 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Augmentation and Adaptive CTC Fusion for Improved Robustness of Multi-Stream End-to-End ASR
Feb 05, 2021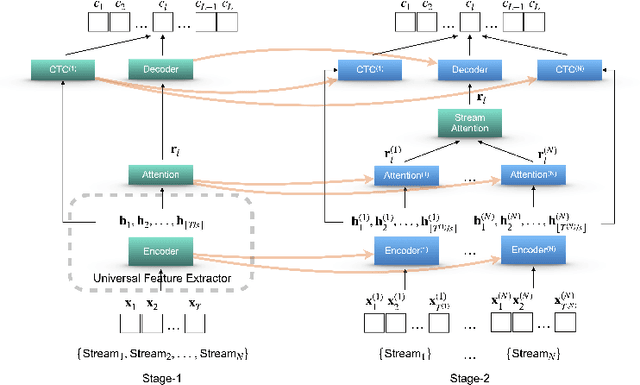

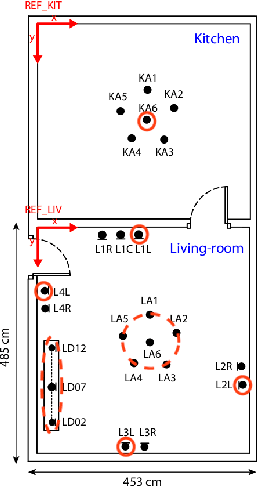

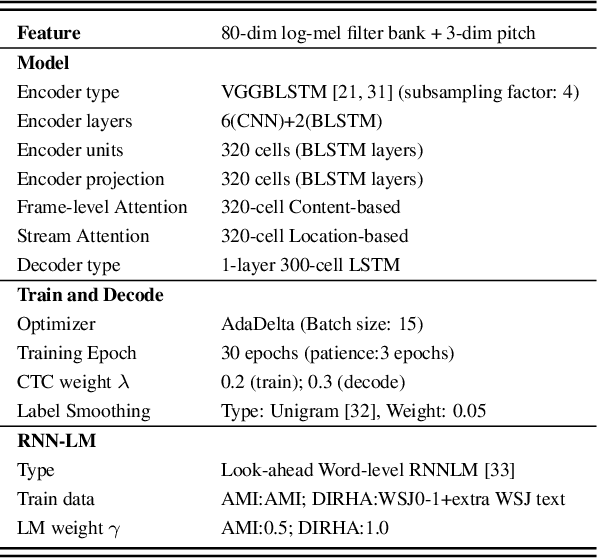
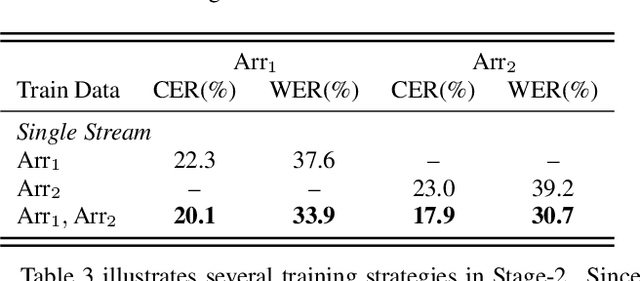
Performance degradation of an Automatic Speech Recognition (ASR) system is commonly observed when the test acoustic condition is different from training. Hence, it is essential to make ASR systems robust against various environmental distortions, such as background noises and reverberations. In a multi-stream paradigm, improving robustness takes account of handling a variety of unseen single-stream conditions and inter-stream dynamics. Previously, a practical two-stage training strategy was proposed within multi-stream end-to-end ASR, where Stage-2 formulates the multi-stream model with features from Stage-1 Universal Feature Extractor (UFE). In this paper, as an extension, we introduce a two-stage augmentation scheme focusing on mismatch scenarios: Stage-1 Augmentation aims to address single-stream input varieties with data augmentation techniques; Stage-2 Time Masking applies temporal masks on UFE features of randomly selected streams to simulate diverse stream combinations. During inference, we also present adaptive Connectionist Temporal Classification (CTC) fusion with the help of hierarchical attention mechanisms. Experiments have been conducted on two datasets, DIRHA and AMI, as a multi-stream scenario. Compared with the previous training strategy, substantial improvements are reported with relative word error rate reductions of 29.7-59.3% across several unseen stream combinations.
A practical two-stage training strategy for multi-stream end-to-end speech recognition
Oct 23, 2019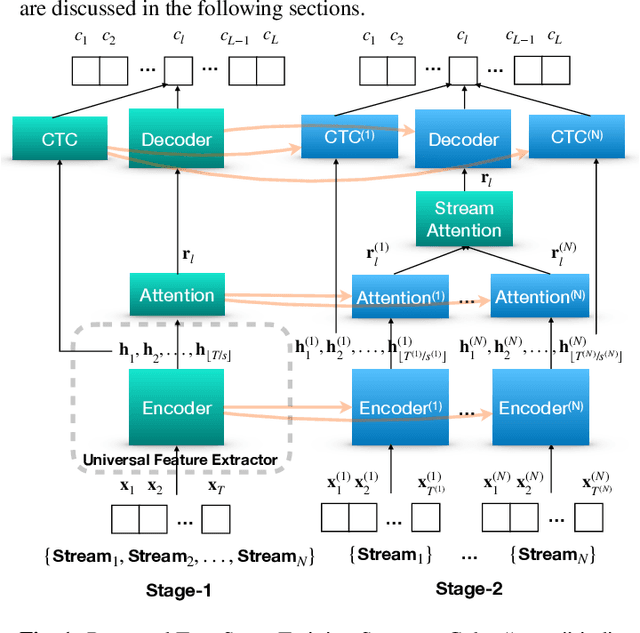
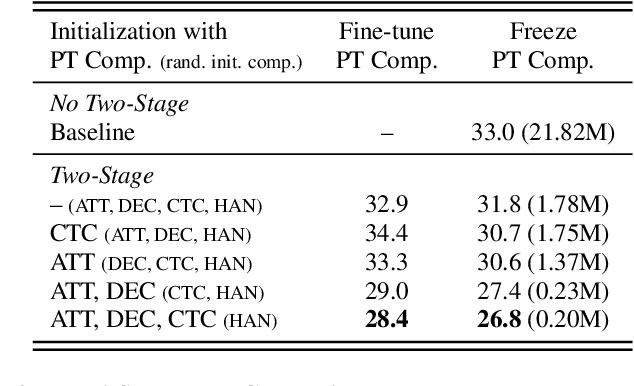
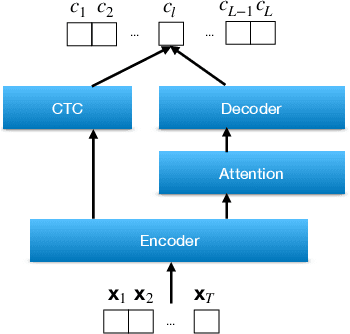
The multi-stream paradigm of audio processing, in which several sources are simultaneously considered, has been an active research area for information fusion. Our previous study offered a promising direction within end-to-end automatic speech recognition, where parallel encoders aim to capture diverse information followed by a stream-level fusion based on attention mechanisms to combine the different views. However, with an increasing number of streams resulting in an increasing number of encoders, the previous approach could require substantial memory and massive amounts of parallel data for joint training. In this work, we propose a practical two-stage training scheme. Stage-1 is to train a Universal Feature Extractor (UFE), where encoder outputs are produced from a single-stream model trained with all data. Stage-2 formulates a multi-stream scheme intending to solely train the attention fusion module using the UFE features and pretrained components from Stage-1. Experiments have been conducted on two datasets, DIRHA and AMI, as a multi-stream scenario. Compared with our previous method, this strategy achieves relative word error rate reductions of 8.2--32.4%, while consistently outperforming several conventional combination methods.
Performance Monitoring for End-to-End Speech Recognition
Apr 09, 2019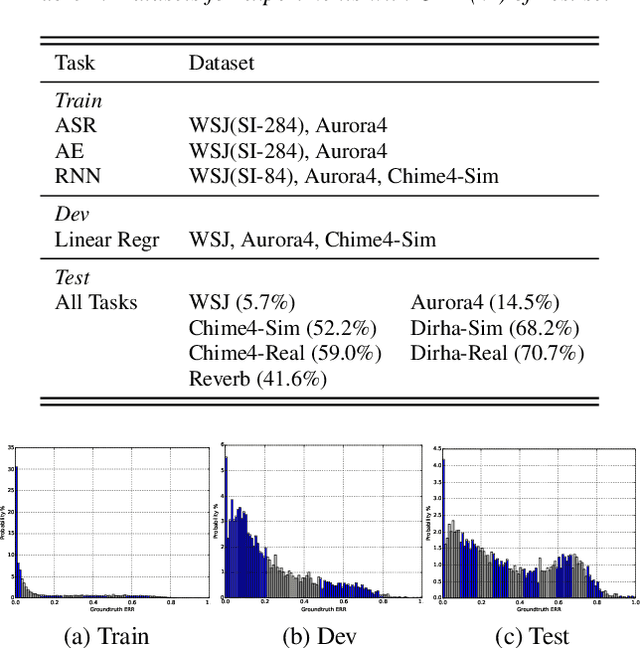
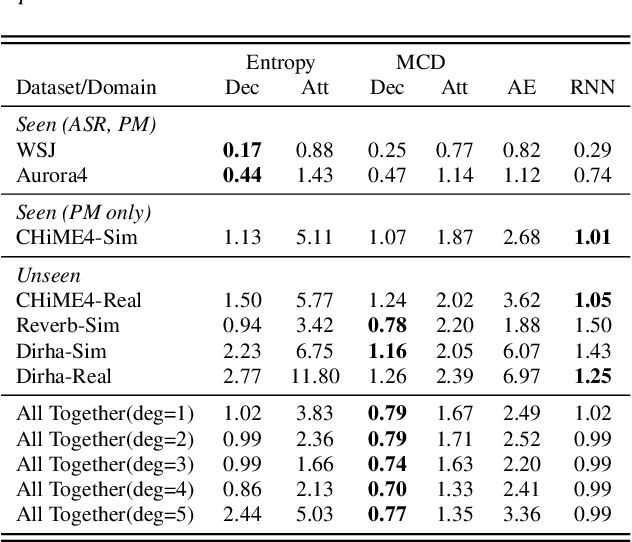
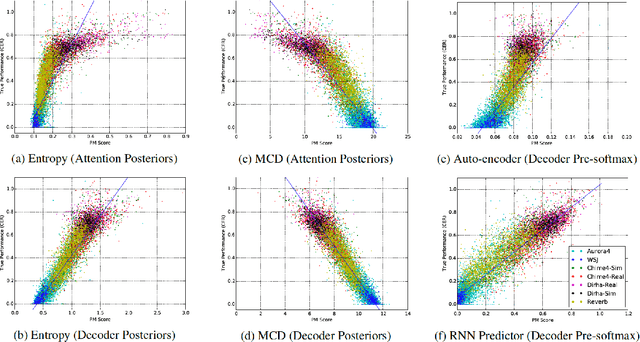
Measuring performance of an automatic speech recognition (ASR) system without ground-truth could be beneficial in many scenarios, especially with data from unseen domains, where performance can be highly inconsistent. In conventional ASR systems, several performance monitoring (PM) techniques have been well-developed to monitor performance by looking at tri-phone posteriors or pre-softmax activations from neural network acoustic modeling. However, strategies for monitoring more recently developed end-to-end ASR systems have not yet been explored, and so that is the focus of this paper. We adapt previous PM measures (Entropy, M-measure and Auto-encoder) and apply our proposed RNN predictor in the end-to-end setting. These measures utilize the decoder output layer and attention probability vectors, and their predictive power is measured with simple linear models. Our findings suggest that decoder-level features are more feasible and informative than attention-level probabilities for PM measures, and that M-measure on the decoder posteriors achieves the best overall predictive performance with an average prediction error 8.8%. Entropy measures and RNN-based prediction also show competitive predictability, especially for unseen conditions.
Building Corpora for Single-Channel Speech Separation Across Multiple Domains
Nov 06, 2018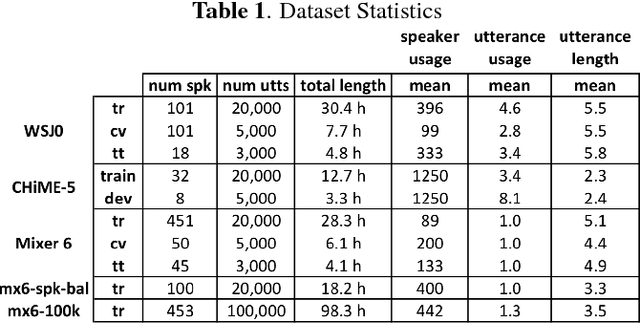
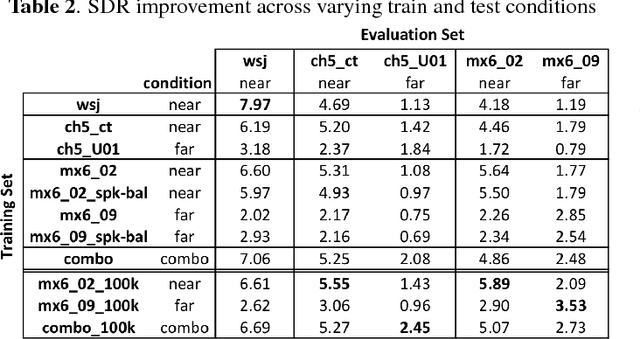
To date, the bulk of research on single-channel speech separation has been conducted using clean, near-field, read speech, which is not representative of many modern applications. In this work, we develop a procedure for constructing high-quality synthetic overlap datasets, necessary for most deep learning-based separation frameworks. We produced datasets that are more representative of realistic applications using the CHiME-5 and Mixer 6 corpora and evaluate standard methods on this data to demonstrate the shortcomings of current source-separation performance. We also demonstrate the value of a wide variety of data in training robust models that generalize well to multiple conditions.
Scalable Out-of-Sample Extension of Graph Embeddings Using Deep Neural Networks
Jun 14, 2016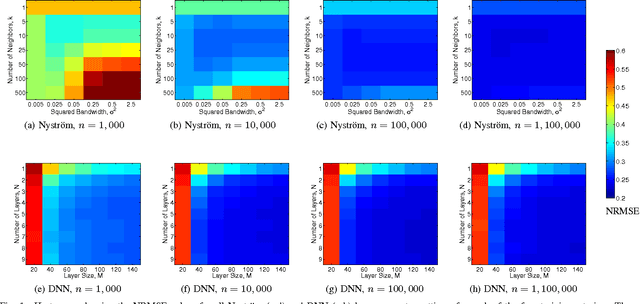
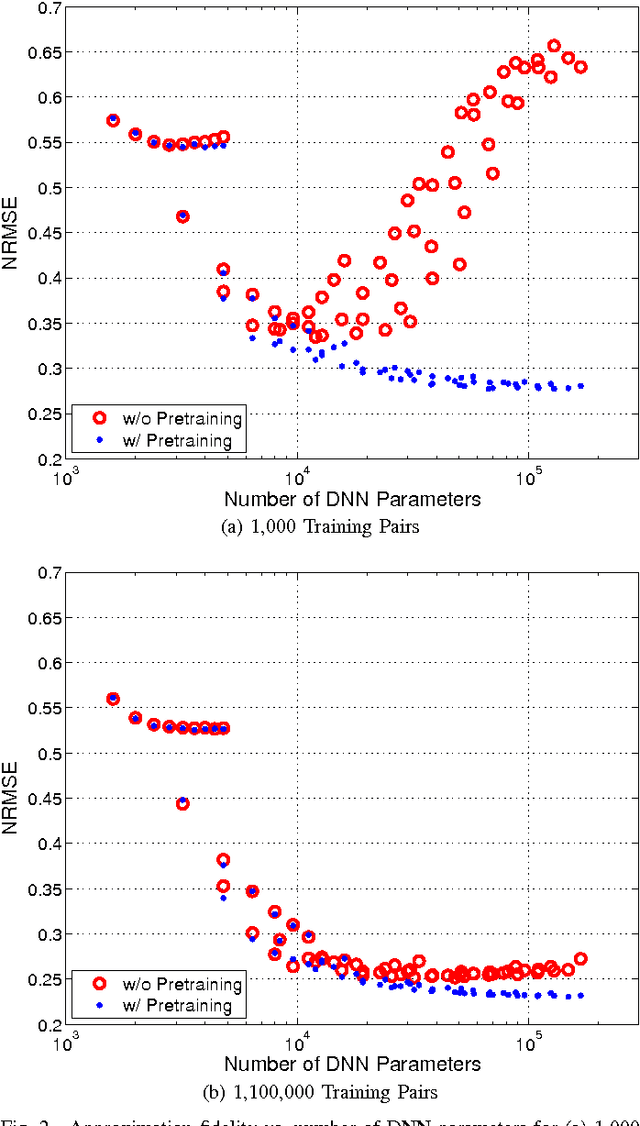
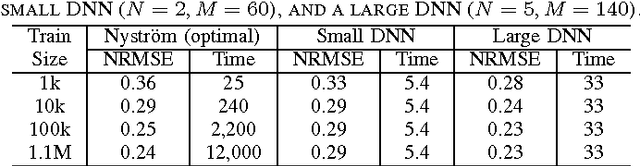
Several popular graph embedding techniques for representation learning and dimensionality reduction rely on performing computationally expensive eigendecompositions to derive a nonlinear transformation of the input data space. The resulting eigenvectors encode the embedding coordinates for the training samples only, and so the embedding of novel data samples requires further costly computation. In this paper, we present a method for the out-of-sample extension of graph embeddings using deep neural networks (DNN) to parametrically approximate these nonlinear maps. Compared with traditional nonparametric out-of-sample extension methods, we demonstrate that the DNNs can generalize with equal or better fidelity and require orders of magnitude less computation at test time. Moreover, we find that unsupervised pretraining of the DNNs improves optimization for larger network sizes, thus removing sensitivity to model selection.