}{(n\epsilon)^{2/7}}\right)$ under bounded or unbounded domain assumption, respectively (here $n$ is the sample size, $d$ is the dimension of the data, $\beta$ is the confidence level and $\epsilon$ is the private level). Then, we extend our analysis to the strongly convex case and non-smooth case (which works for generalized smooth objectives with H$\ddot{\text{o}}$lder-continuous gradients). We establish new excess risk bounds without bounded domain assumption. The results above achieve lower excess risks and gradient complexities than existing methods in their corresponding cases. Numerical experiments are conducted to justify the theoretical improvement.
Pareto Invariant Risk Minimization
Jun 15, 2022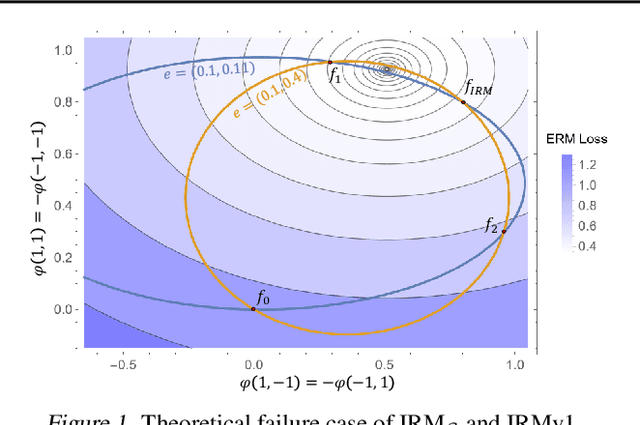
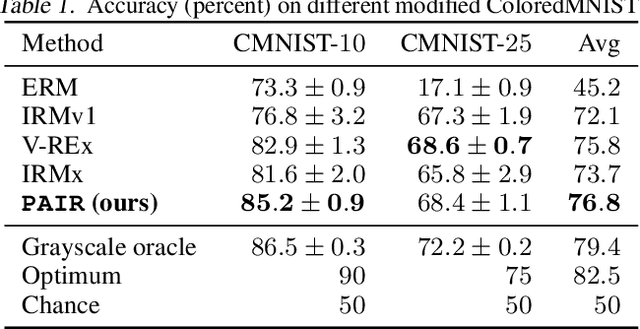
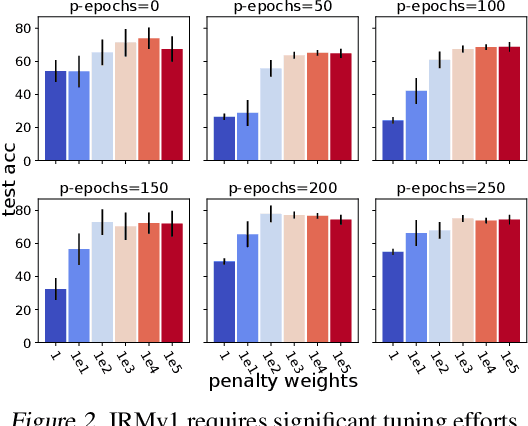
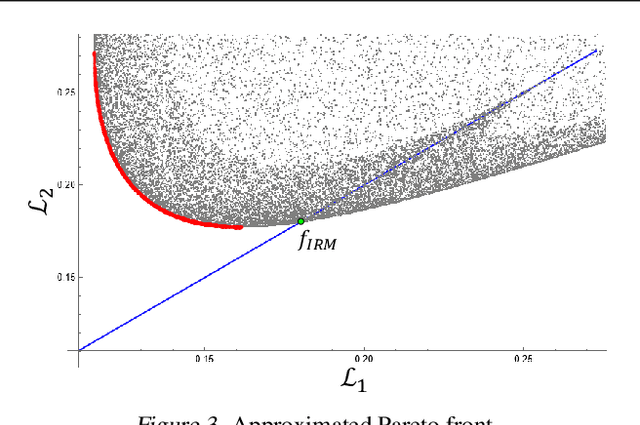
Despite the success of invariant risk minimization (IRM) in tackling the Out-of-Distribution generalization problem, IRM can compromise the optimality when applied in practice. The practical variants of IRM, e.g., IRMv1, have been shown to have significant gaps with IRM and thus could fail to capture the invariance even in simple problems. Moreover, the optimization procedure in IRMv1 involves two intrinsically conflicting objectives, and often requires careful tuning for the objective weights. To remedy the above issues, we reformulate IRM as a multi-objective optimization problem, and propose a new optimization scheme for IRM, called PAreto Invariant Risk Minimization (PAIR). PAIR can adaptively adjust the optimization direction under the objective conflicts. Furthermore, we show PAIR can empower the practical IRM variants to overcome the barriers with the original IRM when provided with proper guidance. We conduct experiments with ColoredMNIST to confirm our theory and the effectiveness of PAIR.
Fast and Reliable Evaluation of Adversarial Robustness with Minimum-Margin Attack
Jun 15, 2022The AutoAttack (AA) has been the most reliable method to evaluate adversarial robustness when considerable computational resources are available. However, the high computational cost (e.g., 100 times more than that of the project gradient descent attack) makes AA infeasible for practitioners with limited computational resources, and also hinders applications of AA in the adversarial training (AT). In this paper, we propose a novel method, minimum-margin (MM) attack, to fast and reliably evaluate adversarial robustness. Compared with AA, our method achieves comparable performance but only costs 3% of the computational time in extensive experiments. The reliability of our method lies in that we evaluate the quality of adversarial examples using the margin between two targets that can precisely identify the most adversarial example. The computational efficiency of our method lies in an effective Sequential TArget Ranking Selection (STARS) method, ensuring that the cost of the MM attack is independent of the number of classes. The MM attack opens a new way for evaluating adversarial robustness and provides a feasible and reliable way to generate high-quality adversarial examples in AT.
An Adaptive Incremental Gradient Method With Support for Non-Euclidean Norms
Apr 28, 2022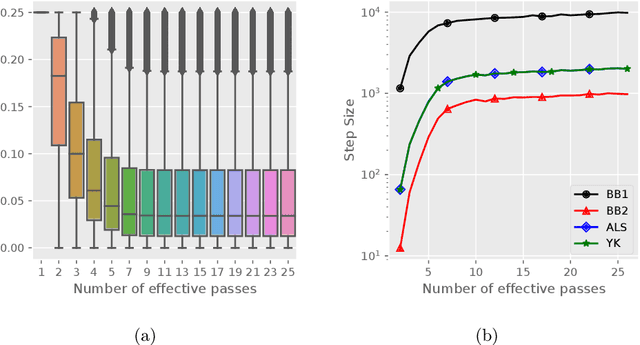
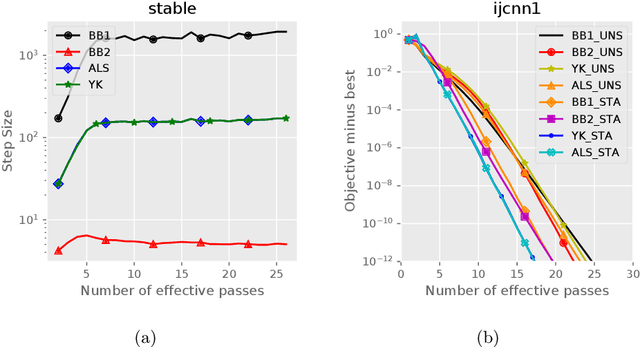
Stochastic variance reduced methods have shown strong performance in solving finite-sum problems. However, these methods usually require the users to manually tune the step-size, which is time-consuming or even infeasible for some large-scale optimization tasks. To overcome the problem, we propose and analyze several novel adaptive variants of the popular SAGA algorithm. Eventually, we design a variant of Barzilai-Borwein step-size which is tailored for the incremental gradient method to ensure memory efficiency and fast convergence. We establish its convergence guarantees under general settings that allow non-Euclidean norms in the definition of smoothness and the composite objectives, which cover a broad range of applications in machine learning. We improve the analysis of SAGA to support non-Euclidean norms, which fills the void of existing work. Numerical experiments on standard datasets demonstrate a competitive performance of the proposed algorithm compared with existing variance-reduced methods and their adaptive variants.
Understanding and Improving Graph Injection Attack by Promoting Unnoticeability
Feb 16, 2022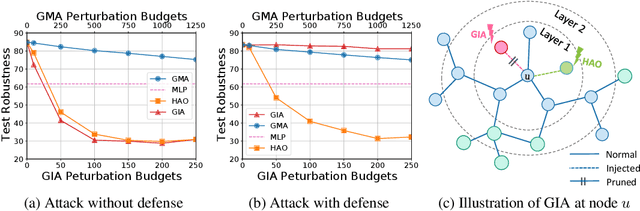
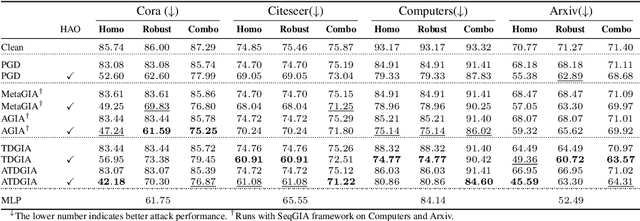
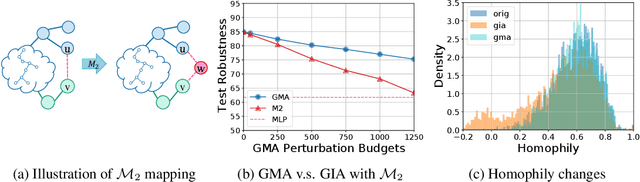
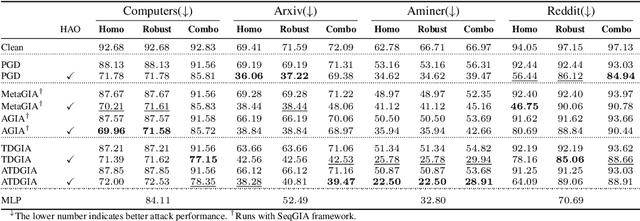
Recently Graph Injection Attack (GIA) emerges as a practical attack scenario on Graph Neural Networks (GNNs), where the adversary can merely inject few malicious nodes instead of modifying existing nodes or edges, i.e., Graph Modification Attack (GMA). Although GIA has achieved promising results, little is known about why it is successful and whether there is any pitfall behind the success. To understand the power of GIA, we compare it with GMA and find that GIA can be provably more harmful than GMA due to its relatively high flexibility. However, the high flexibility will also lead to great damage to the homophily distribution of the original graph, i.e., similarity among neighbors. Consequently, the threats of GIA can be easily alleviated or even prevented by homophily-based defenses designed to recover the original homophily. To mitigate the issue, we introduce a novel constraint -- homophily unnoticeability that enforces GIA to preserve the homophily, and propose Harmonious Adversarial Objective (HAO) to instantiate it. Extensive experiments verify that GIA with HAO can break homophily-based defenses and outperform previous GIA attacks by a significant margin. We believe our methods can serve for a more reliable evaluation of the robustness of GNNs.
Invariance Principle Meets Out-of-Distribution Generalization on Graphs
Feb 11, 2022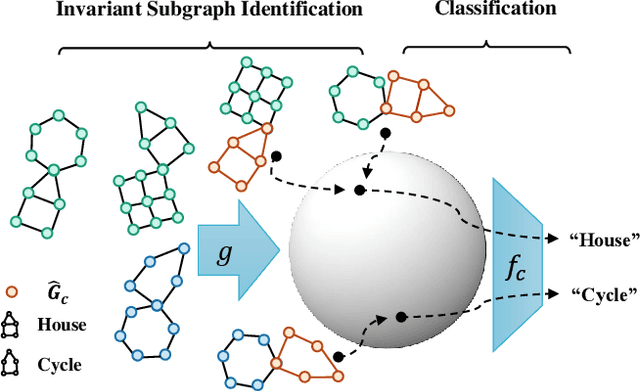

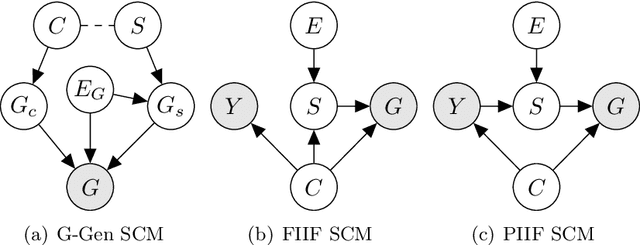
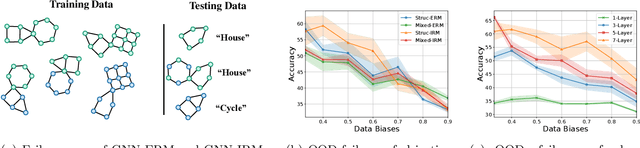
Despite recent developments in using the invariance principle from causality to enable out-of-distribution (OOD) generalization on Euclidean data, e.g., images, studies on graph data are limited. Different from images, the complex nature of graphs poses unique challenges that thwart the adoption of the invariance principle for OOD generalization. In particular, distribution shifts on graphs can happen at both structure-level and attribute-level, which increases the difficulty of capturing the invariance. Moreover, domain or environment partitions, which are often required by OOD methods developed on Euclidean data, can be expensive to obtain for graphs. Aiming to bridge this gap, we characterize distribution shifts on graphs with causal models, and show that the OOD generalization on graphs with invariance principle is possible by identifying an invariant subgraph for making predictions. We propose a novel framework to explicitly model this process using a contrastive strategy. By contrasting the estimated invariant subgraphs, our framework can provably identify the underlying invariant subgraph under mild assumptions. Experiments across several synthetic and real-world datasets demonstrate the state-of-the-art OOD generalization ability of our method.
Accelerating Perturbed Stochastic Iterates in Asynchronous Lock-Free Optimization
Sep 30, 2021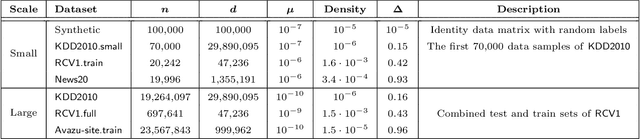


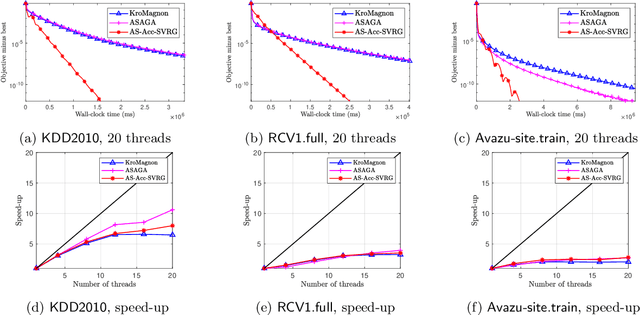
We show that stochastic acceleration can be achieved under the perturbed iterate framework (Mania et al., 2017) in asynchronous lock-free optimization, which leads to the optimal incremental gradient complexity for finite-sum objectives. We prove that our new accelerated method requires the same linear speed-up condition as the existing non-accelerated methods. Our core algorithmic discovery is a new accelerated SVRG variant with sparse updates. Empirical results are presented to verify our theoretical findings.
Local Reweighting for Adversarial Training
Jun 30, 2021Instances-reweighted adversarial training (IRAT) can significantly boost the robustness of trained models, where data being less/more vulnerable to the given attack are assigned smaller/larger weights during training. However, when tested on attacks different from the given attack simulated in training, the robustness may drop significantly (e.g., even worse than no reweighting). In this paper, we study this problem and propose our solution--locally reweighted adversarial training (LRAT). The rationale behind IRAT is that we do not need to pay much attention to an instance that is already safe under the attack. We argue that the safeness should be attack-dependent, so that for the same instance, its weight can change given different attacks based on the same model. Thus, if the attack simulated in training is mis-specified, the weights of IRAT are misleading. To this end, LRAT pairs each instance with its adversarial variants and performs local reweighting inside each pair, while performing no global reweighting--the rationale is to fit the instance itself if it is immune to the attack, but not to skip the pair, in order to passively defend different attacks in future. Experiments show that LRAT works better than both IRAT (i.e., global reweighting) and the standard AT (i.e., no reweighting) when trained with an attack and tested on different attacks.
Practical Schemes for Finding Near-Stationary Points of Convex Finite-Sums
May 25, 2021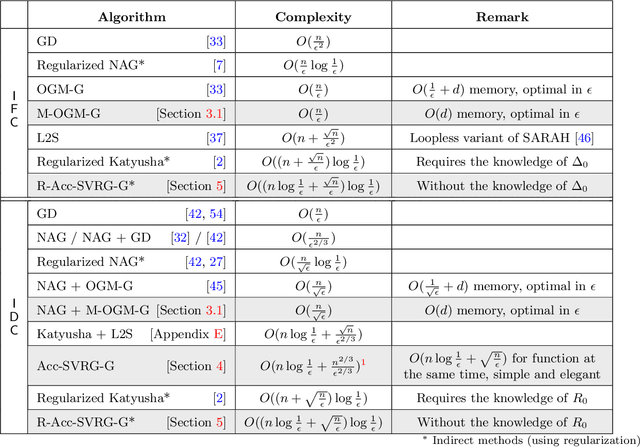
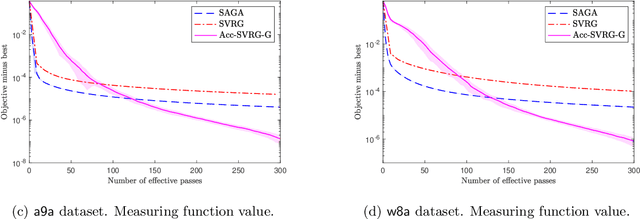
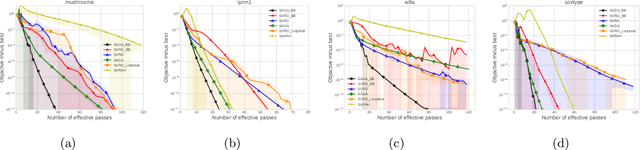
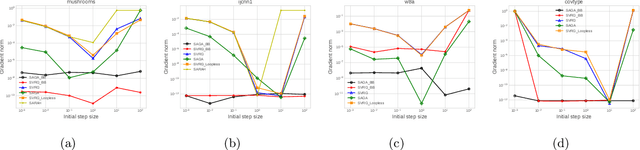
The problem of finding near-stationary points in convex optimization has not been adequately studied yet, unlike other optimality measures such as minimizing function value. Even in the deterministic case, the optimal method (OGM-G, due to Kim and Fessler (2021)) has just been discovered recently. In this work, we conduct a systematic study of the algorithmic techniques in finding near-stationary points of convex finite-sums. Our main contributions are several algorithmic discoveries: (1) we discover a memory-saving variant of OGM-G based on the performance estimation problem approach (Drori and Teboulle, 2014); (2) we design a new accelerated SVRG variant that can simultaneously achieve fast rates for both minimizing gradient norm and function value; (3) we propose an adaptively regularized accelerated SVRG variant, which does not require the knowledge of some unknown initial constants and achieves near-optimal complexities. We put an emphasis on the simplicity and practicality of the new schemes, which could facilitate future developments.