 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthoMAD: Morphing Attack Detection Through Orthogonal Identity Disentanglement
Aug 23, 2022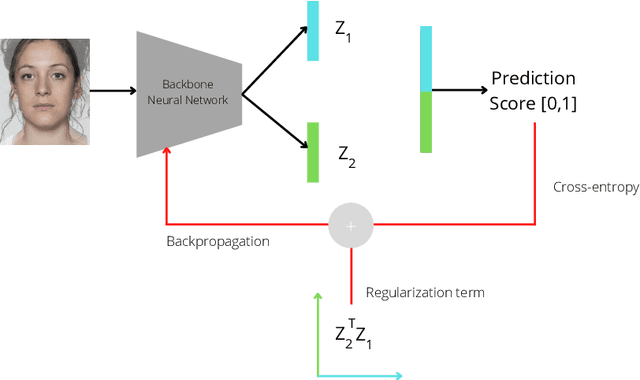
Morphing attacks are one of the many threats that are constantly affecting deep face recognition systems. It consists of selecting two faces from different individuals and fusing them into a final image that contains the identity information of both. In this work, we propose a novel regularisation term that takes into account the existent identity information in both and promotes the creation of two orthogonal latent vectors. We evaluate our proposed method (OrthoMAD) in five different types of morphing in the FRLL dataset and evaluate the performance of our model when trained on five distinct datasets. With a small ResNet-18 as the backbone, we achieve state-of-the-art results in the majority of the experiments, and competitive results in the others. The code of this paper will be publicly available.
Explainable Biometrics in the Age of Deep Learning
Aug 19, 2022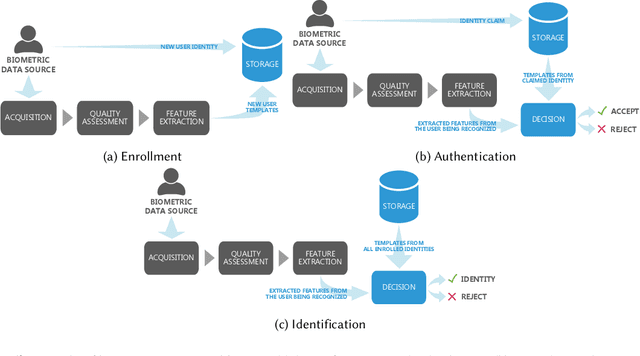
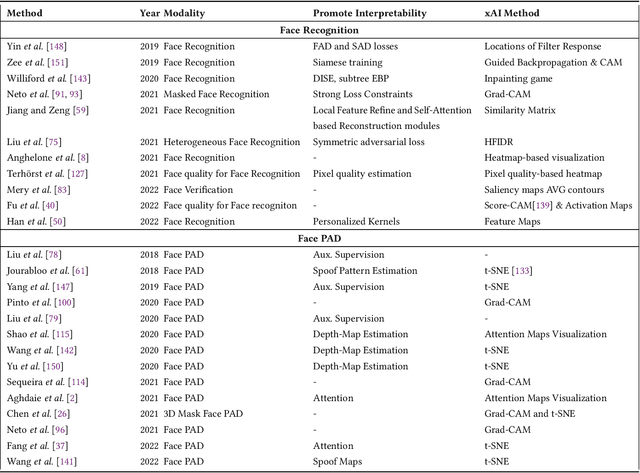
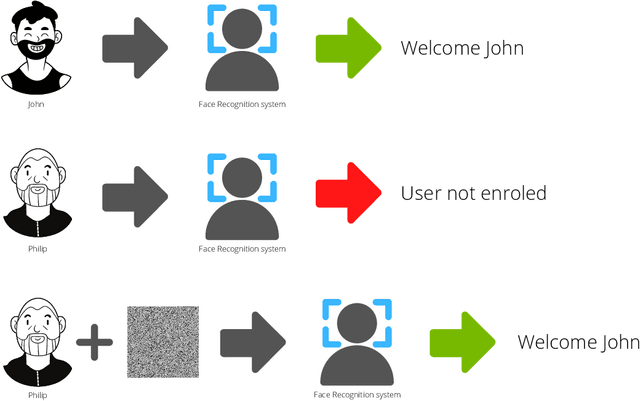
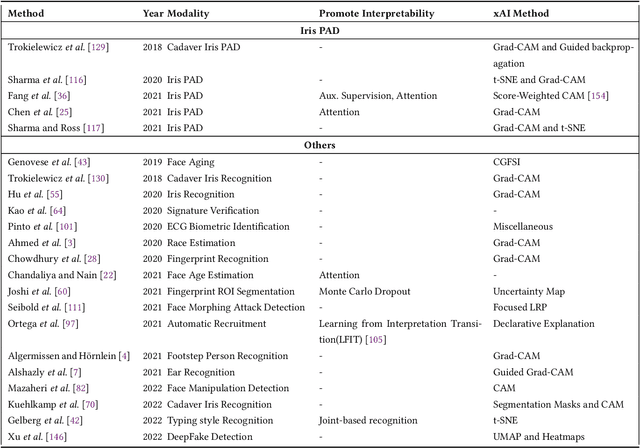
Systems capable of analyzing and quantifying human physical or behavioral traits, known as biometrics systems, are growing in use and application variability. Since its evolution from handcrafted features and traditional machine learning to deep learning and automatic feature extraction, the performance of biometric systems increased to outstanding values. Nonetheless, the cost of this fast progression is still not understood. Due to its opacity, deep neural networks are difficult to understand and analyze, hence, hidden capacities or decisions motivated by the wrong motives are a potential risk. Researchers have started to pivot their focus towards the understanding of deep neural networks and the explanation of their predictions. In this paper, we provide a review of the current state of explainable biometrics based on the study of 47 papers and discuss comprehensively the direction in which this field should be developed.
SYN-MAD 2022: Competition on Face Morphing Attack Detection Based on Privacy-aware Synthetic Training Data
Aug 15, 2022
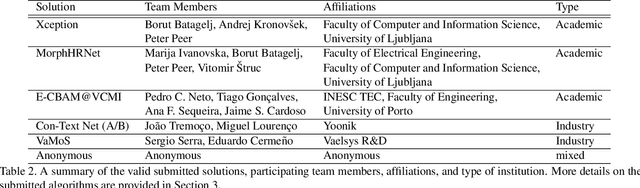
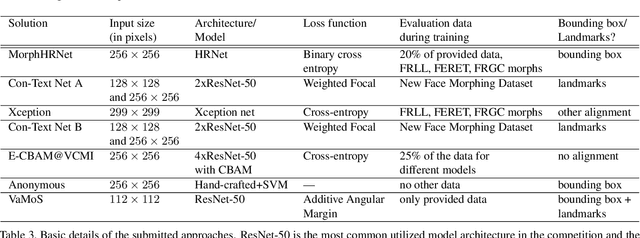
This paper presents a summary of the Competition on Face Morphing Attack Detection Based on Privacy-aware Synthetic Training Data (SYN-MAD) held at the 2022 International Joint Conference on Biometrics (IJCB 2022). The competition attracted a total of 12 participating teams, both from academia and industry and present in 11 different countries. In the end, seven valid submissions were submitted by the participating teams and evaluated by the organizers. The competition was held to present and attract solutions that deal with detecting face morphing attacks while protecting people's privacy for ethical and legal reasons. To ensure this, the training data was limited to synthetic data provided by the organizers. The submitted solutions presented innovations that led to outperforming the considered baseline in many experimental settings. The evaluation benchmark is now available at: https://github.com/marcohuber/SYN-MAD-2022.
OCFR 2022: Competition on Occluded Face Recognition From Synthetically Generated Structure-Aware Occlusions
Aug 15, 2022



This work summarizes the IJCB Occluded Face Recognition Competition 2022 (IJCB-OCFR-2022) embraced by the 2022 International Joint Conference on Biometrics (IJCB 2022). OCFR-2022 attracted a total of 3 participating teams, from academia. Eventually, six valid submissions were submitted and then evaluated by the organizers. The competition was held to address the challenge of face recognition in the presence of severe face occlusions. The participants were free to use any training data and the testing data was built by the organisers by synthetically occluding parts of the face images using a well-known dataset. The submitted solutions presented innovations and performed very competitively with the considered baseline. A major output of this competition is a challenging, realistic, and diverse, and publicly available occluded face recognition benchmark with well defined evaluation protocols.
Deep Aesthetic Assessment and Retrieval of Breast Cancer Treatment Outcomes
May 25, 2022Treatments for breast cancer have continued to evolve and improve in recent years, resulting in a substantial increase in survival rates, with approximately 80\% of patients having a 10-year survival period. Given the serious impact that breast cancer treatments can have on a patient's body image, consequently affecting her self-confidence and sexual and intimate relationships, it is paramount to ensure that women receive the treatment that optimizes both survival and aesthetic outcomes. Currently, there is no gold standard for evaluating the aesthetic outcome of breast cancer treatment. In addition, there is no standard way to show patients the potential outcome of surgery. The presentation of similar cases from the past would be extremely important to manage women's expectations of the possible outcome. In this work, we propose a deep neural network to perform the aesthetic evaluation. As a proof-of-concept, we focus on a binary aesthetic evaluation. Besides its use for classification, this deep neural network can also be used to find the most similar past cases by searching for nearest neighbours in the highly semantic space before classification. We performed the experiments on a dataset consisting of 143 photos of women after conservative treatment for breast cancer. The results for accuracy and balanced accuracy showed the superior performance of our proposed model compared to the state of the art in aesthetic evaluation of breast cancer treatments. In addition, the model showed a good ability to retrieve similar previous cases, with the retrieved cases having the same or adjacent class (in the 4-class setting) and having similar types of asymmetry. Finally, a qualitative interpretability assessment was also performed to analyse the robustness and trustworthiness of the model.
A survey on attention mechanisms for medical applications: are we moving towards better algorithms?
Apr 26, 2022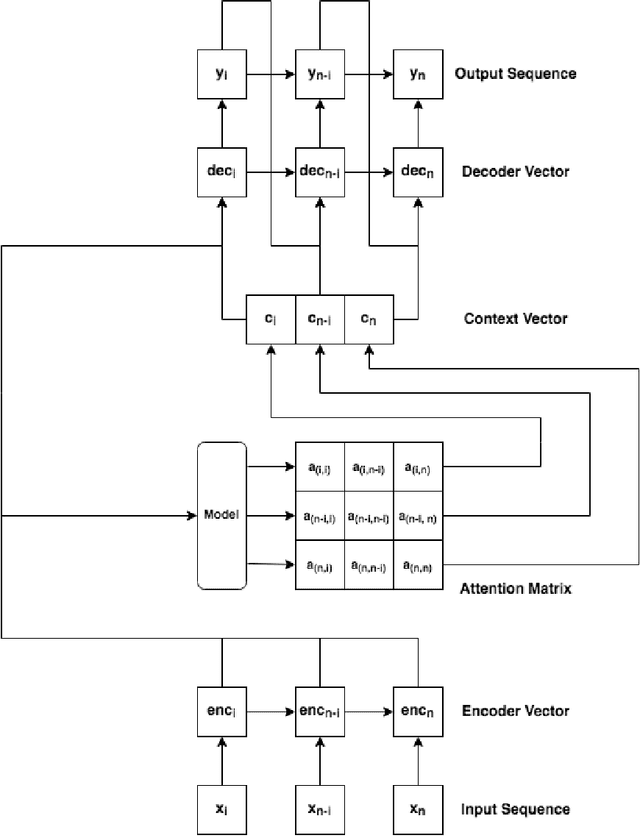

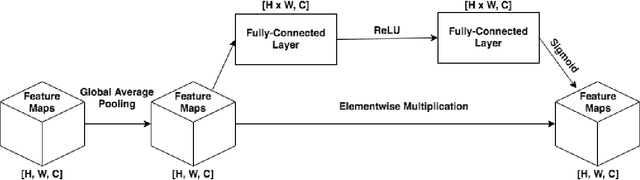
The increasing popularity of attention mechanisms in deep learning algorithms for computer vision and natural language processing made these models attractive to other research domains. In healthcare, there is a strong need for tools that may improve the routines of the clinicians and the patients. Naturally, the use of attention-based algorithms for medical applications occurred smoothly. However, being healthcare a domain that depends on high-stake decisions, the scientific community must ponder if these high-performing algorithms fit the needs of medical applications. With this motto, this paper extensively reviews the use of attention mechanisms in machine learning (including Transformers) for several medical applications. This work distinguishes itself from its predecessors by proposing a critical analysis of the claims and potentialities of attention mechanisms presented in the literature through an experimental case study on medical image classification with three different use cases. These experiments focus on the integrating process of attention mechanisms into established deep learning architectures, the analysis of their predictive power, and a visual assessment of their saliency maps generated by post-hoc explanation methods. This paper concludes with a critical analysis of the claims and potentialities presented in the literature about attention mechanisms and proposes future research lines in medical applications that may benefit from these frameworks.
Colon Nuclei Instance Segmentation using a Probabilistic Two-Stage Detector
Mar 01, 2022
Cancer is one of the leading causes of death in the developed world. Cancer diagnosis is performed through the microscopic analysis of a sample of suspicious tissue. This process is time consuming and error prone, but Deep Learning models could be helpful for pathologists during cancer diagnosis. We propose to change the CenterNet2 object detection model to also perform instance segmentation, which we call SegCenterNet2. We train SegCenterNet2 in the CoNIC challenge dataset and show that it performs better than Mask R-CNN in the competition metrics.
Myope Models -- Are face presentation attack detection models short-sighted?
Nov 22, 2021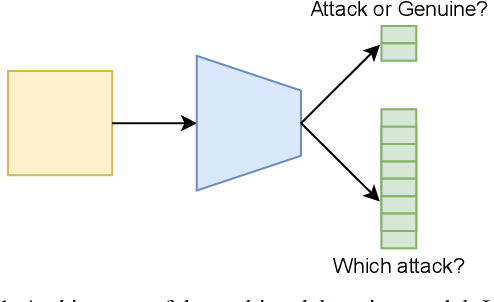

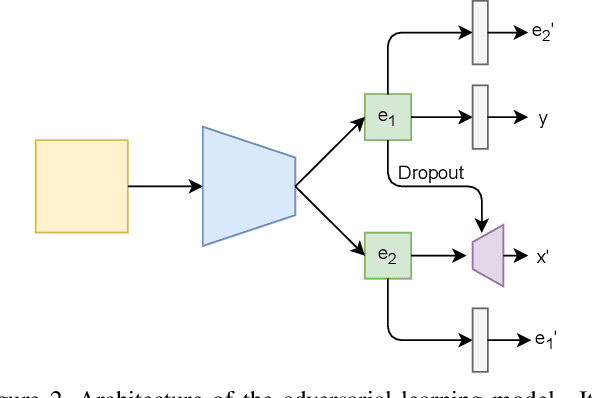
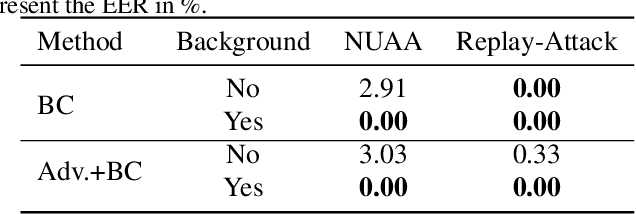
Presentation attacks are recurrent threats to biometric systems, where impostors attempt to bypass these systems. Humans often use background information as contextual cues for their visual system. Yet, regarding face-based systems, the background is often discarded, since face presentation attack detection (PAD) models are mostly trained with face crops. This work presents a comparative study of face PAD models (including multi-task learning, adversarial training and dynamic frame selection) in two settings: with and without crops. The results show that the performance is consistently better when the background is present in the images. The proposed multi-task methodology beats the state-of-the-art results on the ROSE-Youtu dataset by a large margin with an equal error rate of 0.2%. Furthermore, we analyze the models' predictions with Grad-CAM++ with the aim to investigate to what extent the models focus on background elements that are known to be useful for human inspection. From this analysis we can conclude that the background cues are not relevant across all the attacks. Thus, showing the capability of the model to leverage the background information only when necessary.
FocusFace: Multi-task Contrastive Learning for Masked Face Recognition
Nov 01, 2021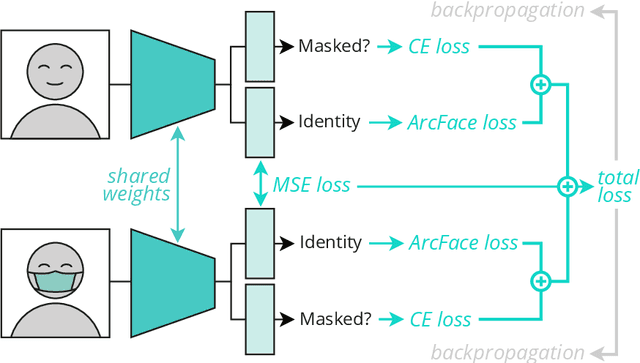

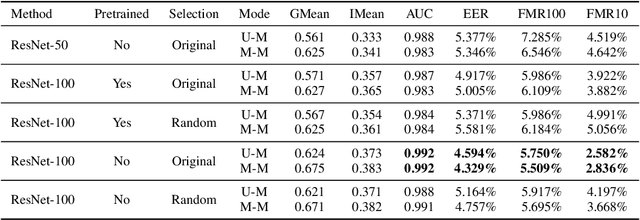
SARS-CoV-2 has presented direct and indirect challenges to the scientific community. One of the most prominent indirect challenges advents from the mandatory use of face masks in a large number of countries. Face recognition methods struggle to perform identity verification with similar accuracy on masked and unmasked individuals. It has been shown that the performance of these methods drops considerably in the presence of face masks, especially if the reference image is unmasked. We propose FocusFace, a multi-task architecture that uses contrastive learning to be able to accurately perform masked face recognition. The proposed architecture is designed to be trained from scratch or to work on top of state-of-the-art face recognition methods without sacrificing the capabilities of a existing models in conventional face recognition tasks. We also explore different approaches to design the contrastive learning module. Results are presented in terms of masked-masked (M-M) and unmasked-masked (U-M) face verification performance. For both settings, the results are on par with published methods, but for M-M specifically, the proposed method was able to outperform all the solutions that it was compared to. We further show that when using our method on top of already existing methods the training computational costs decrease significantly while retaining similar performances. The implementation and the trained models are available at GitHub.
My Eyes Are Up Here: Promoting Focus on Uncovered Regions in Masked Face Recognition
Aug 18, 2021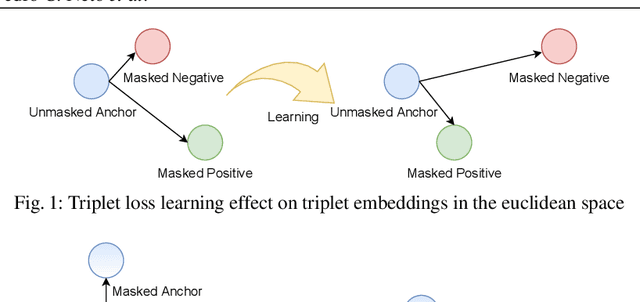
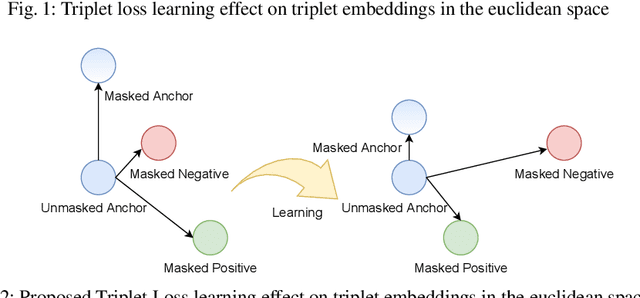

The recent Covid-19 pandemic and the fact that wearing masks in public is now mandatory in several countries, created challenges in the use of face recognition systems (FRS). In this work, we address the challenge of masked face recognition (MFR) and focus on evaluating the verification performance in FRS when verifying masked vs unmasked faces compared to verifying only unmasked faces. We propose a methodology that combines the traditional triplet loss and the mean squared error (MSE) intending to improve the robustness of an MFR system in the masked-unmasked comparison mode. The results obtained by our proposed method show improvements in a detailed step-wise ablation study. The conducted study showed significant performance gains induced by our proposed training paradigm and modified triplet loss on two evaluation databases.