 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models for Image Captioning: The Quirks and What Works
Oct 14, 2015
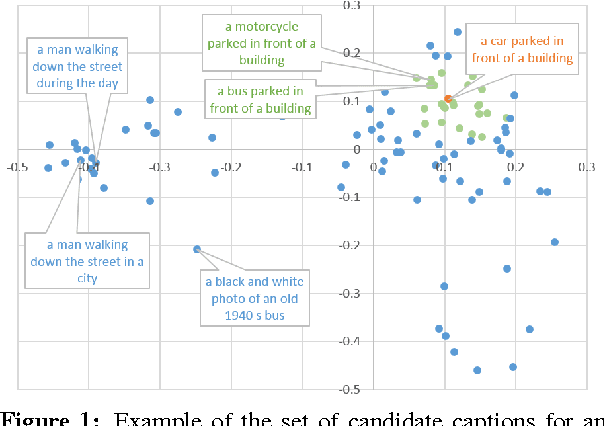

Two recent approaches have achieved state-of-the-art results in image captioning. The first uses a pipelined process where a set of candidate words is generated by a convolutional neural network (CNN) trained on images, and then a maximum entropy (ME) language model is used to arrange these words into a coherent sentence. The second uses the penultimate activation layer of the CNN as input to a recurrent neural network (RNN) that then generates the caption sequence. In this paper, we compare the merits of these different language modeling approaches for the first time by using the same state-of-the-art CNN as input. We examine issues in the different approaches, including linguistic irregularities, caption repetition, and data set overlap. By combining key aspects of the ME and RNN methods, we achieve a new record performance over previously published results on the benchmark COCO dataset. However, the gains we see in BLEU do not translate to human judgments.
A Survey of Current Datasets for Vision and Language Research
Aug 19, 2015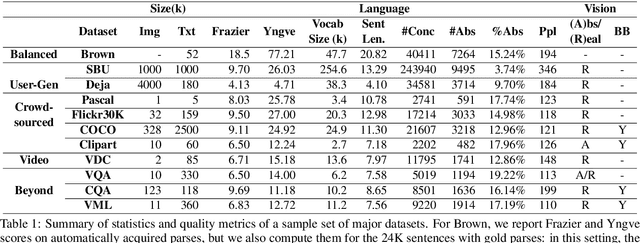
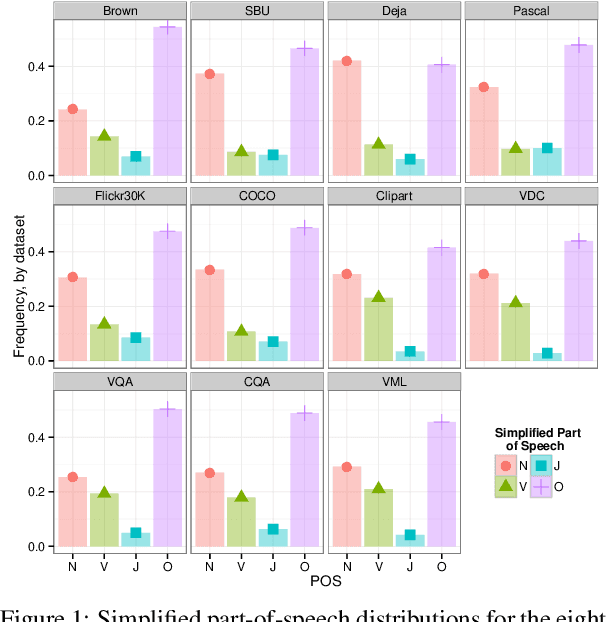
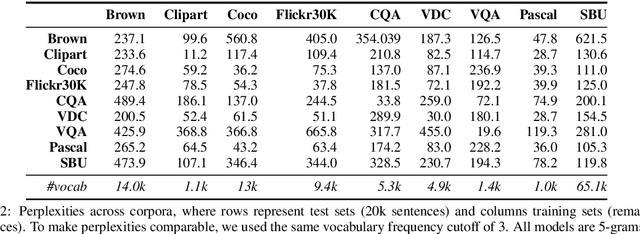
Integrating vision and language has long been a dream in work on artificial intelligence (AI). In the past two years, we have witnessed an explosion of work that brings together vision and language from images to videos and beyond. The available corpora have played a crucial role in advancing this area of research. In this paper, we propose a set of quality metrics for evaluating and analyzing the vision & language datasets and categorize them accordingly. Our analyses show that the most recent datasets have been using more complex language and more abstract concepts, however, there are different strengths and weaknesses in each.
Statistical Machine Translation Features with Multitask Tensor Networks
Jun 01, 2015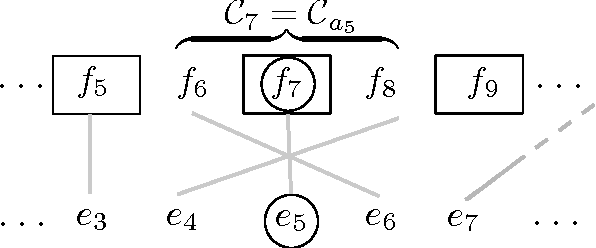
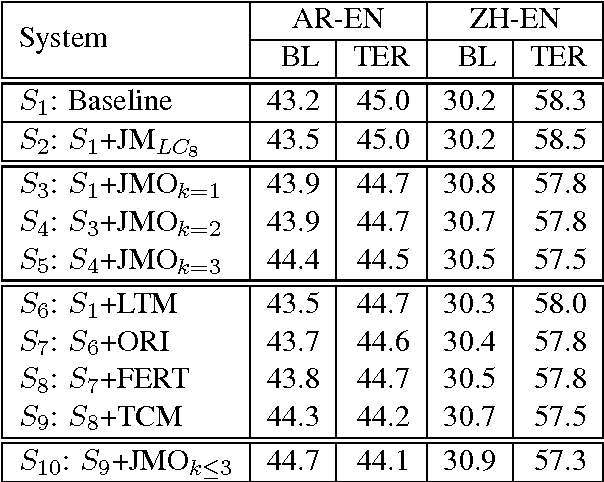
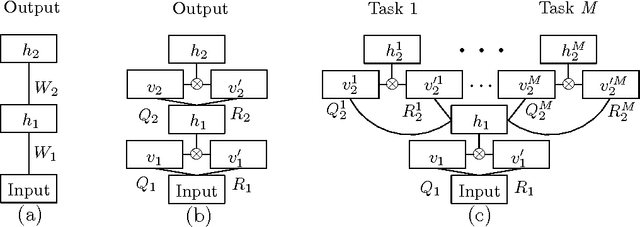
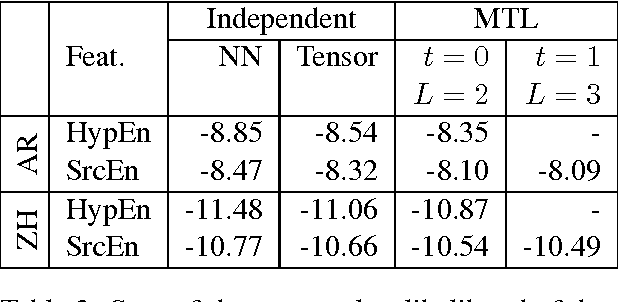
We present a three-pronged approach to improving Statistical Machine Translation (SMT), building on recent success in the application of neural networks to SMT. First, we propose new features based on neural networks to model various non-local translation phenomena. Second, we augment the architecture of the neural network with tensor layers that capture important higher-order interaction among the network units. Third, we apply multitask learning to estimate the neural network parameters jointly. Each of our proposed methods results in significant improvements that are complementary. The overall improvement is +2.7 and +1.8 BLEU points for Arabic-English and Chinese-English translation over a state-of-the-art system that already includes neural network features.
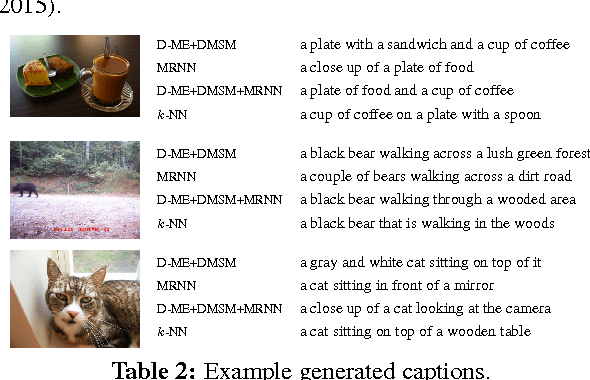
Exploring Nearest Neighbor Approaches for Image Captioning
May 17, 2015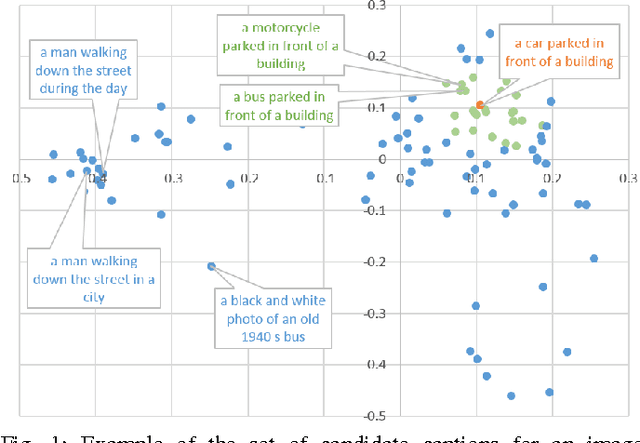
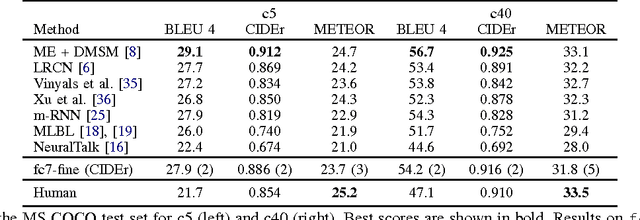

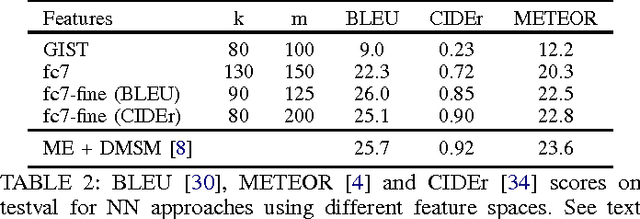
We explore a variety of nearest neighbor baseline approaches for image captioning. These approaches find a set of nearest neighbor images in the training set from which a caption may be borrowed for the query image. We select a caption for the query image by finding the caption that best represents the "consensus" of the set of candidate captions gathered from the nearest neighbor images. When measured by automatic evaluation metrics on the MS COCO caption evaluation server, these approaches perform as well as many recent approaches that generate novel captions. However, human studies show that a method that generates novel captions is still preferred over the nearest neighbor approach.