 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport on CHIIR 2026 Workshop on Generative AI and Academic Search (GAI&AS)
Jun 08, 2026This report summarizes the CHIIR 2026 Workshop on Generative AI and Academic Search (GAI\&AS), which examined how GenAI is reshaping academic search systems and research practices. The workshop brought together researchers in human information interaction and information retrieval to explore key challenges and opportunities in designing and evaluating future academic search systems that integrate GenAI, moving beyond traditional document retrieval to support summarization, recommendation, synthesis, and conversational interaction. Participants' interests and discussions focused on three thematic clusters: foundations and principles, applications and opportunities, and search-as-learning. Across these themes, the workshop highlighted the importance of academic search systems in supporting transparency, credibility, research integrity, and long-term scholarly needs, as well as in fostering higher-order cognitive processes. Participants discussed guiding theories, design principles, methodological approaches, partnerships, and community-building efforts aimed at advancing human-centered GenAI-enhanced academic search systems. Overall, the workshop demonstrated strong community interest and a diverse range of ongoing and emerging research initiatives at the intersection of GenAI and academic search.
SENSE: Efficient EEG-to-Text via Privacy-Preserving Semantic Retrieval
Mar 17, 2026Decoding brain activity into natural language is a major challenge in AI with important applications in assistive communication, neurotechnology, and human-computer interaction. Most existing Brain-Computer Interface (BCI) approaches rely on memory-intensive fine-tuning of Large Language Models (LLMs) or encoder-decoder models on raw EEG signals, resulting in expensive training pipelines, limited accessibility, and potential exposure of sensitive neural data. We introduce SENSE (SEmantic Neural Sparse Extraction), a lightweight and privacy-preserving framework that translates non-invasive electroencephalography (EEG) into text without LLM fine-tuning. SENSE decouples decoding into two stages: on-device semantic retrieval and prompt-based language generation. EEG signals are locally mapped to a discrete textual space to extract a non-sensitive Bag-of-Words (BoW), which conditions an off-the-shelf LLM to synthesize fluent text in a zero-shot manner. The EEG-to-keyword module contains only ~6M parameters and runs fully on-device, ensuring raw neural signals remain local while only abstract semantic cues interact with language models. Evaluated on a 128-channel EEG dataset across six subjects, SENSE matches or surpasses the generative quality of fully fine-tuned baselines such as Thought2Text while substantially reducing computational overhead. By localizing neural decoding and sharing only derived textual cues, SENSE provides a scalable and privacy-aware retrieval-augmented architecture for next-generation BCIs.
A Survey on Bridging EEG Signals and Generative AI: From Image and Text to Beyond
Feb 18, 2025Integration of Brain-Computer Interfaces (BCIs) and Generative Artificial Intelligence (GenAI) has opened new frontiers in brain signal decoding, enabling assistive communication, neural representation learning, and multimodal integration. BCIs, particularly those leveraging Electroencephalography (EEG), provide a non-invasive means of translating neural activity into meaningful outputs. Recent advances in deep learning, including Generative Adversarial Networks (GANs) and Transformer-based Large Language Models (LLMs), have significantly improved EEG-based generation of images, text, and speech. This paper provides a literature review of the state-of-the-art in EEG-based multimodal generation, focusing on (i) EEG-to-image generation through GANs, Variational Autoencoders (VAEs), and Diffusion Models, and (ii) EEG-to-text generation leveraging Transformer based language models and contrastive learning methods. Additionally, we discuss the emerging domain of EEG-to-speech synthesis, an evolving multimodal frontier. We highlight key datasets, use cases, challenges, and EEG feature encoding methods that underpin generative approaches. By providing a structured overview of EEG-based generative AI, this survey aims to equip researchers and practitioners with insights to advance neural decoding, enhance assistive technologies, and expand the frontiers of brain-computer interaction.
Exploring Multidimensional Checkworthiness: Designing AI-assisted Claim Prioritization for Human Fact-checkers
Dec 11, 2024Given the massive volume of potentially false claims circulating online, claim prioritization is essential in allocating limited human resources available for fact-checking. In this study, we perceive claim prioritization as an information retrieval (IR) task: just as multidimensional IR relevance, with many factors influencing which search results a user deems relevant, checkworthiness is also multi-faceted, subjective, and even personal, with many factors influencing how fact-checkers triage and select which claims to check. Our study investigates both the multidimensional nature of checkworthiness and effective tool support to assist fact-checkers in claim prioritization. Methodologically, we pursue Research through Design combined with mixed-method evaluation. We develop an AI-assisted claim prioritization prototype as a probe to explore how fact-checkers use multidimensional checkworthiness factors in claim prioritization, simultaneously probing fact-checker needs while also exploring the design space to meet those needs. Our study with 16 professional fact-checkers investigates: 1) how participants assessed the relative importance of different checkworthy dimensions and apply different priorities in claim selection; 2) how they created customized GPT-based search filters and the corresponding benefits and limitations; and 3) their overall user experiences with our prototype. Our work makes a conceptual contribution between multidimensional IR relevance and fact-checking checkworthiness, with findings demonstrating the value of corresponding tooling support. Specifically, we uncovered a hierarchical prioritization strategy fact-checkers implicitly use, revealing an underexplored aspect of their workflow, with actionable design recommendations for improving claim triage across multi-dimensional checkworthiness and tailoring this process with LLM integration.
Argumentative Experience: Reducing Confirmation Bias on Controversial Issues through LLM-Generated Multi-Persona Debates
Dec 10, 2024



Large language models (LLMs) are enabling designers to give life to exciting new user experiences for information access. In this work, we present a system that generates LLM personas to debate a topic of interest from different perspectives. How might information seekers use and benefit from such a system? Can centering information access around diverse viewpoints help to mitigate thorny challenges like confirmation bias in which information seekers over-trust search results matching existing beliefs? How do potential biases and hallucinations in LLMs play out alongside human users who are also fallible and possibly biased? Our study exposes participants to multiple viewpoints on controversial issues via a mixed-methods, within-subjects study. We use eye-tracking metrics to quantitatively assess cognitive engagement alongside qualitative feedback. Compared to a baseline search system, we see more creative interactions and diverse information-seeking with our multi-persona debate system, which more effectively reduces user confirmation bias and conviction toward their initial beliefs. Overall, our study contributes to the emerging design space of LLM-based information access systems, specifically investigating the potential of simulated personas to promote greater exposure to information diversity, emulate collective intelligence, and mitigate bias in information seeking.
Thought2Text: Text Generation from EEG Signal using Large Language Models (LLMs)
Oct 10, 2024



Decoding and expressing brain activity in a comprehensible form is a challenging frontier in AI. This paper presents Thought2Text, which uses instruction-tuned Large Language Models (LLMs) fine-tuned with EEG data to achieve this goal. The approach involves three stages: (1) training an EEG encoder for visual feature extraction, (2) fine-tuning LLMs on image and text data, enabling multimodal description generation, and (3) further fine-tuning on EEG embeddings to generate text directly from EEG during inference. Experiments on a public EEG dataset collected for six subjects with image stimuli demonstrate the efficacy of multimodal LLMs (LLaMa-v3, Mistral-v0.3, Qwen2.5), validated using traditional language generation evaluation metrics, GPT-4 based assessments, and evaluations by human expert. This approach marks a significant advancement towards portable, low-cost "thoughts-to-text" technology with potential applications in both neuroscience and natural language processing (NLP).
Interactions with Generative Information Retrieval Systems
Jul 16, 2024

At its core, information access and seeking is an interactive process. In existing search engines, interactions are limited to a few pre-defined actions, such as "requery", "click on a document", "scrolling up/down", "going to the next result page", "leaving the search engine", etc. A major benefit of moving towards generative IR systems is enabling users with a richer expression of information need and feedback and free-form interactions in natural language and beyond. In other words, the actions users take are no longer limited by the clickable links and buttons available on the search engine result page and users can express themselves freely through natural language. This can go even beyond natural language, through images, videos, gestures, and sensors using multi-modal generative IR systems. This chapter briefly discusses the role of interaction in generative IR systems. We will first discuss different ways users can express their information needs by interacting with generative IR systems. We then explain how users can provide explicit or implicit feedback to generative IR systems and how they can consume such feedback. Next, we will cover how users interactively can refine retrieval results. We will expand upon mixed-initiative interactions and discuss clarification and preference elicitation in more detail. We then discuss proactive generative IR systems, including context-aware recommendation, following up past conversations, contributing to multi-party conversations, and feedback requests. Providing explanation is another interaction type that we briefly discuss in this chapter. We will also briefly describe multi-modal interactions in generative information retrieval. Finally, we describe emerging frameworks and solutions for user interfaces with generative AI systems.
Using Explainable AI to Cross-Validate Socio-economic Disparities Among Covid-19 Patient Mortality
Feb 16, 2023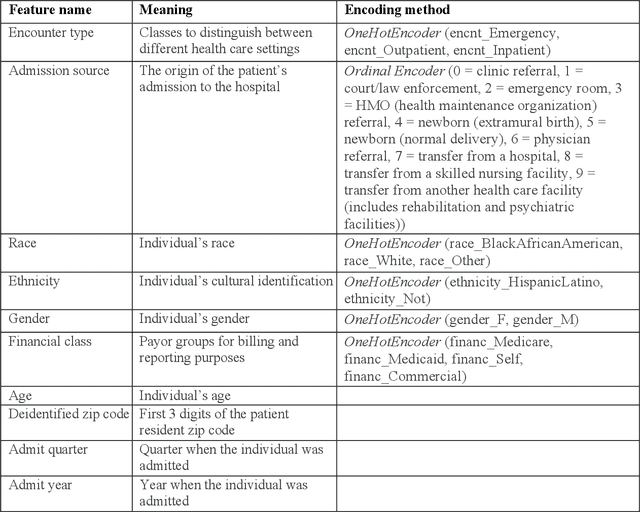
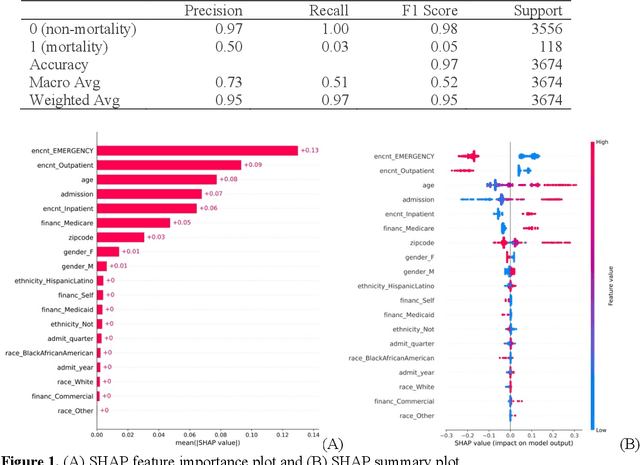


This paper applies eXplainable Artificial Intelligence (XAI) methods to investigate the socioeconomic disparities in COVID patient mortality. An Extreme Gradient Boosting (XGBoost) prediction model is built based on a de-identified Austin area hospital dataset to predict the mortality of COVID-19 patients. We apply two XAI methods, Shapley Additive exPlanations (SHAP) and Locally Interpretable Model Agnostic Explanations (LIME), to compare the global and local interpretation of feature importance. This paper demonstrates the advantages of using XAI which shows the feature importance and decisive capability. Furthermore, we use the XAI methods to cross-validate their interpretations for individual patients. The XAI models reveal that Medicare financial class, older age, and gender have high impact on the mortality prediction. We find that LIME local interpretation does not show significant differences in feature importance comparing to SHAP, which suggests pattern confirmation. This paper demonstrates the importance of XAI methods in cross-validation of feature attributions.
Relevance Prediction from Eye-movements Using Semi-interpretable Convolutional Neural Networks
Jan 15, 2020
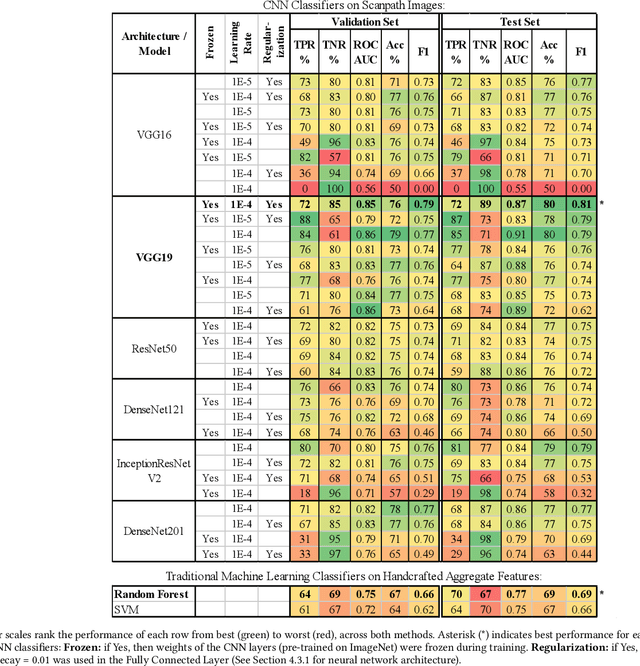
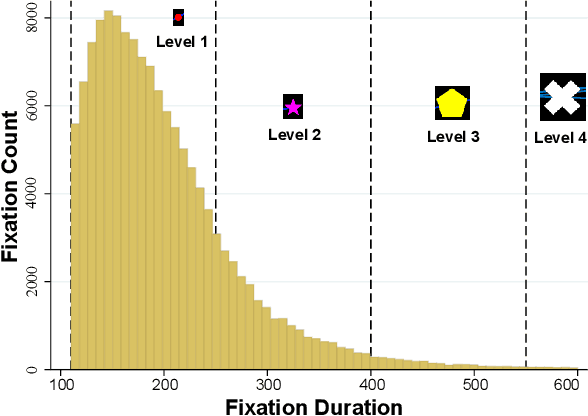
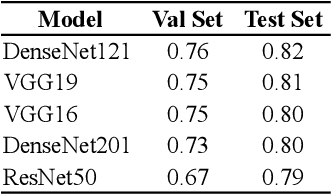
We propose an image-classification method to predict the perceived-relevance of text documents from eye-movements. An eye-tracking study was conducted where participants read short news articles, and rated them as relevant or irrelevant for answering a trigger question. We encode participants' eye-movement scanpaths as images, and then train a convolutional neural network classifier using these scanpath images. The trained classifier is used to predict participants' perceived-relevance of news articles from the corresponding scanpath images. This method is content-independent, as the classifier does not require knowledge of the screen-content, or the user's information-task. Even with little data, the image classifier can predict perceived-relevance with up to 80% accuracy. When compared to similar eye-tracking studies from the literature, this scanpath image classification method outperforms previously reported metrics by appreciable margins. We also attempt to interpret how the image classifier differentiates between scanpaths on relevant and irrelevant documents.
Relating Eye-Tracking Measures With Changes In Knowledge on Search Tasks
May 07, 2018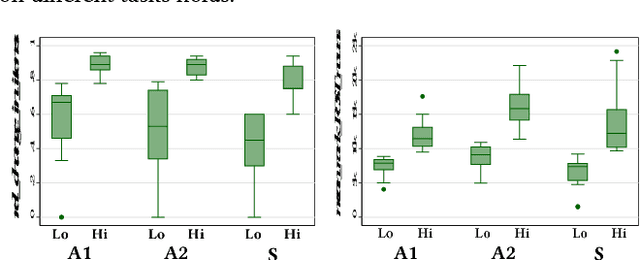

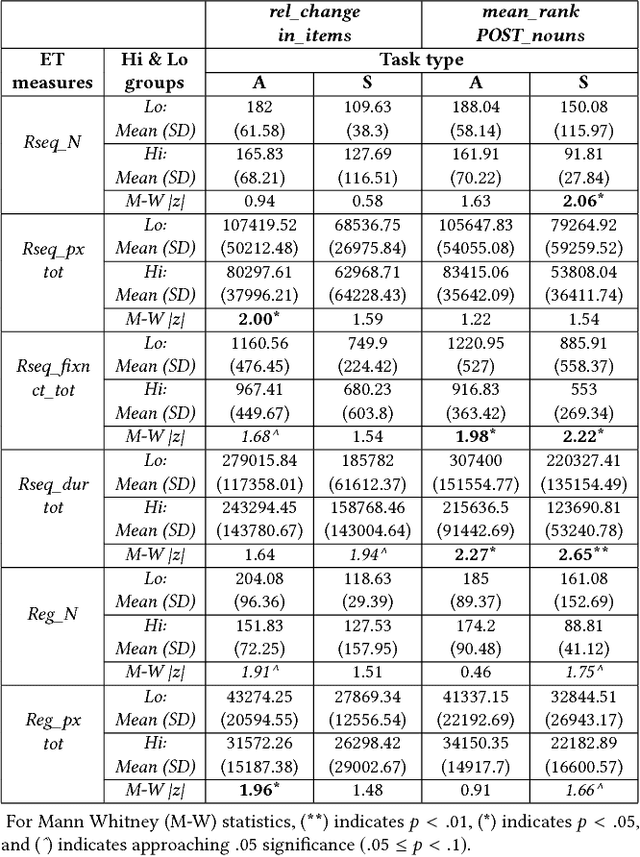
We conducted an eye-tracking study where 30 participants performed searches on the web. We measured their topical knowledge before and after each task. Their eye-fixations were labelled as "reading" or "scanning". The series of reading fixations in a line, called "reading-sequences" were characterized by their length in pixels, fixation duration, and the number of fixations making up the sequence. We hypothesize that differences in knowledge-change of participants are reflected in their eye-tracking measures related to reading. Our results show that the participants with higher change in knowledge differ significantly in terms of their total reading-sequence-length, reading-sequence-duration, and number of reading fixations, when compared to participants with lower knowledge-change.
* ACM Symposium on Eye Tracking Research and Applications (ETRA), June 14-17, 2018, Warsaw, Poland