 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision
Apr 20, 2020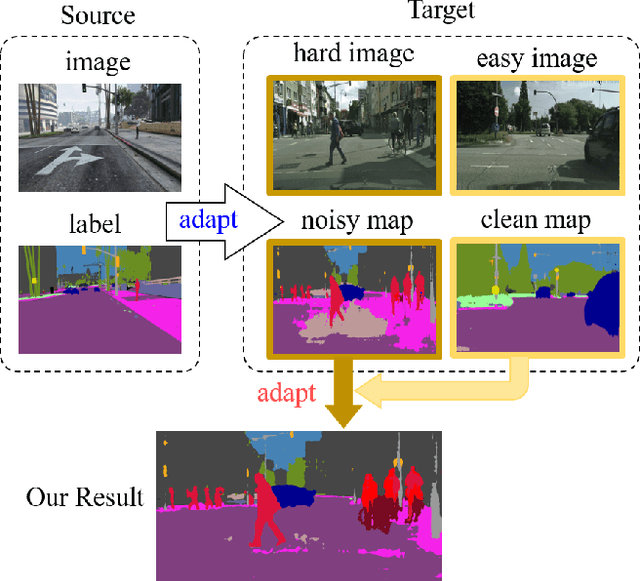
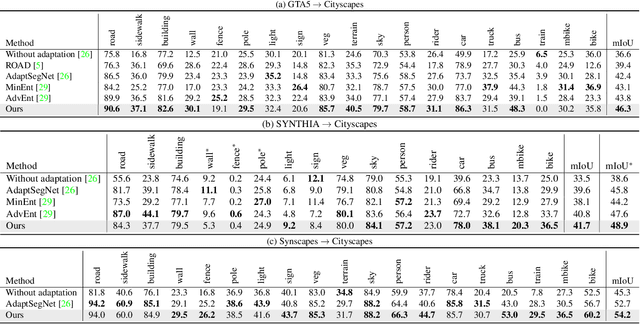
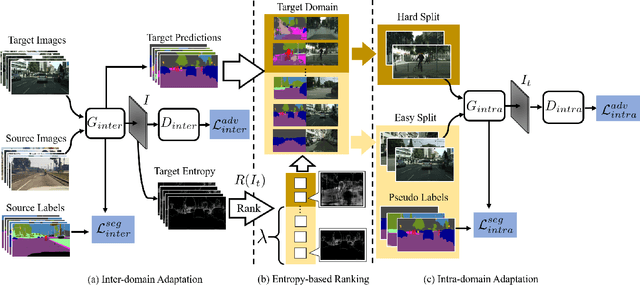

Convolutional neural network-based approaches have achieved remarkable progress in semantic segmentation. However, these approaches heavily rely on annotated data which are labor intensive. To cope with this limitation, automatically annotated data generated from graphic engines are used to train segmentation models. However, the models trained from synthetic data are difficult to transfer to real images. To tackle this issue, previous works have considered directly adapting models from the source data to the unlabeled target data (to reduce the inter-domain gap). Nonetheless, these techniques do not consider the large distribution gap among the target data itself (intra-domain gap). In this work, we propose a two-step self-supervised domain adaptation approach to minimize the inter-domain and intra-domain gap together. First, we conduct the inter-domain adaptation of the model; from this adaptation, we separate the target domain into an easy and hard split using an entropy-based ranking function. Finally, to decrease the intra-domain gap, we propose to employ a self-supervised adaptation technique from the easy to the hard split. Experimental results on numerous benchmark datasets highlight the effectiveness of our method against existing state-of-the-art approaches. The source code is available at https://github.com/feipan664/IntraDA.git.
Hide-and-Tell: Learning to Bridge Photo Streams for Visual Storytelling
Feb 03, 2020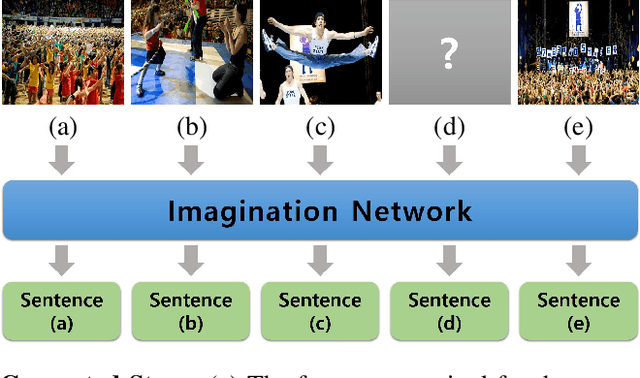
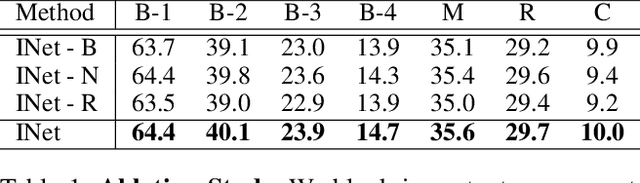
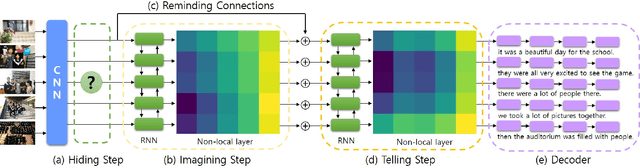
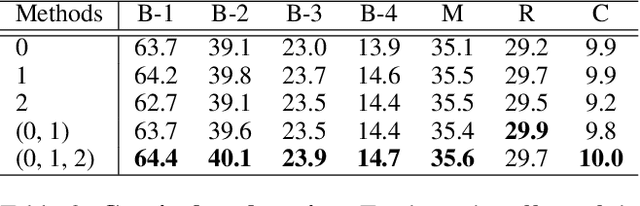
Visual storytelling is a task of creating a short story based on photo streams. Unlike existing visual captioning, storytelling aims to contain not only factual descriptions, but also human-like narration and semantics. However, the VIST dataset consists only of a small, fixed number of photos per story. Therefore, the main challenge of visual storytelling is to fill in the visual gap between photos with narrative and imaginative story. In this paper, we propose to explicitly learn to imagine a storyline that bridges the visual gap. During training, one or more photos is randomly omitted from the input stack, and we train the network to produce a full plausible story even with missing photo(s). Furthermore, we propose for visual storytelling a hide-and-tell model, which is designed to learn non-local relations across the photo streams and to refine and improve conventional RNN-based models. In experiments, we show that our scheme of hide-and-tell, and the network design are indeed effective at storytelling, and that our model outperforms previous state-of-the-art methods in automatic metrics. Finally, we qualitatively show the learned ability to interpolate storyline over visual gaps.
Fast Perception, Planning, and Execution for a Robotic Butler: Wheeled Humanoid M-Hubo
Jan 02, 2020
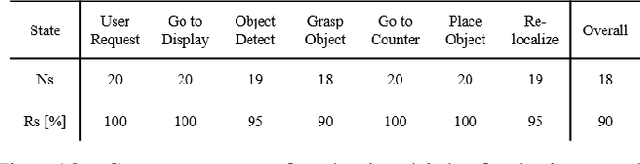
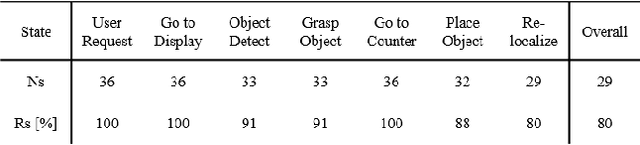
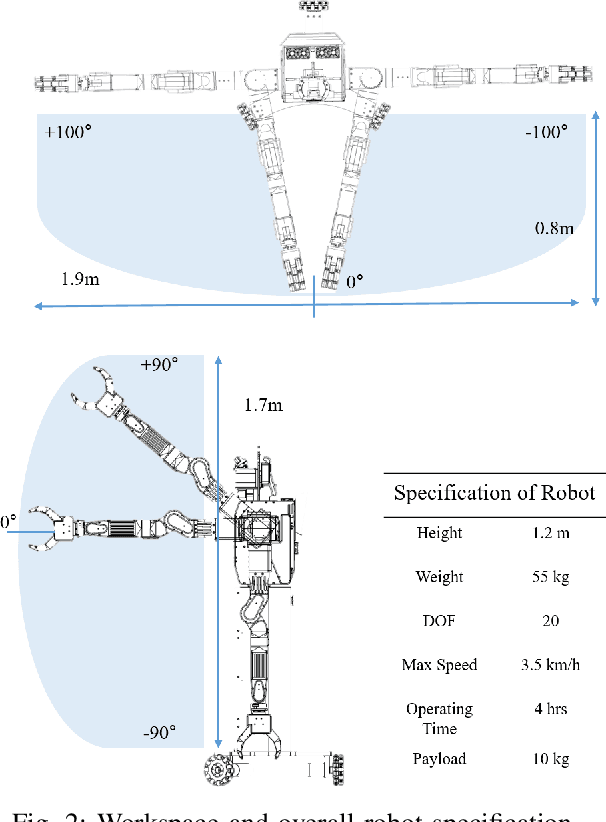
As the aging population grows at a rapid rate, there is an ever growing need for service robot platforms that can provide daily assistance at practical speed with reliable performance. In order to assist with daily tasks such as fetching a beverage, a service robot must be able to perceive its environment and generate corresponding motion trajectories. This becomes a challenging and computationally complex problem when the environment is unknown and thus the path planner must sample numerous trajectories that often are sub-optimal, extending the execution time. To address this issue, we propose a unique strategy of integrating a 3D object detection pipeline with a kinematically optimal manipulation planner to significantly increase speed performance at runtime. In addition, we develop a new robotic butler system for a wheeled humanoid that is capable of fetching requested objects at 24% of the speed a human needs to fulfill the same task. The proposed system was evaluated and demonstrated in a real-world environment setup as well as in public exhibition.
Instance-wise Depth and Motion Learning from Monocular Videos
Dec 19, 2019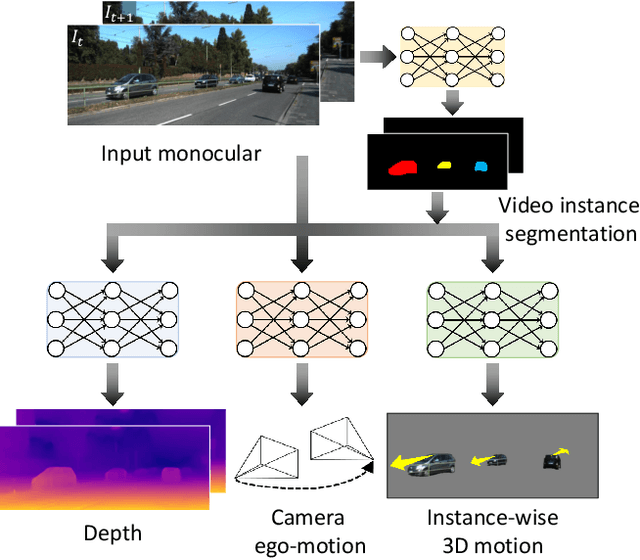
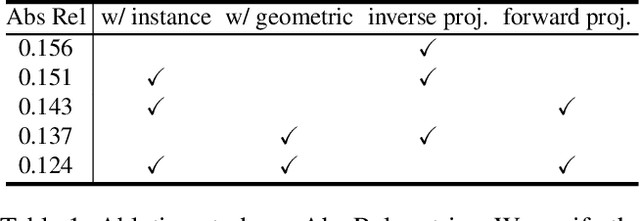
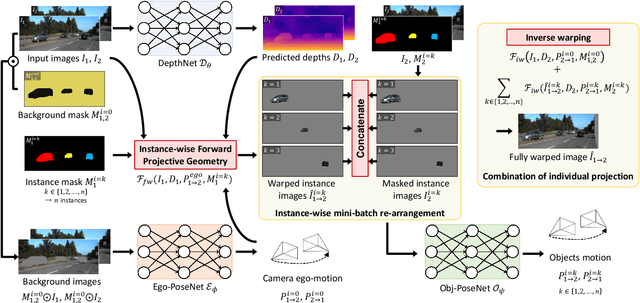
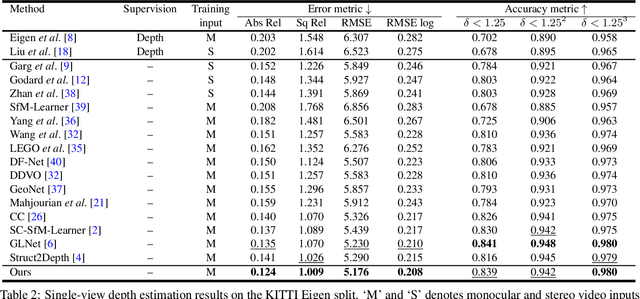
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. The only annotation used in our pipeline is a video instance segmentation map that can be predicted by our new auto-annotation scheme. Our technical contributions are three-fold. First, we propose a differentiable forward rigid projection module that plays a key role in our instance-wise depth and motion learning. Second, we design an instance-wise photometric and geometric consistency loss that effectively decomposes background and moving object regions. Lastly, we introduce an instance-wise mini-batch re-arrangement scheme that does not require additional iterations in training. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods.
Learning to Localize Sound Sources in Visual Scenes: Analysis and Applications
Nov 20, 2019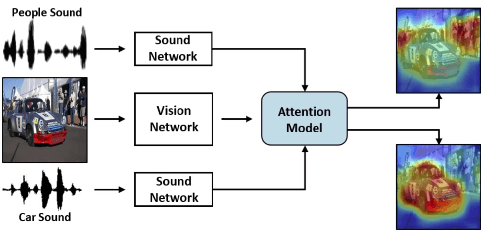
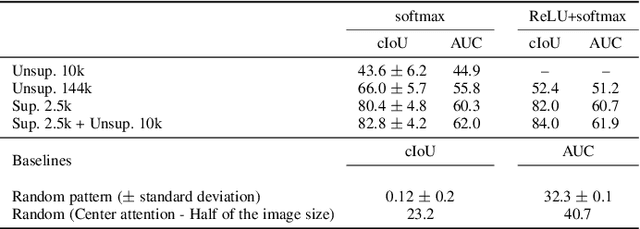
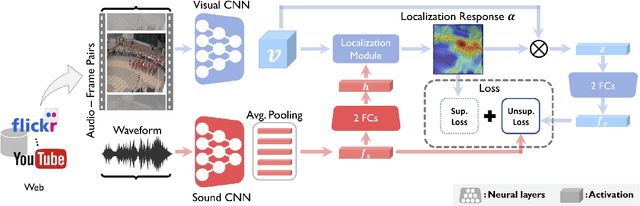
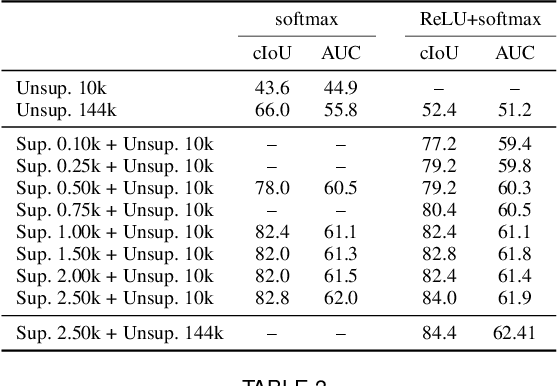
Visual events are usually accompanied by sounds in our daily lives. However, can the machines learn to correlate the visual scene and sound, as well as localize the sound source only by observing them like humans? To investigate its empirical learnability, in this work we first present a novel unsupervised algorithm to address the problem of localizing sound sources in visual scenes. In order to achieve this goal, a two-stream network structure which handles each modality with attention mechanism is developed for sound source localization. The network naturally reveals the localized response in the scene without human annotation. In addition, a new sound source dataset is developed for performance evaluation. Nevertheless, our empirical evaluation shows that the unsupervised method generates false conclusions in some cases. Thereby, we show that this false conclusion cannot be fixed without human prior knowledge due to the well-known correlation and causality mismatch misconception. To fix this issue, we extend our network to the supervised and semi-supervised network settings via a simple modification due to the general architecture of our two-stream network. We show that the false conclusions can be effectively corrected even with a small amount of supervision, i.e., semi-supervised setup. Furthermore, we present the versatility of the learned audio and visual embeddings on the cross-modal content alignment and we extend this proposed algorithm to a new application, sound saliency based automatic camera view panning in 360-degree{\deg} videos.
Learning Residual Flow as Dynamic Motion from Stereo Videos
Sep 16, 2019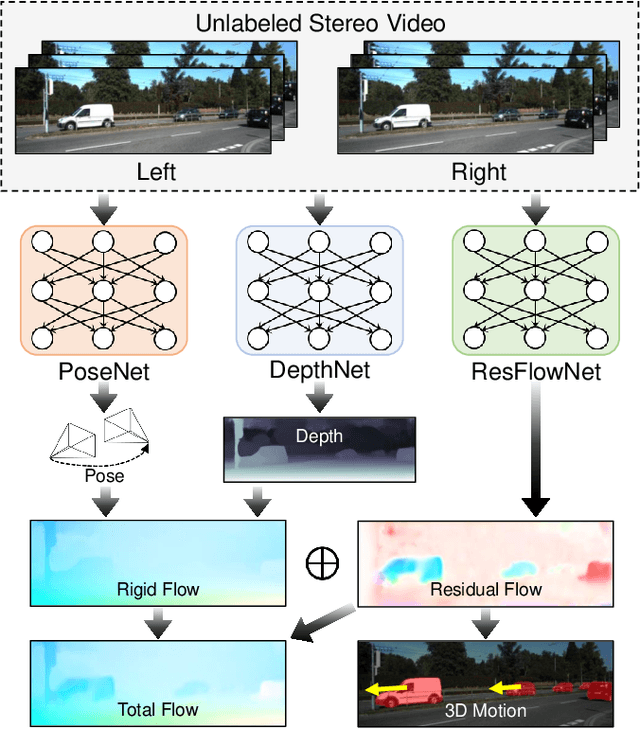
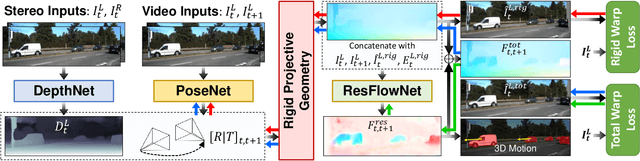
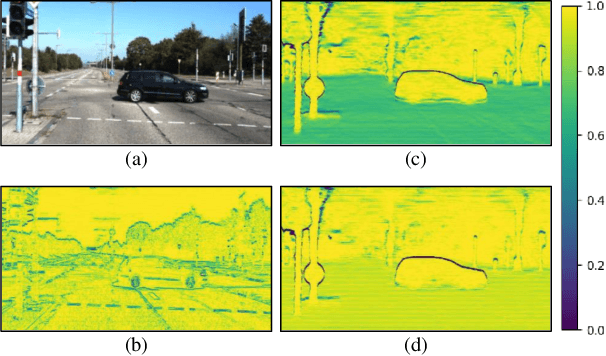
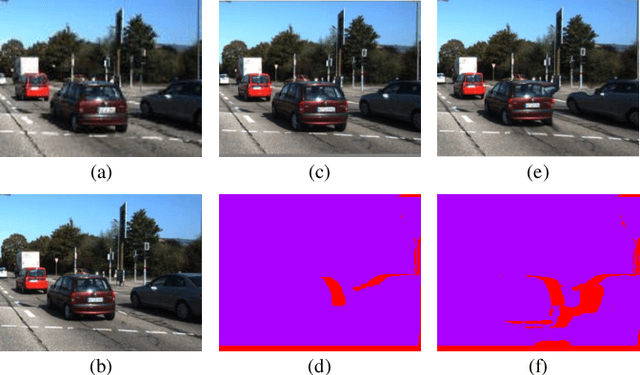
We present a method for decomposing the 3D scene flow observed from a moving stereo rig into stationary scene elements and dynamic object motion. Our unsupervised learning framework jointly reasons about the camera motion, optical flow, and 3D motion of moving objects. Three cooperating networks predict stereo matching, camera motion, and residual flow, which represents the flow component due to object motion and not from camera motion. Based on rigid projective geometry, the estimated stereo depth is used to guide the camera motion estimation, and the depth and camera motion are used to guide the residual flow estimation. We also explicitly estimate the 3D scene flow of dynamic objects based on the residual flow and scene depth. Experiments on the KITTI dataset demonstrate the effectiveness of our approach and show that our method outperforms other state-of-the-art algorithms on the optical flow and visual odometry tasks.
Visuomotor Understanding for Representation Learning of Driving Scenes
Sep 16, 2019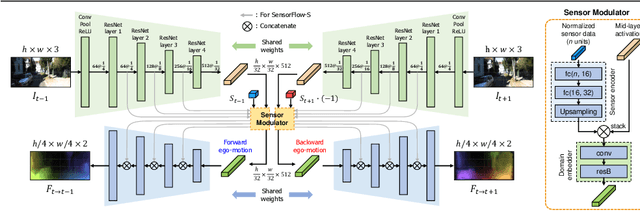
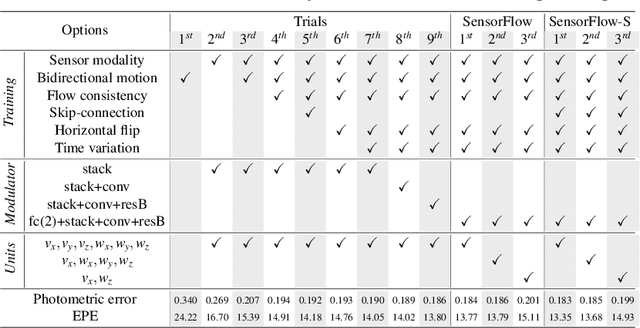
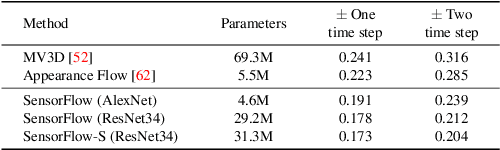
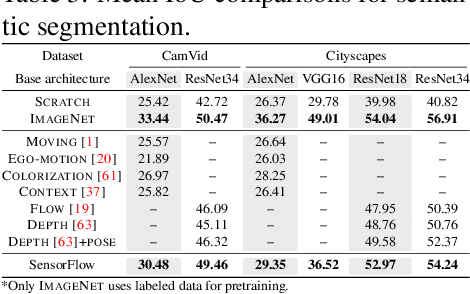
Dashboard cameras capture a tremendous amount of driving scene video each day. These videos are purposefully coupled with vehicle sensing data, such as from the speedometer and inertial sensors, providing an additional sensing modality for free. In this work, we leverage the large-scale unlabeled yet naturally paired data for visual representation learning in the driving scenario. A representation is learned in an end-to-end self-supervised framework for predicting dense optical flow from a single frame with paired sensing data. We postulate that success on this task requires the network to learn semantic and geometric knowledge in the ego-centric view. For example, forecasting a future view to be seen from a moving vehicle requires an understanding of scene depth, scale, and movement of objects. We demonstrate that our learned representation can benefit other tasks that require detailed scene understanding and outperforms competing unsupervised representations on semantic segmentation.
Deep Iterative Frame Interpolation for Full-frame Video Stabilization
Sep 05, 2019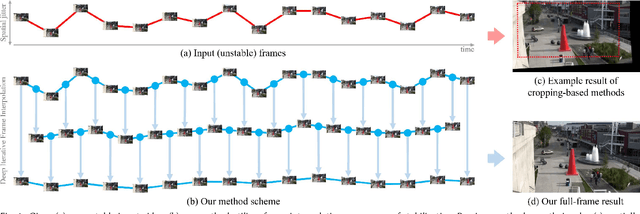

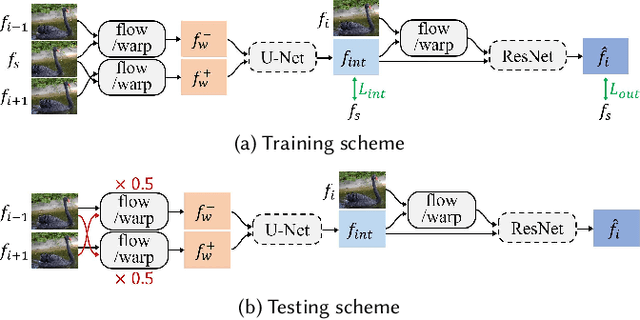

Video stabilization is a fundamental and important technique for higher quality videos. Prior works have extensively explored video stabilization, but most of them involve cropping of the frame boundaries and introduce moderate levels of distortion. We present a novel deep approach to video stabilization which can generate video frames without cropping and low distortion. The proposed framework utilizes frame interpolation techniques to generate in between frames, leading to reduced inter-frame jitter. Once applied in an iterative fashion, the stabilization effect becomes stronger. A major advantage is that our framework is end-to-end trainable in an unsupervised manner. In addition, our method is able to run in near real-time (15 fps). To the best of our knowledge, this is the first work to propose an unsupervised deep approach to full-frame video stabilization. We show the advantages of our method through quantitative and qualitative evaluations comparing to the state-of-the-art methods.
Image Captioning with Very Scarce Supervised Data: Adversarial Semi-Supervised Learning Approach
Sep 05, 2019
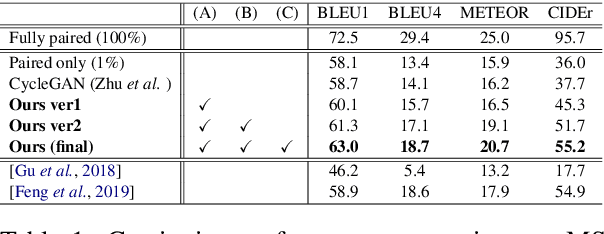
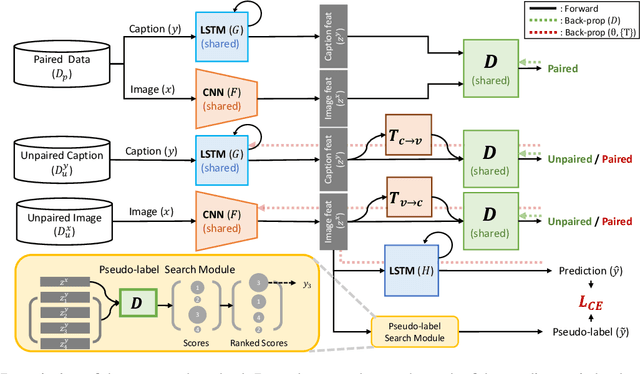

Constructing an organized dataset comprised of a large number of images and several captions for each image is a laborious task, which requires vast human effort. On the other hand, collecting a large number of images and sentences separately may be immensely easier. In this paper, we develop a novel data-efficient semi-supervised framework for training an image captioning model. We leverage massive unpaired image and caption data by learning to associate them. To this end, our proposed semi-supervised learning method assigns pseudo-labels to unpaired samples via Generative Adversarial Networks to learn the joint distribution of image and caption. To evaluate, we construct scarcely-paired COCO dataset, a modified version of MS COCO caption dataset. The empirical results show the effectiveness of our method compared to several strong baselines, especially when the amount of the paired samples are scarce.
Preserving Semantic and Temporal Consistency for Unpaired Video-to-Video Translation
Aug 21, 2019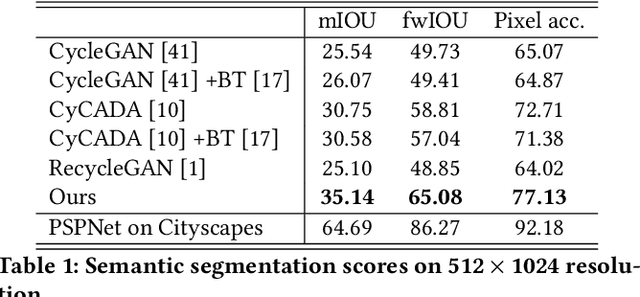
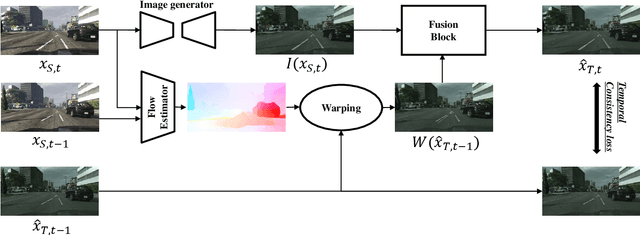

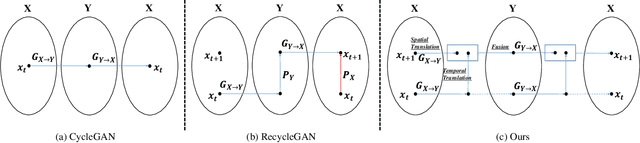
In this paper, we investigate the problem of unpaired video-to-video translation. Given a video in the source domain, we aim to learn the conditional distribution of the corresponding video in the target domain, without seeing any pairs of corresponding videos. While significant progress has been made in the unpaired translation of images, directly applying these methods to an input video leads to low visual quality due to the additional time dimension. In particular, previous methods suffer from semantic inconsistency (i.e., semantic label flipping) and temporal flickering artifacts. To alleviate these issues, we propose a new framework that is composed of carefully-designed generators and discriminators, coupled with two core objective functions: 1) content preserving loss and 2) temporal consistency loss. Extensive qualitative and quantitative evaluations demonstrate the superior performance of the proposed method against previous approaches. We further apply our framework to a domain adaptation task and achieve favorable results.