 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025



Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Adaptively Augmented Consistency Learning: A Semi-supervised Segmentation Framework for Remote Sensing
Nov 14, 2024



Remote sensing (RS) involves the acquisition of data about objects or areas from a distance, primarily to monitor environmental changes, manage resources, and support planning and disaster response. A significant challenge in RS segmentation is the scarcity of high-quality labeled images due to the diversity and complexity of RS image, which makes pixel-level annotation difficult and hinders the development of effective supervised segmentation algorithms. To solve this problem, we propose Adaptively Augmented Consistency Learning (AACL), a semi-supervised segmentation framework designed to enhances RS segmentation accuracy under condictions of limited labeled data. AACL extracts additional information embedded in unlabeled images through the use of Uniform Strength Augmentation (USAug) and Adaptive Cut-Mix (AdaCM). Evaluations across various RS datasets demonstrate that AACL achieves competitive performance in semi-supervised segmentation, showing up to a 20% improvement in specific categories and 2% increase in overall performance compared to state-of-the-art frameworks.
UAV3D: A Large-scale 3D Perception Benchmark for Unmanned Aerial Vehicles
Oct 14, 2024Unmanned Aerial Vehicles (UAVs), equipped with cameras, are employed in numerous applications, including aerial photography, surveillance, and agriculture. In these applications, robust object detection and tracking are essential for the effective deployment of UAVs. However, existing benchmarks for UAV applications are mainly designed for traditional 2D perception tasks, restricting the development of real-world applications that require a 3D understanding of the environment. Furthermore, despite recent advancements in single-UAV perception, limited views of a single UAV platform significantly constrain its perception capabilities over long distances or in occluded areas. To address these challenges, we introduce UAV3D, a benchmark designed to advance research in both 3D and collaborative 3D perception tasks with UAVs. UAV3D comprises 1,000 scenes, each of which has 20 frames with fully annotated 3D bounding boxes on vehicles. We provide the benchmark for four 3D perception tasks: single-UAV 3D object detection, single-UAV object tracking, collaborative-UAV 3D object detection, and collaborative-UAV object tracking. Our dataset and code are available at https://huiyegit.github.io/UAV3D_Benchmark/.
Sketch2Human: Deep Human Generation with Disentangled Geometry and Appearance Control
Apr 24, 2024Geometry- and appearance-controlled full-body human image generation is an interesting but challenging task. Existing solutions are either unconditional or dependent on coarse conditions (e.g., pose, text), thus lacking explicit geometry and appearance control of body and garment. Sketching offers such editing ability and has been adopted in various sketch-based face generation and editing solutions. However, directly adapting sketch-based face generation to full-body generation often fails to produce high-fidelity and diverse results due to the high complexity and diversity in the pose, body shape, and garment shape and texture. Recent geometrically controllable diffusion-based methods mainly rely on prompts to generate appearance and it is hard to balance the realism and the faithfulness of their results to the sketch when the input is coarse. This work presents Sketch2Human, the first system for controllable full-body human image generation guided by a semantic sketch (for geometry control) and a reference image (for appearance control). Our solution is based on the latent space of StyleGAN-Human with inverted geometry and appearance latent codes as input. Specifically, we present a sketch encoder trained with a large synthetic dataset sampled from StyleGAN-Human's latent space and directly supervised by sketches rather than real images. Considering the entangled information of partial geometry and texture in StyleGAN-Human and the absence of disentangled datasets, we design a novel training scheme that creates geometry-preserved and appearance-transferred training data to tune a generator to achieve disentangled geometry and appearance control. Although our method is trained with synthetic data, it can handle hand-drawn sketches as well. Qualitative and quantitative evaluations demonstrate the superior performance of our method to state-of-the-art methods.
MatchXML: An Efficient Text-label Matching Framework for Extreme Multi-label Text Classification
Aug 25, 2023The eXtreme Multi-label text Classification(XMC) refers to training a classifier that assigns a text sample with relevant labels from an extremely large-scale label set (e.g., millions of labels). We propose MatchXML, an efficient text-label matching framework for XMC. We observe that the label embeddings generated from the sparse Term Frequency-Inverse Document Frequency(TF-IDF) features have several limitations. We thus propose label2vec to effectively train the semantic dense label embeddings by the Skip-gram model. The dense label embeddings are then used to build a Hierarchical Label Tree by clustering. In fine-tuning the pre-trained encoder Transformer, we formulate the multi-label text classification as a text-label matching problem in a bipartite graph. We then extract the dense text representations from the fine-tuned Transformer. Besides the fine-tuned dense text embeddings, we also extract the static dense sentence embeddings from a pre-trained Sentence Transformer. Finally, a linear ranker is trained by utilizing the sparse TF-IDF features, the fine-tuned dense text representations and static dense sentence features. Experimental results demonstrate that MatchXML achieves state-of-the-art accuracy on five out of six datasets. As for the speed, MatchXML outperforms the competing methods on all the six datasets. Our source code is publicly available at https://github.com/huiyegit/MatchXML.
DrawingInStyles: Portrait Image Generation and Editing with Spatially Conditioned StyleGAN
Mar 05, 2022
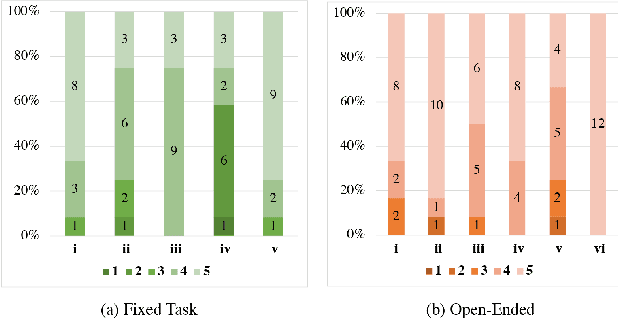

The research topic of sketch-to-portrait generation has witnessed a boost of progress with deep learning techniques. The recently proposed StyleGAN architectures achieve state-of-the-art generation ability but the original StyleGAN is not friendly for sketch-based creation due to its unconditional generation nature. To address this issue, we propose a direct conditioning strategy to better preserve the spatial information under the StyleGAN framework. Specifically, we introduce Spatially Conditioned StyleGAN (SC-StyleGAN for short), which explicitly injects spatial constraints to the original StyleGAN generation process. We explore two input modalities, sketches and semantic maps, which together allow users to express desired generation results more precisely and easily. Based on SC-StyleGAN, we present DrawingInStyles, a novel drawing interface for non-professional users to easily produce high-quality, photo-realistic face images with precise control, either from scratch or editing existing ones. Qualitative and quantitative evaluations show the superior generation ability of our method to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
Improving Text-to-Image Synthesis Using Contrastive Learning
Jul 06, 2021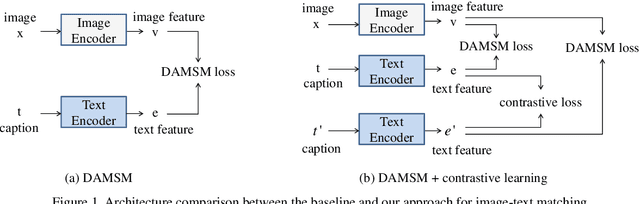
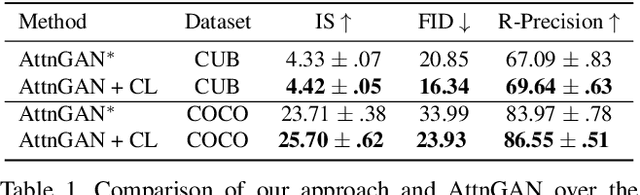
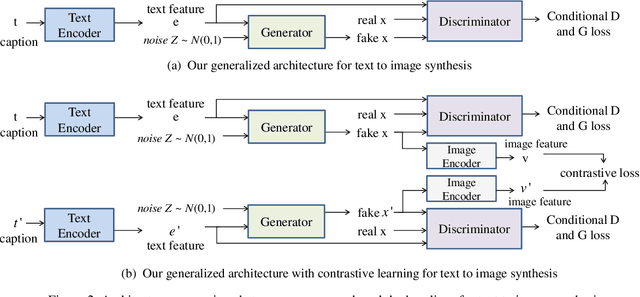

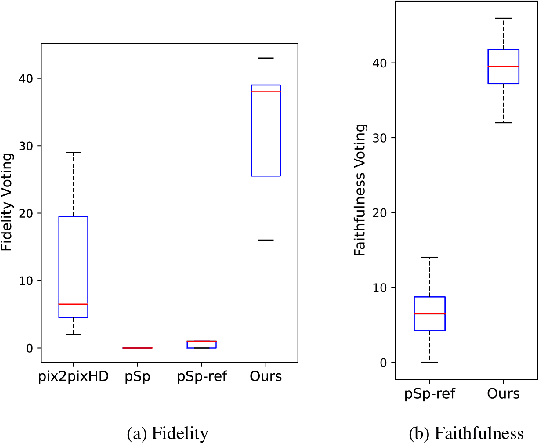
The goal of text-to-image synthesis is to generate a visually realistic image that matches a given text description. In practice, the captions annotated by humans for the same image have large variance in terms of contents and the choice of words. The linguistic discrepancy between the captions of the identical image leads to the synthetic images deviating from the ground truth. To address this issue, we propose a contrastive learning approach to improve the quality and enhance the semantic consistency of synthetic images. In the pre-training stage, we utilize the contrastive learning approach to learn the consistent textual representations for the captions corresponding to the same image. Furthermore, in the following stage of GAN training, we employ the contrastive learning method to enhance the consistency between the generated images from the captions related to the same image. We evaluate our approach over two popular text-to-image synthesis models, AttnGAN and DM-GAN, on datasets CUB and COCO, respectively. Experimental results have shown that our approach can effectively improve the quality of synthetic images in terms of three metrics: IS, FID and R-precision. Especially, on the challenging COCO dataset, our approach boosts the FID significantly by 29.60% over AttnGAn and by 21.96% over DM-GAN.
Generative Max-Mahalanobis Classifiers for Image Classification, Generation and More
Jan 01, 2021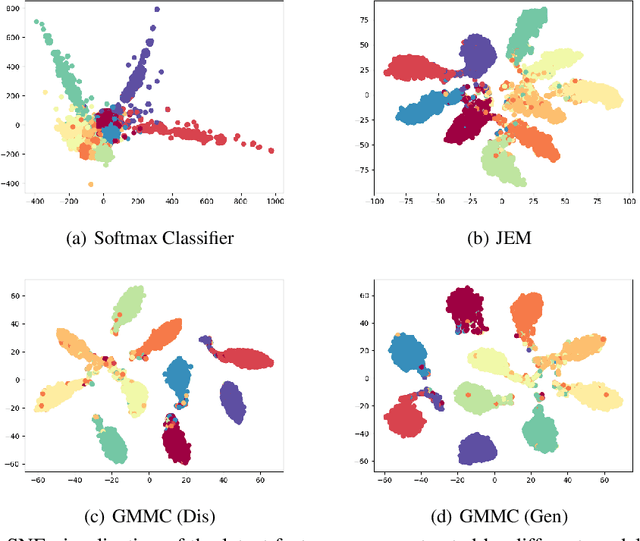
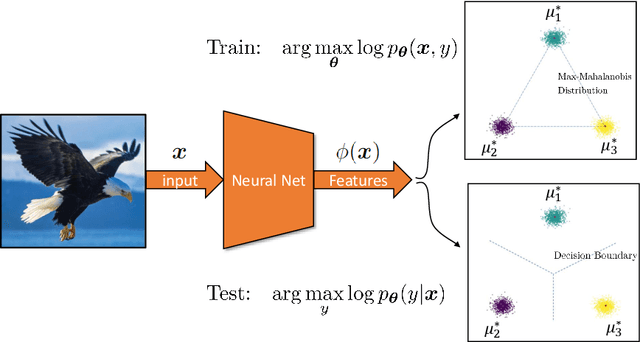

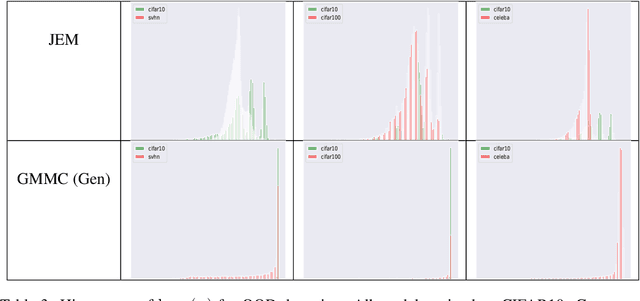
Joint Energy-based Model (JEM) of~\cite{jem} shows that a standard softmax classifier can be reinterpreted as an energy-based model (EBM) for the joint distribution $p(\boldsymbol{x}, y)$; the resulting model can be optimized with an energy-based training to improve calibration, robustness and out-of-distribution detection, while generating samples rivaling the quality of recent GAN-based approaches. However, the softmax classifier that JEM exploits is inherently discriminative and its latent feature space is not well formulated as probabilistic distributions, which may hinder its potential for image generation and incur training instability as observed in~\cite{jem}. We hypothesize that generative classifiers, such as Linear Discriminant Analysis (LDA), might be more suitable hybrid models for image generation since generative classifiers model the data generation process explicitly. This paper therefore investigates an LDA classifier for image classification and generation. In particular, the Max-Mahalanobis Classifier (MMC)~\cite{Pang2020Rethinking}, a special case of LDA, fits our goal very well since MMC formulates the latent feature space explicitly as the Max-Mahalanobis distribution~\cite{pang2018max}. We term our algorithm Generative MMC (GMMC), and show that it can be trained discriminatively, generatively or jointly for image classification and generation. Extensive experiments on multiple datasets (CIFAR10, CIFAR100 and SVHN) show that GMMC achieves state-of-the-art discriminative and generative performances, while outperforming JEM in calibration, adversarial robustness and out-of-distribution detection by a significant margin.
Pretrained Generalized Autoregressive Model with Adaptive Probabilistic Label Clusters for Extreme Multi-label Text Classification
Jul 05, 2020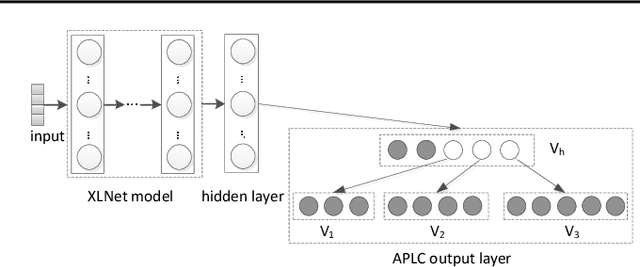
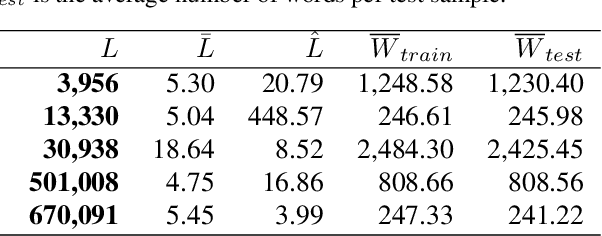
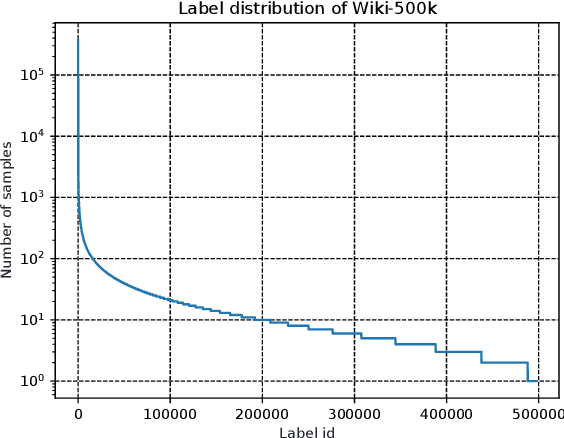
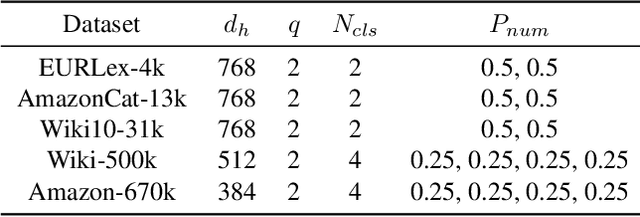
Extreme multi-label text classification (XMTC) is a task for tagging a given text with the most relevant labels from an extremely large label set. We propose a novel deep learning method called APLC-XLNet. Our approach fine-tunes the recently released generalized autoregressive pretrained model (XLNet) to learn a dense representation for the input text. We propose Adaptive Probabilistic Label Clusters (APLC) to approximate the cross entropy loss by exploiting the unbalanced label distribution to form clusters that explicitly reduce the computational time. Our experiments, carried out on five benchmark datasets, show that our approach significantly outperforms existing state-of-the-art methods. Our source code is available publicly at https://github.com/huiyegit/APLC_XLNet.
k-sums: another side of k-means
May 19, 2020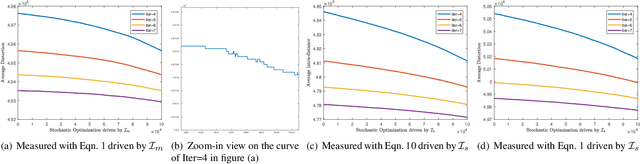
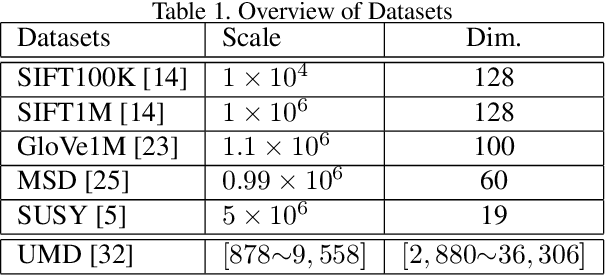
In this paper, the decades-old clustering method k-means is revisited. The original distortion minimization model of k-means is addressed by a pure stochastic minimization procedure. In each step of the iteration, one sample is tentatively reallocated from one cluster to another. It is moved to another cluster as long as the reallocation allows the sample to be closer to the new centroid. This optimization procedure converges faster to a better local minimum over k-means and many of its variants. This fundamental modification over the k-means loop leads to the redefinition of a family of k-means variants. Moreover, a new target function that minimizes the summation of pairwise distances within clusters is presented. We show that it could be solved under the same stochastic optimization procedure. This minimization procedure built upon two minimization models outperforms k-means and its variants considerably with different settings and on different datasets.