 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeATrans: Learning Segmentation-Assisted diagnosis model via Transformer
Jun 22, 2022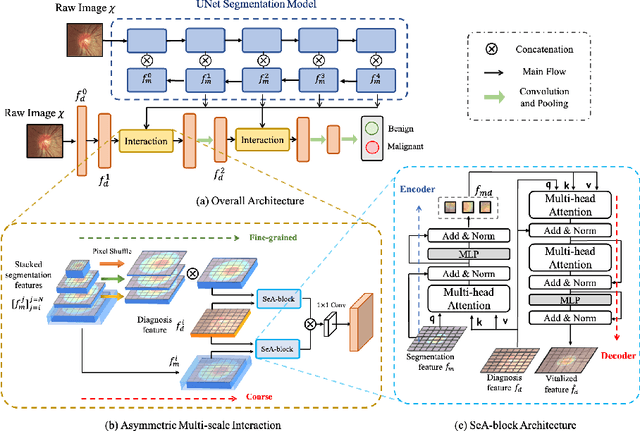
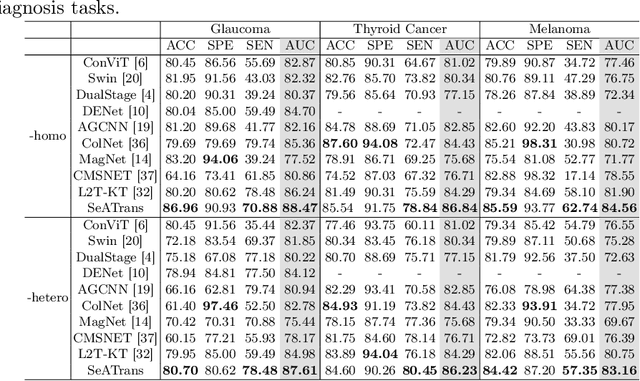
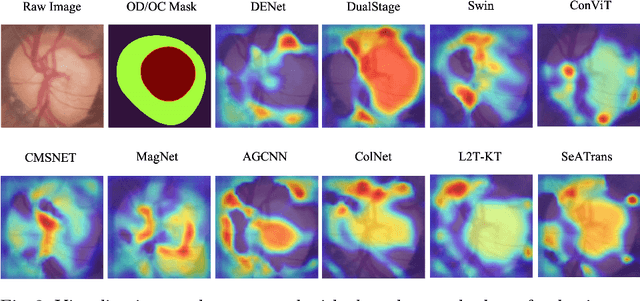
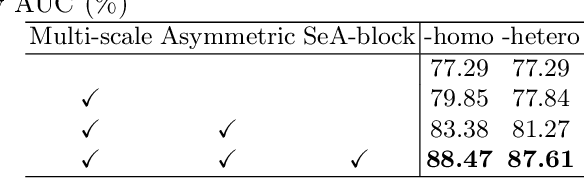
Clinically, the accurate annotation of lesions/tissues can significantly facilitate the disease diagnosis. For example, the segmentation of optic disc/cup (OD/OC) on fundus image would facilitate the glaucoma diagnosis, the segmentation of skin lesions on dermoscopic images is helpful to the melanoma diagnosis, etc. With the advancement of deep learning techniques, a wide range of methods proved the lesions/tissues segmentation can also facilitate the automated disease diagnosis models. However, existing methods are limited in the sense that they can only capture static regional correlations in the images. Inspired by the global and dynamic nature of Vision Transformer, in this paper, we propose Segmentation-Assisted diagnosis Transformer (SeATrans) to transfer the segmentation knowledge to the disease diagnosis network. Specifically, we first propose an asymmetric multi-scale interaction strategy to correlate each single low-level diagnosis feature with multi-scale segmentation features. Then, an effective strategy called SeA-block is adopted to vitalize diagnosis feature via correlated segmentation features. To model the segmentation-diagnosis interaction, SeA-block first embeds the diagnosis feature based on the segmentation information via the encoder, and then transfers the embedding back to the diagnosis feature space by a decoder. Experimental results demonstrate that SeATrans surpasses a wide range of state-of-the-art (SOTA) segmentation-assisted diagnosis methods on several disease diagnosis tasks.
Learning self-calibrated optic disc and cup segmentation from multi-rater annotations
Jun 14, 2022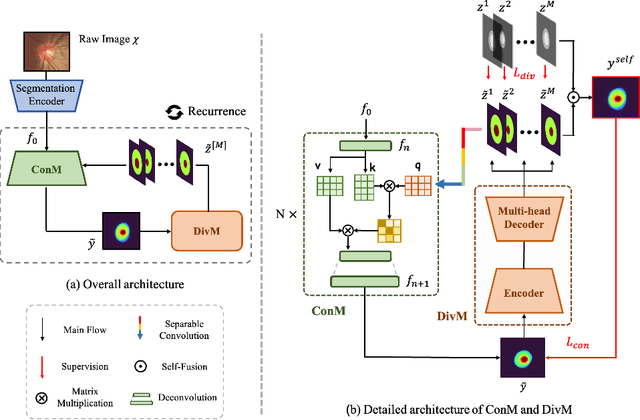
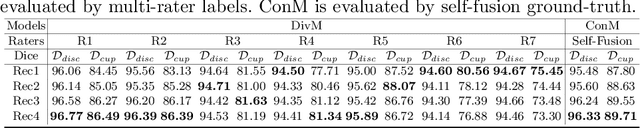
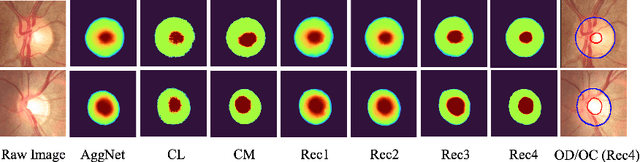
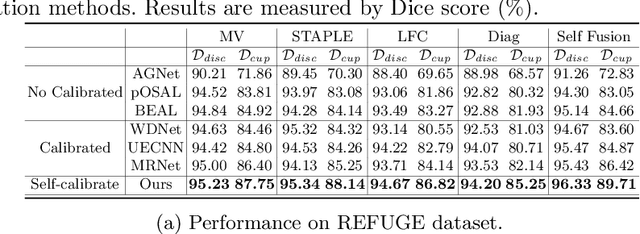
The segmentation of optic disc(OD) and optic cup(OC) from fundus images is an important fundamental task for glaucoma diagnosis. In the clinical practice, it is often necessary to collect opinions from multiple experts to obtain the final OD/OC annotation. This clinical routine helps to mitigate the individual bias. But when data is multiply annotated, standard deep learning models will be inapplicable. In this paper, we propose a novel neural network framework to learn OD/OC segmentation from multi-rater annotations. The segmentation results are self-calibrated through the iterative optimization of multi-rater expertness estimation and calibrated OD/OC segmentation. In this way, the proposed method can realize a mutual improvement of both tasks and finally obtain a refined segmentation result. Specifically, we propose Diverging Model(DivM) and Converging Model(ConM) to process the two tasks respectively. ConM segments the raw image based on the multi-rater expertness map provided by DivM. DivM generates multi-rater expertness map from the segmentation mask provided by ConM. The experiment results show that by recurrently running ConM and DivM, the results can be self-calibrated so as to outperform a range of state-of-the-art(SOTA) multi-rater segmentation methods.
REFUGE2 Challenge: Treasure for Multi-Domain Learning in Glaucoma Assessment
Feb 24, 2022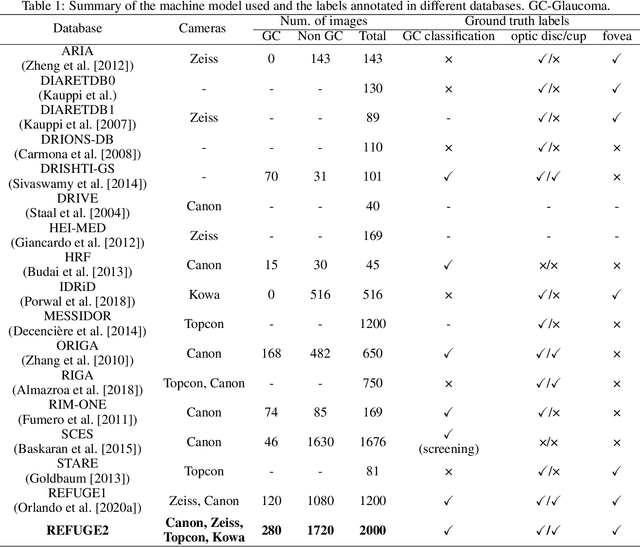
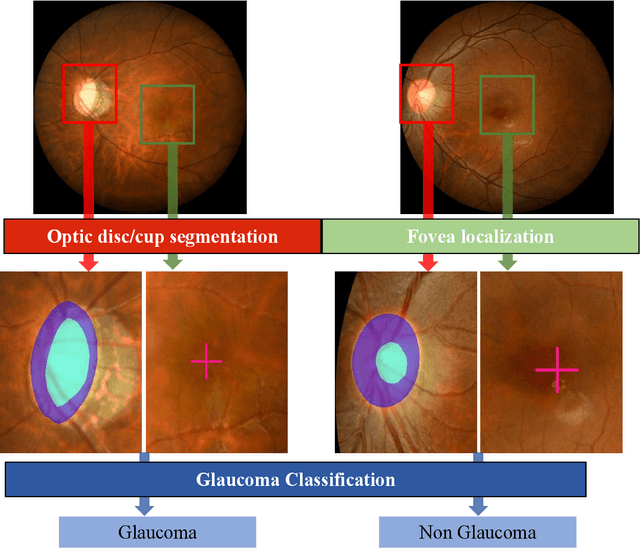
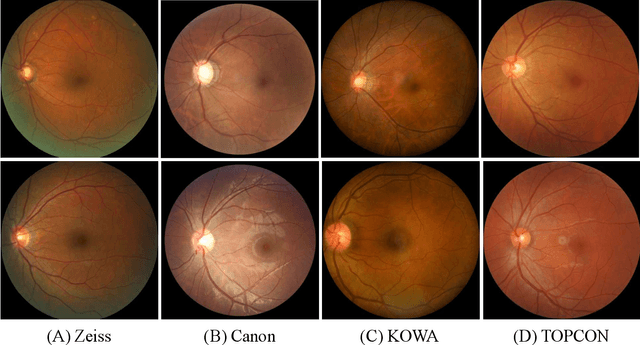
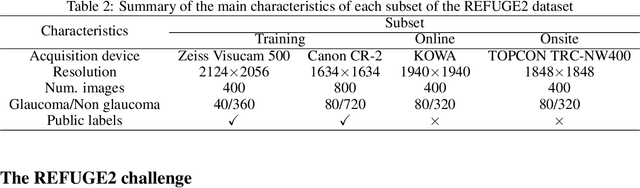
Glaucoma is the second leading cause of blindness and is the leading cause of irreversible blindness disease in the world. Early screening for glaucoma in the population is significant. Color fundus photography is the most cost effective imaging modality to screen for ocular diseases. Deep learning network is often used in color fundus image analysis due to its powful feature extraction capability. However, the model training of deep learning method needs a large amount of data, and the distribution of data should be abundant for the robustness of model performance. To promote the research of deep learning in color fundus photography and help researchers further explore the clinical application signification of AI technology, we held a REFUGE2 challenge. This challenge released 2,000 color fundus images of four models, including Zeiss, Canon, Kowa and Topcon, which can validate the stabilization and generalization of algorithms on multi-domain. Moreover, three sub-tasks were designed in the challenge, including glaucoma classification, cup/optic disc segmentation, and macular fovea localization. These sub-tasks technically cover the three main problems of computer vision and clinicly cover the main researchs of glaucoma diagnosis. Over 1,300 international competitors joined the REFUGE2 challenge, 134 teams submitted more than 3,000 valid preliminary results, and 22 teams reached the final. This article summarizes the methods of some of the finalists and analyzes their results. In particular, we observed that the teams using domain adaptation strategies had high and robust performance on the dataset with multi-domain. This indicates that UDA and other multi-domain related researches will be the trend of deep learning field in the future, and our REFUGE2 datasets will play an important role in these researches.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022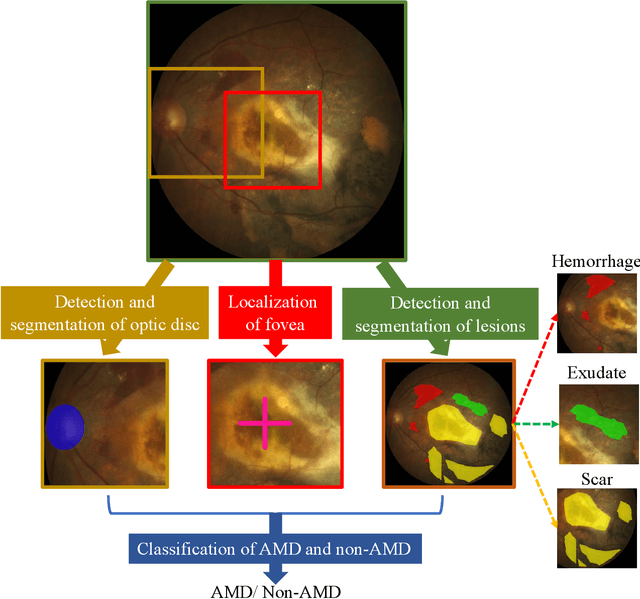

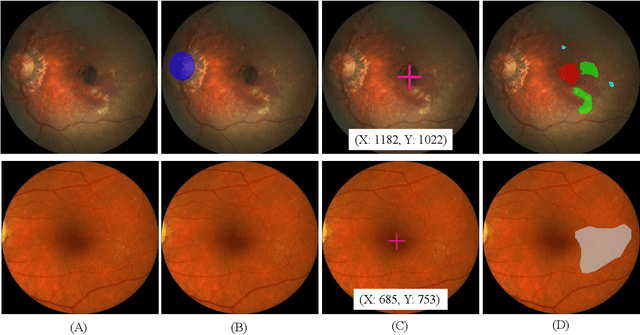
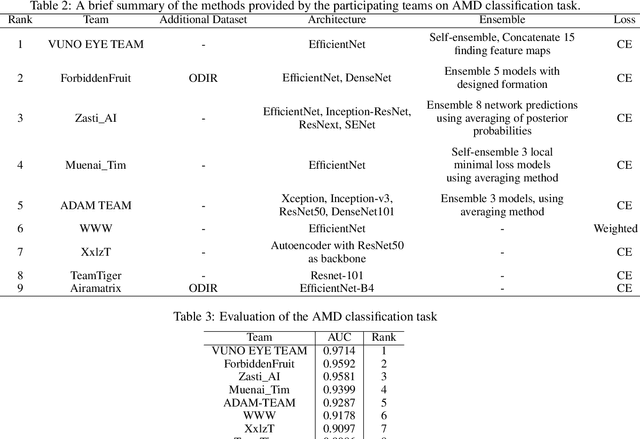
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022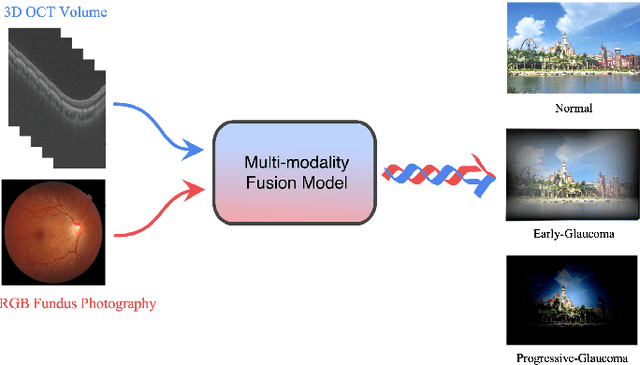
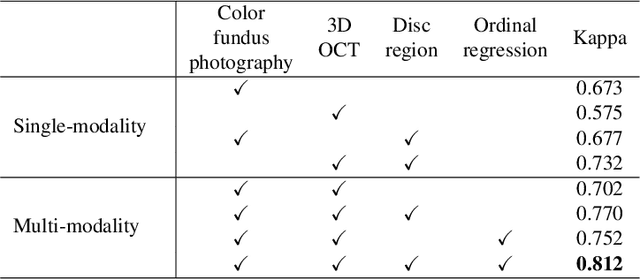
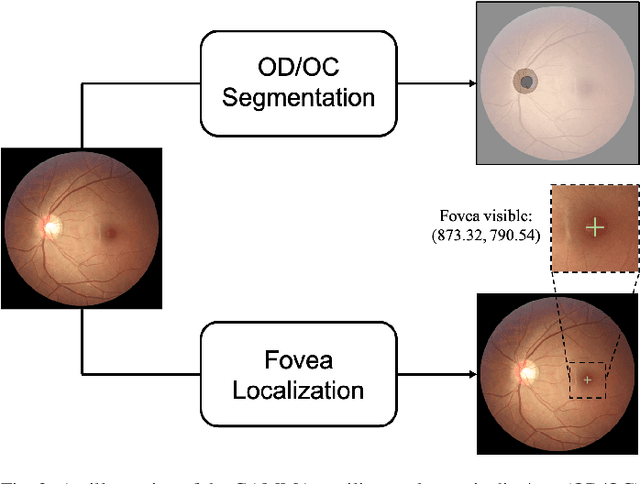
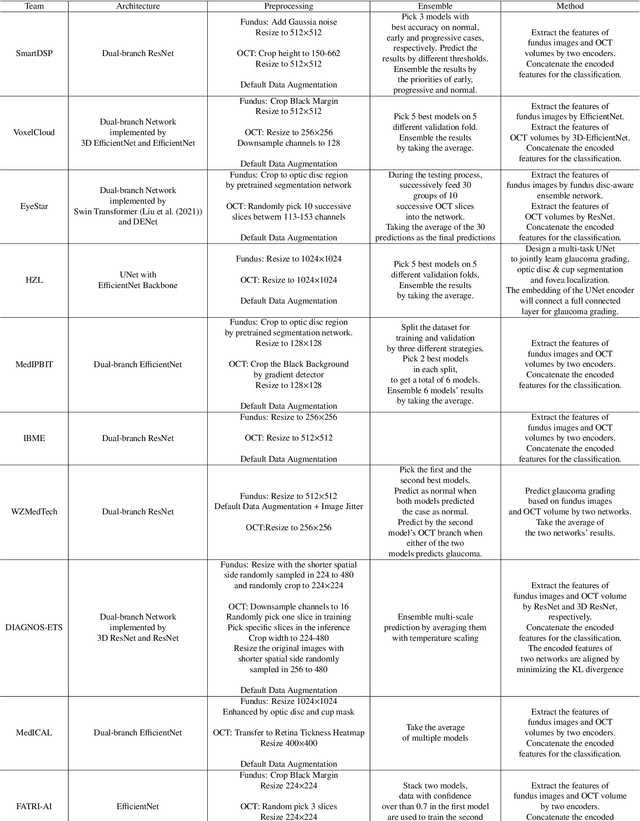
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
Opinions Vary? Diagnosis First!
Feb 14, 2022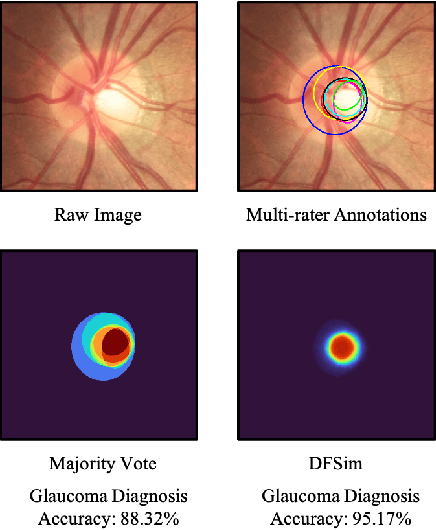
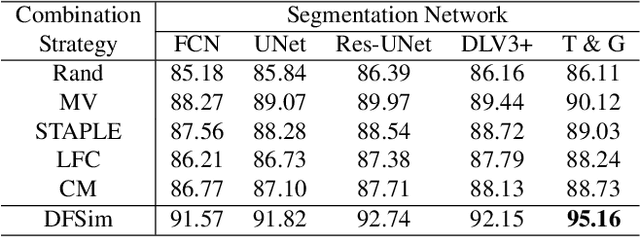
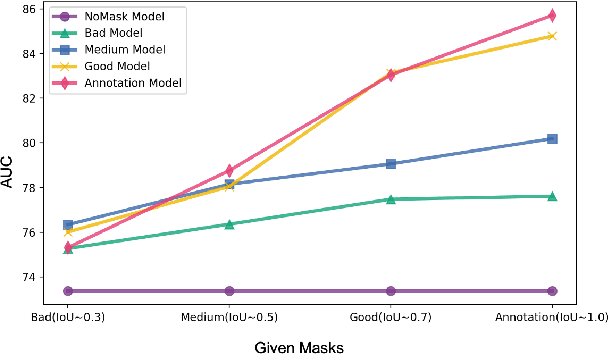
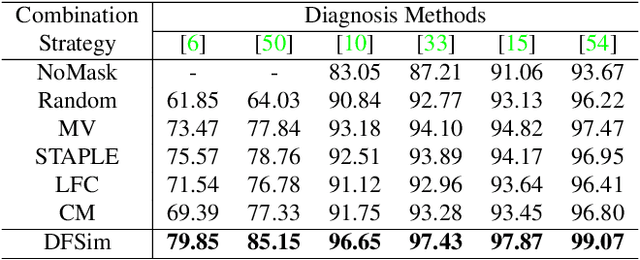
In medical image segmentation, images are usually annotated by several different clinical experts. This clinical routine helps to mitigate the personal bias. However, Computer Vision models often assume there has a unique ground-truth for each of the instance. This research gap between Computer Vision and medical routine is commonly existed but less explored by the current research.In this paper, we try to answer the following two questions: 1. How to learn an optimal combination of the multiple segmentation labels? and 2. How to estimate this segmentation mask from the raw image? We note that in clinical practice, the image segmentation mask usually exists as an auxiliary information for disease diagnosis. Adhering to this mindset, we propose a framework taking the diagnosis result as the gold standard, to estimate the segmentation mask upon the multi-rater segmentation labels, named DiFF (Diagnosis First segmentation Framework).DiFF is implemented by two novelty techniques. First, DFSim (Diagnosis First Simulation of gold label) is learned as an optimal combination of multi-rater segmentation labels for the disease diagnosis. Then, toward estimating DFSim mask from the raw image, we further propose T\&G Module (Take and Give Module) to instill the diagnosis knowledge into the segmentation network. The experiments show that compared with commonly used majority vote, the proposed DiFF is able to segment the masks with 6% improvement on diagnosis AUC score, which also outperforms various state-of-the-art multi-rater methods by a large margin.
Greedy Graph Searching for Vascular Tracking in Angiographic Image Sequences
May 25, 2018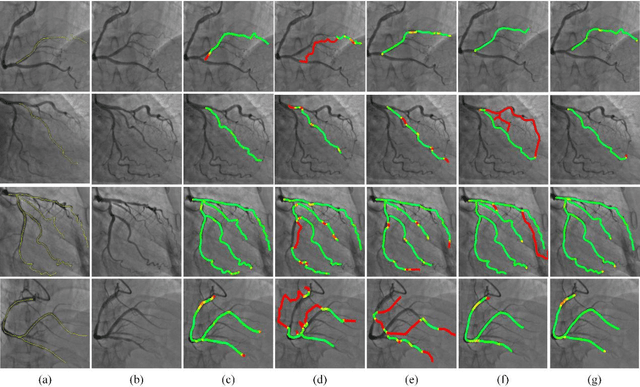
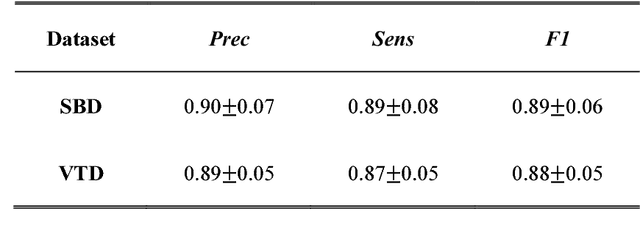

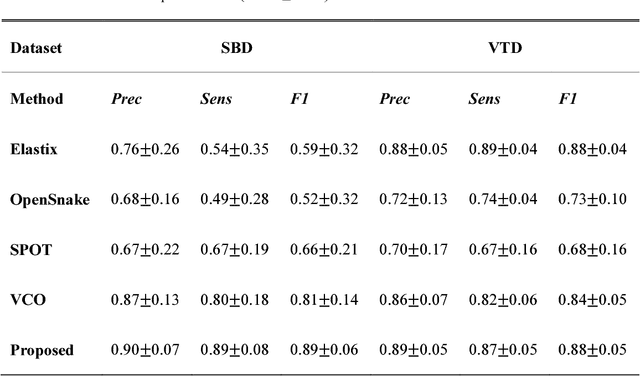
Vascular tracking of angiographic image sequences is one of the most clinically important tasks in the diagnostic assessment and interventional guidance of cardiac disease. However, this task can be challenging to accomplish because of unsatisfactory angiography image quality and complex vascular structures. Thus, this study proposed a new greedy graph search-based method for vascular tracking. Each vascular branch is separated from the vasculature and is tracked independently. Then, all branches are combined using topology optimization, thereby resulting in complete vasculature tracking. A gray-based image registration method was applied to determine the tracking range, and the deformation field between two consecutive frames was calculated. The vascular branch was described using a vascular centerline extraction method with multi-probability fusion-based topology optimization. We introduce an undirected acyclic graph establishment technique. A greedy search method was proposed to acquire all possible paths in the graph that might match the tracked vascular branch. The final tracking result was selected by branch matching using dynamic time warping with a DAISY descriptor. The solution to the problem reflected both the spatial and textural information between successive frames. Experimental results demonstrated that the proposed method was effective and robust for vascular tracking, attaining a F1 score of 0.89 on a single branch dataset and 0.88 on a vessel tree dataset. This approach provided a universal solution to address the problem of filamentary structure tracking.