 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep N-ary Error Correcting Output Codes
Oct 20, 2020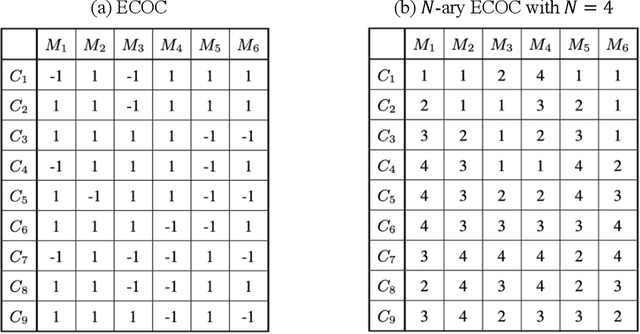
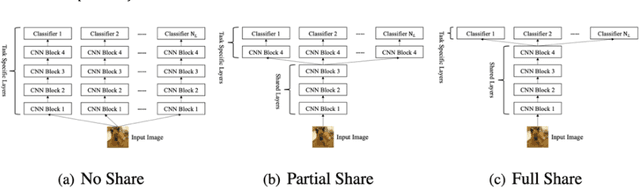
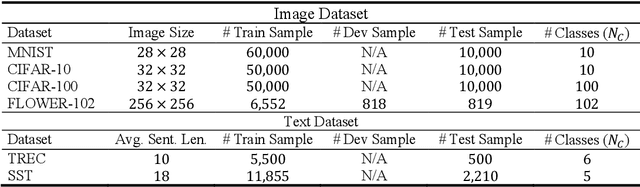
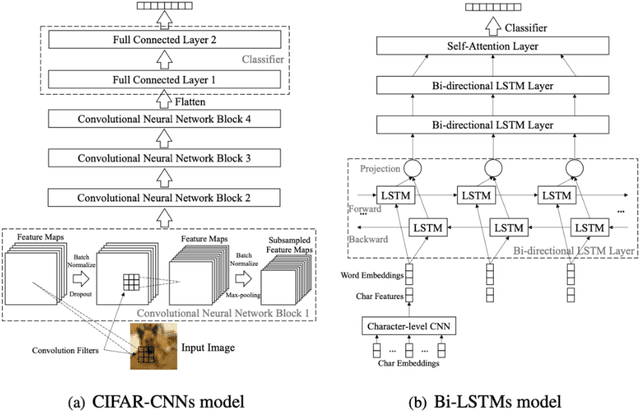
Ensemble learning consistently improves the performance of multi-class classification through aggregating a series of base classifiers. To this end, data-independent ensemble methods like Error Correcting Output Codes (ECOC) attract increasing attention due to its easiness of implementation and parallelization. Specifically, traditional ECOCs and its general extension N-ary ECOC decompose the original multi-class classification problem into a series of independent simpler classification subproblems. Unfortunately, integrating ECOCs, especially N-ary ECOC with deep neural networks, termed as deep N-ary ECOC, is not straightforward and yet fully exploited in the literature, due to the high expense of training base learners. To facilitate the training of N-ary ECOC with deep learning base learners, we further propose three different variants of parameter sharing architectures for deep N-ary ECOC. To verify the generalization ability of deep N-ary ECOC, we conduct experiments by varying the backbone with different deep neural network architectures for both image and text classification tasks. Furthermore, extensive ablation studies on deep N-ary ECOC show its superior performance over other deep data-independent ensemble methods.
Graph Cross Networks with Vertex Infomax Pooling
Oct 17, 2020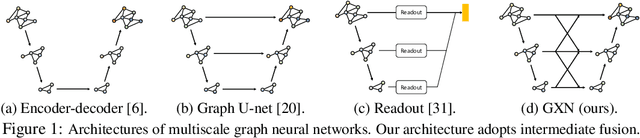
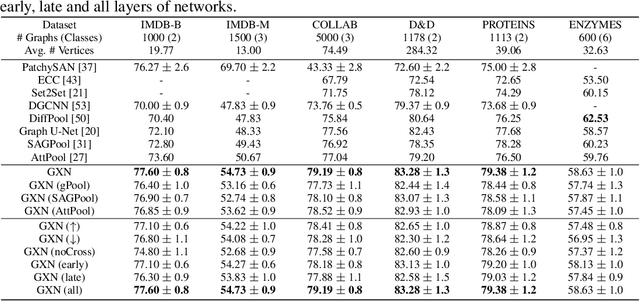
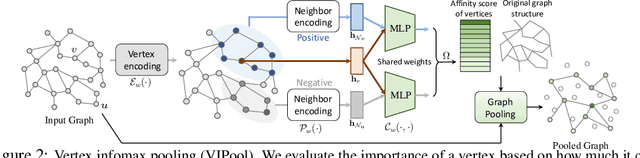
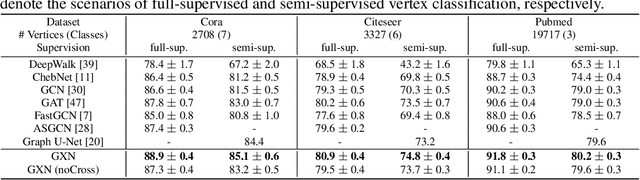
We propose a novel graph cross network (GXN) to achieve comprehensive feature learning from multiple scales of a graph. Based on trainable hierarchical representations of a graph, GXN enables the interchange of intermediate features across scales to promote information flow. Two key ingredients of GXN include a novel vertex infomax pooling (VIPool), which creates multiscale graphs in a trainable manner, and a novel feature-crossing layer, enabling feature interchange across scales. The proposed VIPool selects the most informative subset of vertices based on the neural estimation of mutual information between vertex features and neighborhood features. The intuition behind is that a vertex is informative when it can maximally reflect its neighboring information. The proposed feature-crossing layer fuses intermediate features between two scales for mutual enhancement by improving information flow and enriching multiscale features at hidden layers. The cross shape of the feature-crossing layer distinguishes GXN from many other multiscale architectures. Experimental results show that the proposed GXN improves the classification accuracy by 2.12% and 1.15% on average for graph classification and vertex classification, respectively. Based on the same network, the proposed VIPool consistently outperforms other graph-pooling methods.
Intrinsic Reward Driven Imitation Learning via Generative Model
Jul 09, 2020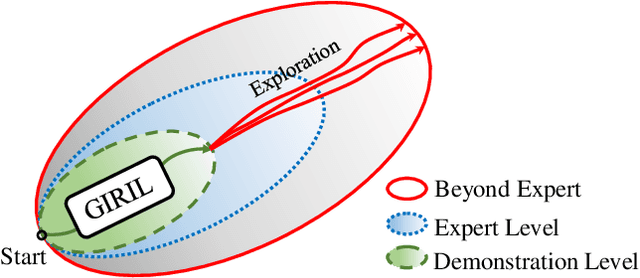
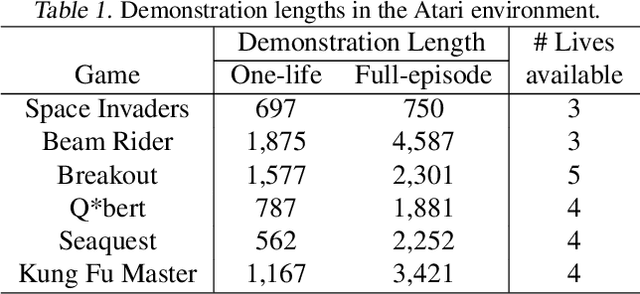
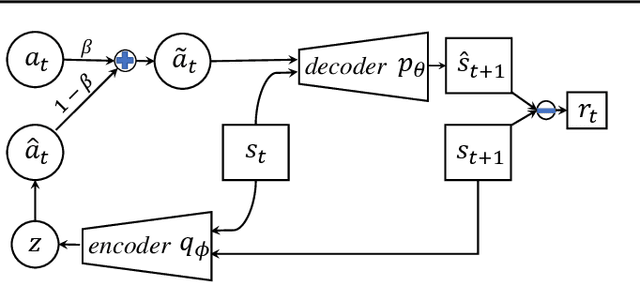

Imitation learning in a high-dimensional environment is challenging. Most inverse reinforcement learning (IRL) methods fail to outperform the demonstrator in such a high-dimensional environment, e.g., Atari domain. To address this challenge, we propose a novel reward learning module to generate intrinsic reward signals via a generative model. Our generative method can perform better forward state transition and backward action encoding, which improves the module's dynamics modeling ability in the environment. Thus, our module provides the imitation agent both the intrinsic intention of the demonstrator and a better exploration ability, which is critical for the agent to outperform the demonstrator. Empirical results show that our method outperforms state-of-the-art IRL methods on multiple Atari games, even with one-life demonstration. Remarkably, our method achieves performance that is up to 5 times the performance of the demonstration.
Multi-view Alignment and Generation in CCA via Consistent Latent Encoding
May 24, 2020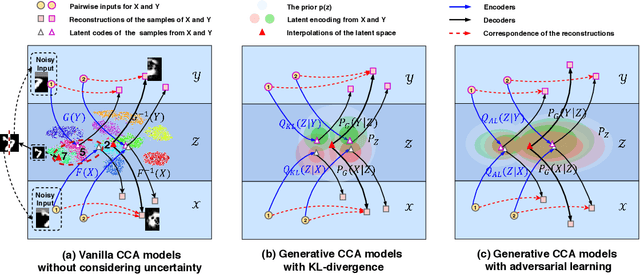
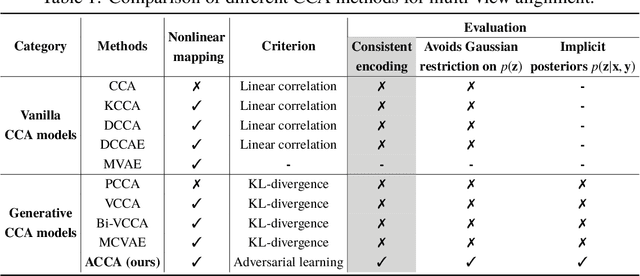
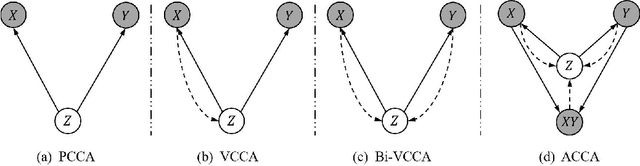
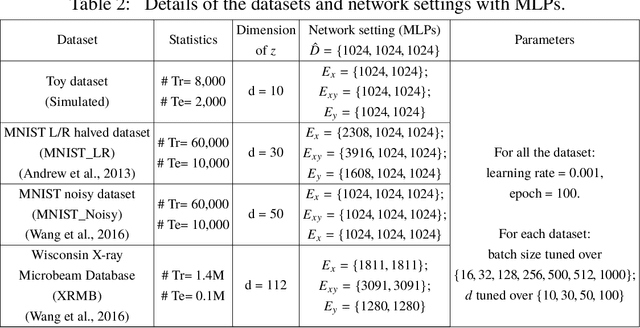
Multi-view alignment, achieving one-to-one correspondence of multi-view inputs, is critical in many real-world multi-view applications, especially for cross-view data analysis problems. Recently, an increasing number of works study this alignment problem with Canonical Correlation Analysis (CCA). However, existing CCA models are prone to misalign the multiple views due to either the neglect of uncertainty or the inconsistent encoding of the multiple views. To tackle these two issues, this paper studies multi-view alignment from the Bayesian perspective. Delving into the impairments of inconsistent encodings, we propose to recover correspondence of the multi-view inputs by matching the marginalization of the joint distribution of multi-view random variables under different forms of factorization. To realize our design, we present Adversarial CCA (ACCA) which achieves consistent latent encodings by matching the marginalized latent encodings through the adversarial training paradigm. Our analysis based on conditional mutual information reveals that ACCA is flexible for handling implicit distributions. Extensive experiments on correlation analysis and cross-view generation under noisy input settings demonstrate the superiority of our model.
Secure Metric Learning via Differential Pairwise Privacy
Mar 30, 2020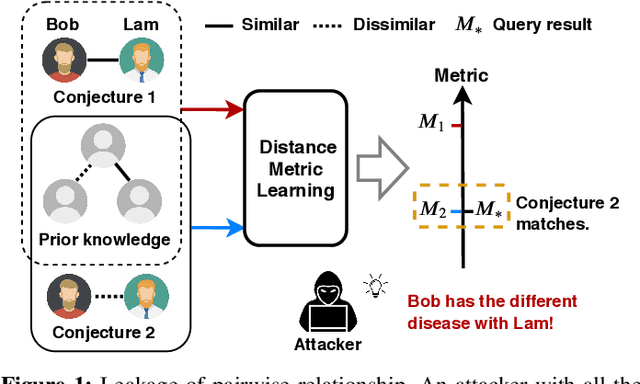
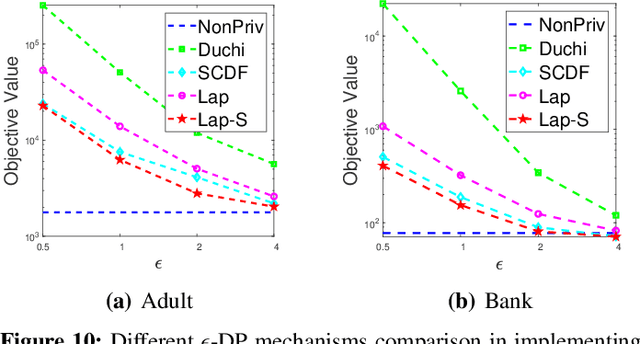
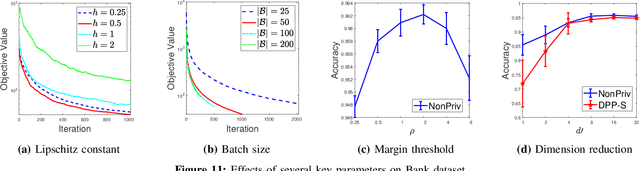
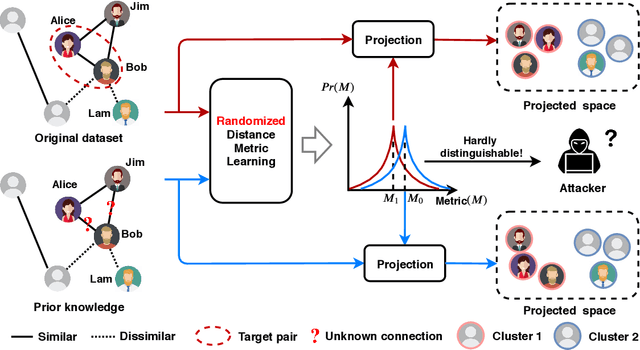
Distance Metric Learning (DML) has drawn much attention over the last two decades. A number of previous works have shown that it performs well in measuring the similarities of individuals given a set of correctly labeled pairwise data by domain experts. These important and precisely-labeled pairwise data are often highly sensitive in real world (e.g., patients similarity). This paper studies, for the first time, how pairwise information can be leaked to attackers during distance metric learning, and develops differential pairwise privacy (DPP), generalizing the definition of standard differential privacy, for secure metric learning. Unlike traditional differential privacy which only applies to independent samples, thus cannot be used for pairwise data, DPP successfully deals with this problem by reformulating the worst case. Specifically, given the pairwise data, we reveal all the involved correlations among pairs in the constructed undirected graph. DPP is then formalized that defines what kind of DML algorithm is private to preserve pairwise data. After that, a case study employing the contrastive loss is exhibited to clarify the details of implementing a DPP-DML algorithm. Particularly, the sensitivity reduction technique is proposed to enhance the utility of the output distance metric. Experiments both on a toy dataset and benchmarks demonstrate that the proposed scheme achieves pairwise data privacy without compromising the output performance much (Accuracy declines less than 0.01 throughout all benchmark datasets when the privacy budget is set at 4).
Face Hallucination with Finishing Touches
Feb 09, 2020



Obtaining a high-quality frontal face image from a low-resolution (LR) non-frontal face image is primarily important for many facial analysis applications. However, mainstreams either focus on super-resolving near-frontal LR faces or frontalizing non-frontal high-resolution (HR) faces. It is desirable to perform both tasks seamlessly for daily-life unconstrained face images. In this paper, we present a novel Vivid Face Hallucination Generative Adversarial Network (VividGAN) devised for simultaneously super-resolving and frontalizing tiny non-frontal face images. VividGAN consists of a Vivid Face Hallucination Network (Vivid-FHnet) and two discriminators, i.e., Coarse-D and Fine-D. The Vivid-FHnet first generates a coarse frontal HR face and then makes use of the structure prior, i.e., fine-grained facial components, to achieve a fine frontal HR face image. Specifically, we propose a facial component-aware module, which adopts the facial geometry guidance as clues to accurately align and merge the coarse frontal HR face and prior information. Meanwhile, the two-level discriminators are designed to capture both the global outline of the face as well as detailed facial characteristics. The Coarse-D enforces the coarse hallucinated faces to be upright and complete; while the Fine-D focuses on the fine hallucinated ones for sharper details. Extensive experiments demonstrate that our VividGAN achieves photo-realistic frontal HR faces, reaching superior performance in downstream tasks, i.e., face recognition and expression classification, compared with other state-of-the-art methods.
Towards Sharper First-Order Adversary with Quantized Gradients
Feb 01, 2020

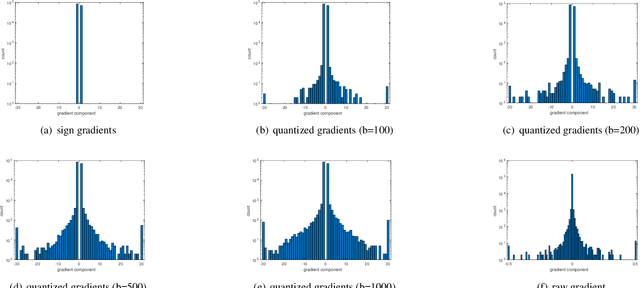

Despite the huge success of Deep Neural Networks (DNNs) in a wide spectrum of machine learning and data mining tasks, recent research shows that this powerful tool is susceptible to maliciously crafted adversarial examples. Up until now, adversarial training has been the most successful defense against adversarial attacks. To increase adversarial robustness, a DNN can be trained with a combination of benign and adversarial examples generated by first-order methods. However, in state-of-the-art first-order attacks, adversarial examples with sign gradients retain the sign information of each gradient component but discard the relative magnitude between components. In this work, we replace sign gradients with quantized gradients. Gradient quantization not only preserves the sign information, but also keeps the relative magnitude between components. Experiments show white-box first-order attacks with quantized gradients outperform their variants with sign gradients on multiple datasets. Notably, our BLOB\_QG attack achieves an accuracy of $88.32\%$ on the secret MNIST model from the MNIST Challenge and it outperforms all other methods on the leaderboard of white-box attacks.
Stochastic Implicit Natural Gradient for Black-box Optimization
Oct 09, 2019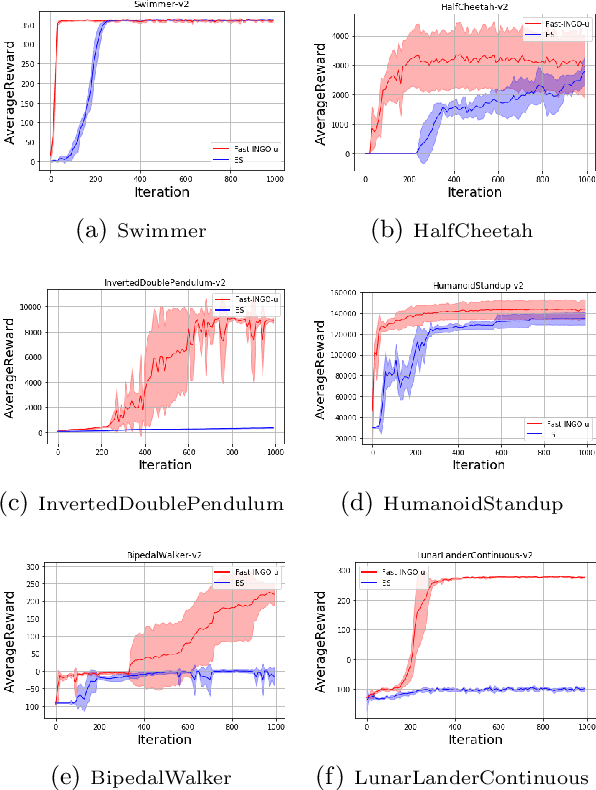
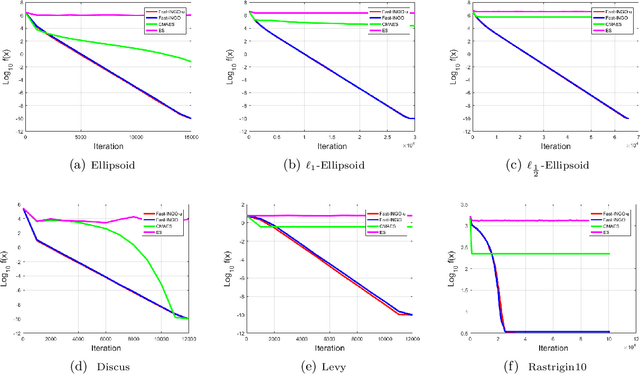
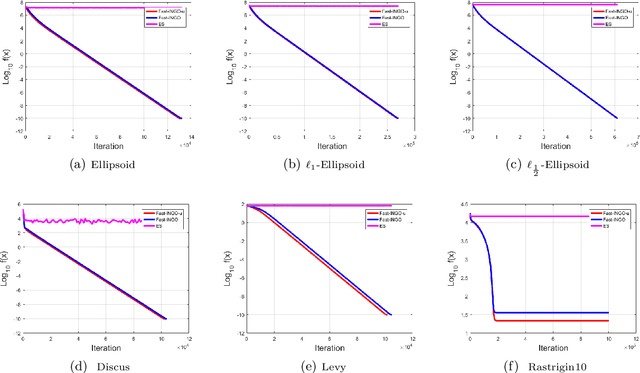
Black-box optimization is primarily important for many compute-intensive applications, including reinforcement learning (RL), robot control, etc. This paper presents a novel theoretical framework for black-box optimization, in which our method performs stochastic update within a trust region defined with KL-divergence. We show that this update is equivalent to a natural gradient step w.r.t. natural parameters of an exponential-family distribution. Theoretically, we prove the convergence rate of our framework for convex functions. Our theoretical results also hold for non-differentiable black-box functions. Empirically, our method achieves superior performance compared with the state-of-the-art method CMA-ES on separable benchmark test problems.
Improving Generalization via Attribute Selection on Out-of-the-box Data
Jul 26, 2019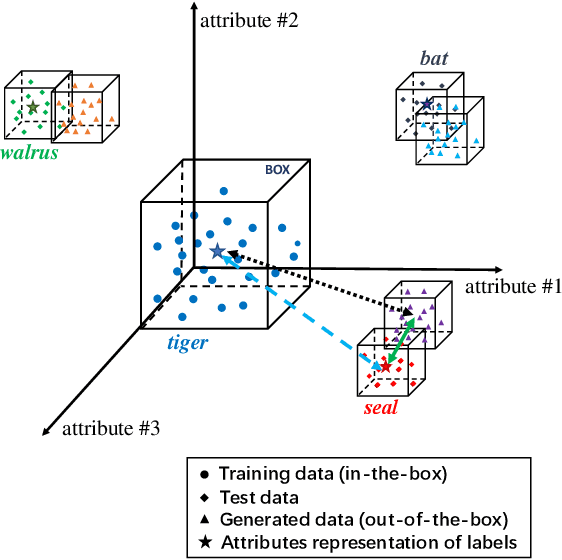
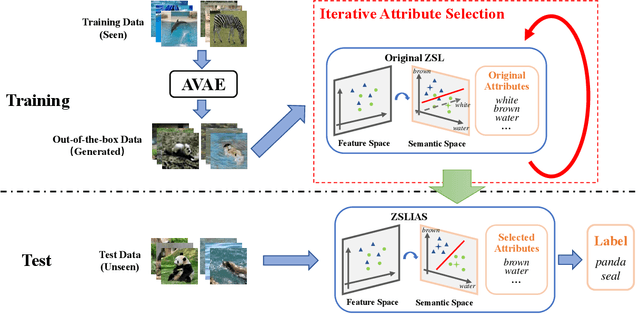
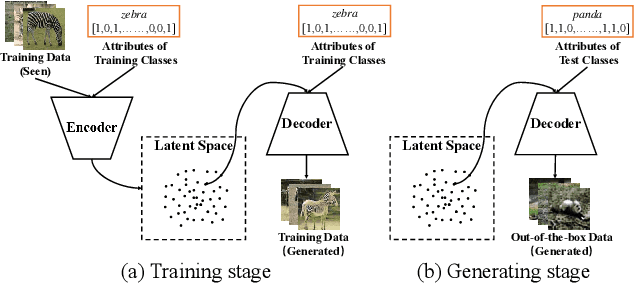

Zero-shot learning (ZSL) aims to recognize unseen objects (test classes) given some other seen objects (training classes), by sharing information of attributes between different objects. Attributes are artificially annotated for objects and are treated equally in recent ZSL tasks. However, some inferior attributes with poor predictability or poor discriminability may have negative impact on the ZSL system performance. This paper first derives a generalization error bound for ZSL tasks. Our theoretical analysis verifies that selecting key attributes set can improve the generalization performance of the original ZSL model which uses all the attributes. Unfortunately, previous attribute selection methods are conducted based on the seen data, their selected attributes have poor generalization capability to the unseen data, which is unavailable in training stage for ZSL tasks. Inspired by learning from pseudo relevance feedback, this paper introduces the out-of-the-box data, which is pseudo data generated by an attribute-guided generative model, to mimic the unseen data. After that, we present an iterative attribute selection (IAS) strategy which iteratively selects key attributes based on the out-of-the-box data. Since the distribution of the generated out-of-the-box data is similar to the test data, the key attributes selected by IAS can be effectively generalized to test data. Extensive experiments demonstrate that IAS can significantly improve existing attribute-based ZSL methods and achieve state-of-the-art performance.
Node Attribute Generation on Graphs
Jul 23, 2019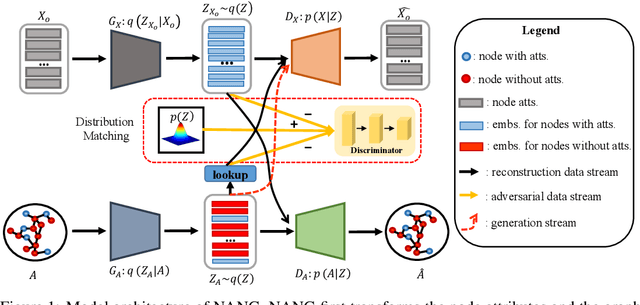
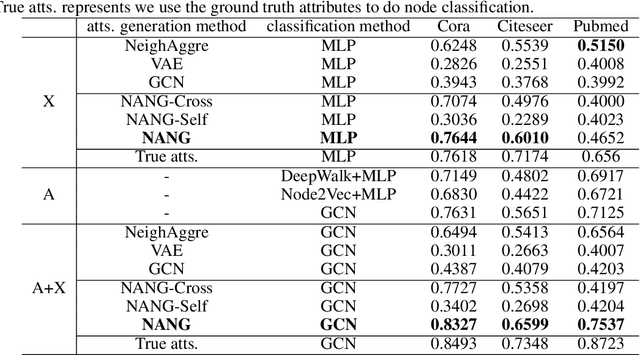
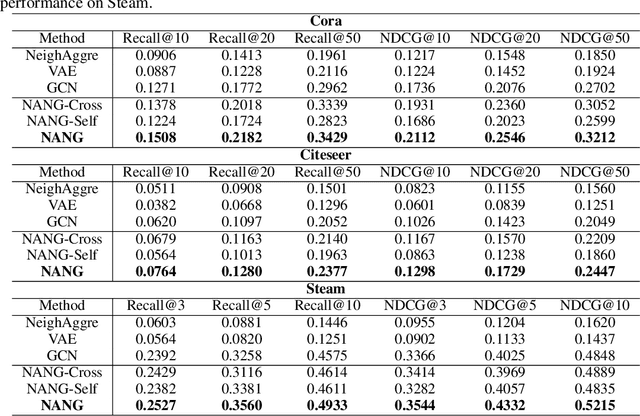
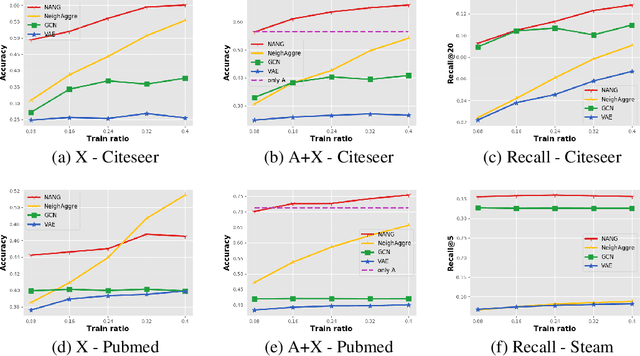
Graph structured data provide two-fold information: graph structures and node attributes. Numerous graph-based algorithms rely on both information to achieve success in supervised tasks, such as node classification and link prediction. However, node attributes could be missing or incomplete, which significantly deteriorates the performance. The task of node attribute generation aims to generate attributes for those nodes whose attributes are completely unobserved. This task benefits many real-world problems like profiling, node classification and graph data augmentation. To tackle this task, we propose a deep adversarial learning based method to generate node attributes; called node attribute neural generator (NANG). NANG learns a unifying latent representation which is shared by both node attributes and graph structures and can be translated to different modalities. We thus use this latent representation as a bridge to convert information from one modality to another. We further introduce practical applications to quantify the performance of node attribute generation. Extensive experiments are conducted on four real-world datasets and the empirical results show that node attributes generated by the proposed method are high-qualitative and beneficial to other applications. The datasets and codes are available online.