 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillLens: Symmetric Knowledge Distillation Through Logit Lens
Feb 14, 2026Standard Knowledge Distillation (KD) compresses Large Language Models (LLMs) by optimizing final outputs, yet it typically treats the teacher's intermediate layer's thought process as a black box. While feature-based distillation attempts to bridge this gap, existing methods (e.g., MSE and asymmetric KL divergence) ignore the rich uncertainty profiles required for the final output. In this paper, we introduce DistillLens, a framework that symmetrically aligns the evolving thought processes of student and teacher models. By projecting intermediate hidden states into the vocabulary space via the Logit Lens, we enforce structural alignment using a symmetric divergence objective. Our analysis proves that this constraint imposes a dual-sided penalty, preventing both overconfidence and underconfidence while preserving the high-entropy information conduits essential for final deduction. Extensive experiments on GPT-2 and Llama architectures demonstrate that DistillLens consistently outperforms standard KD and feature-transfer baselines on diverse instruction-following benchmarks. The code is available at https://github.com/manishdhakal/DistillLens.
UAV3D: A Large-scale 3D Perception Benchmark for Unmanned Aerial Vehicles
Oct 14, 2024



Unmanned Aerial Vehicles (UAVs), equipped with cameras, are employed in numerous applications, including aerial photography, surveillance, and agriculture. In these applications, robust object detection and tracking are essential for the effective deployment of UAVs. However, existing benchmarks for UAV applications are mainly designed for traditional 2D perception tasks, restricting the development of real-world applications that require a 3D understanding of the environment. Furthermore, despite recent advancements in single-UAV perception, limited views of a single UAV platform significantly constrain its perception capabilities over long distances or in occluded areas. To address these challenges, we introduce UAV3D, a benchmark designed to advance research in both 3D and collaborative 3D perception tasks with UAVs. UAV3D comprises 1,000 scenes, each of which has 20 frames with fully annotated 3D bounding boxes on vehicles. We provide the benchmark for four 3D perception tasks: single-UAV 3D object detection, single-UAV object tracking, collaborative-UAV 3D object detection, and collaborative-UAV object tracking. Our dataset and code are available at https://huiyegit.github.io/UAV3D_Benchmark/.
MatchXML: An Efficient Text-label Matching Framework for Extreme Multi-label Text Classification
Aug 25, 2023



The eXtreme Multi-label text Classification(XMC) refers to training a classifier that assigns a text sample with relevant labels from an extremely large-scale label set (e.g., millions of labels). We propose MatchXML, an efficient text-label matching framework for XMC. We observe that the label embeddings generated from the sparse Term Frequency-Inverse Document Frequency(TF-IDF) features have several limitations. We thus propose label2vec to effectively train the semantic dense label embeddings by the Skip-gram model. The dense label embeddings are then used to build a Hierarchical Label Tree by clustering. In fine-tuning the pre-trained encoder Transformer, we formulate the multi-label text classification as a text-label matching problem in a bipartite graph. We then extract the dense text representations from the fine-tuned Transformer. Besides the fine-tuned dense text embeddings, we also extract the static dense sentence embeddings from a pre-trained Sentence Transformer. Finally, a linear ranker is trained by utilizing the sparse TF-IDF features, the fine-tuned dense text representations and static dense sentence features. Experimental results demonstrate that MatchXML achieves state-of-the-art accuracy on five out of six datasets. As for the speed, MatchXML outperforms the competing methods on all the six datasets. Our source code is publicly available at https://github.com/huiyegit/MatchXML.
POSLAN: Disentangling Chat with Positional and Language encoded Post Embeddings
Jul 07, 2021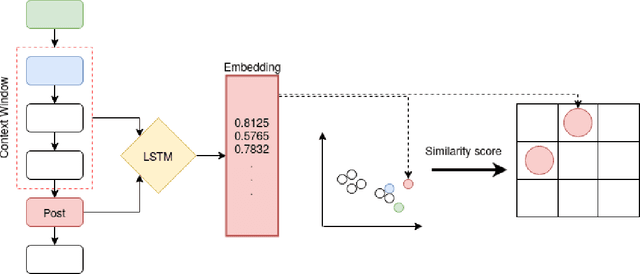

Most online message threads inherently will be cluttered and any new user or an existing user visiting after a hiatus will have a difficult time understanding whats being discussed in the thread. Similarly cluttered responses in a message thread makes analyzing the messages a difficult problem. The need for disentangling the clutter is much higher when the platform where the discussion is taking place does not provide functions to retrieve reply relations of the messages. This introduces an interesting problem to which \cite{wang2011learning} phrases as a structural learning problem. We create vector embeddings for posts in a thread so that it captures both linguistic and positional features in relation to a context of where a given message is in. Using these embeddings for posts we compute a similarity based connectivity matrix which then converted into a graph. After employing a pruning mechanisms the resultant graph can be used to discover the reply relation for the posts in the thread. The process of discovering or disentangling chat is kept as an unsupervised mechanism. We present our experimental results on a data set obtained from Telegram with limited meta data.
Improving Text-to-Image Synthesis Using Contrastive Learning
Jul 06, 2021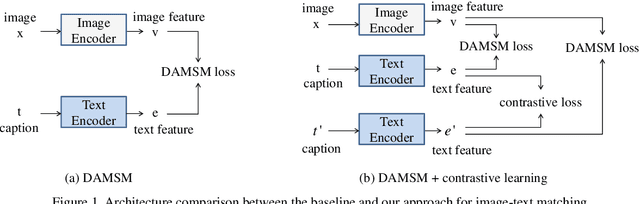
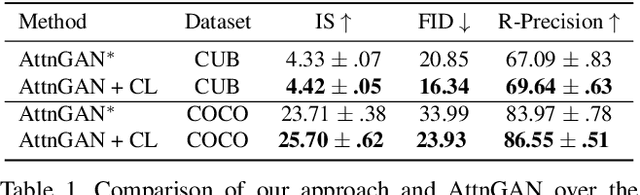
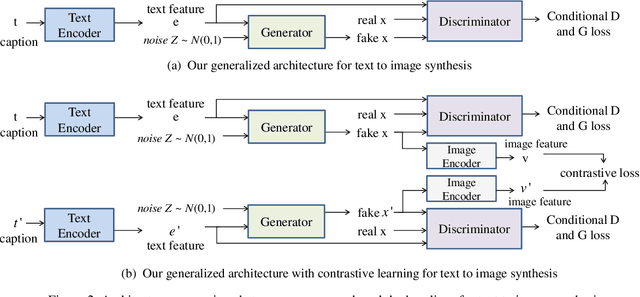

The goal of text-to-image synthesis is to generate a visually realistic image that matches a given text description. In practice, the captions annotated by humans for the same image have large variance in terms of contents and the choice of words. The linguistic discrepancy between the captions of the identical image leads to the synthetic images deviating from the ground truth. To address this issue, we propose a contrastive learning approach to improve the quality and enhance the semantic consistency of synthetic images. In the pre-training stage, we utilize the contrastive learning approach to learn the consistent textual representations for the captions corresponding to the same image. Furthermore, in the following stage of GAN training, we employ the contrastive learning method to enhance the consistency between the generated images from the captions related to the same image. We evaluate our approach over two popular text-to-image synthesis models, AttnGAN and DM-GAN, on datasets CUB and COCO, respectively. Experimental results have shown that our approach can effectively improve the quality of synthetic images in terms of three metrics: IS, FID and R-precision. Especially, on the challenging COCO dataset, our approach boosts the FID significantly by 29.60% over AttnGAn and by 21.96% over DM-GAN.
A Neutrosophic Description Logic
Mar 14, 2008

Description Logics (DLs) are appropriate, widely used, logics for managing structured knowledge. They allow reasoning about individuals and concepts, i.e. set of individuals with common properties. Typically, DLs are limited to dealing with crisp, well defined concepts. That is, concepts for which the problem whether an individual is an instance of it is yes/no question. More often than not, the concepts encountered in the real world do not have a precisely defined criteria of membership: we may say that an individual is an instance of a concept only to a certain degree, depending on the individual's properties. The DLs that deal with such fuzzy concepts are called fuzzy DLs. In order to deal with fuzzy, incomplete, indeterminate and inconsistent concepts, we need to extend the fuzzy DLs, combining the neutrosophic logic with a classical DL. In particular, concepts become neutrosophic (here neutrosophic means fuzzy, incomplete, indeterminate, and inconsistent), thus reasoning about neutrosophic concepts is supported. We'll define its syntax, its semantics, and describe its properties.
* 18 pages. Presented at the IEEE International Conference on Granular Computing, Georgia State University, Atlanta, USA, May 2006