 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Loss: Robust Learning and Generalization against Label Corruption
Paper and Code
May 28, 2019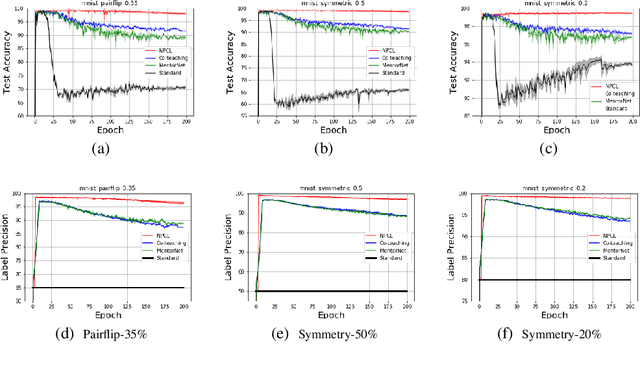

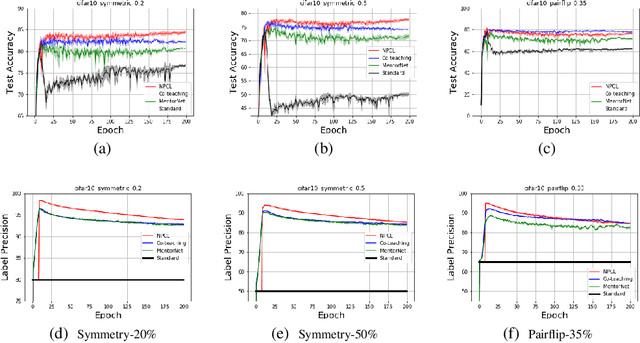
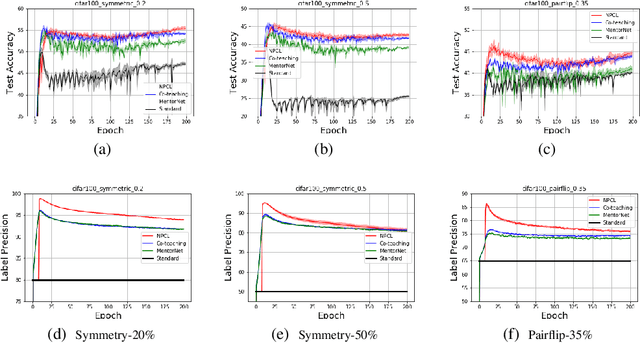
Generalization is vital important for many deep network models. It becomes more challenging when high robustness is required for learning with noisy labels. The 0-1 loss has monotonic relationship between empirical adversary (reweighted) risk, and it is robust to outliers. However, it is also difficult to optimize. To efficiently optimize 0-1 loss while keeping its robust properties, we propose a very simple and efficient loss, i.e. curriculum loss (CL). Our CL is a tighter upper bound of the 0-1 loss compared with conventional summation based surrogate losses. Moreover, CL can adaptively select samples for training as a curriculum learning. To handle large rate of noisy label corruption, we extend our curriculum loss to a more general form that can automatically prune the estimated noisy samples during training. Experimental results on noisy MNIST, CIFAR10 and CIFAR100 dataset validate the robustness of the proposed loss.