 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViRED: Prediction of Visual Relations in Engineering Drawings
Sep 02, 2024



To accurately understand engineering drawings, it is essential to establish the correspondence between images and their description tables within the drawings. Existing document understanding methods predominantly focus on text as the main modality, which is not suitable for documents containing substantial image information. In the field of visual relation detection, the structure of the task inherently limits its capacity to assess relationships among all entity pairs in the drawings. To address this issue, we propose a vision-based relation detection model, named ViRED, to identify the associations between tables and circuits in electrical engineering drawings. Our model mainly consists of three parts: a vision encoder, an object encoder, and a relation decoder. We implement ViRED using PyTorch to evaluate its performance. To validate the efficacy of ViRED, we conduct a series of experiments. The experimental results indicate that, within the engineering drawing dataset, our approach attained an accuracy of 96\% in the task of relation prediction, marking a substantial improvement over existing methodologies. The results also show that ViRED can inference at a fast speed even when there are numerous objects in a single engineering drawing.
Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering
May 27, 2024



Code Community Question Answering (CCQA) seeks to tackle programming-related issues, thereby boosting productivity in both software engineering and academic research. Recent advancements in Reinforcement Learning from Human Feedback (RLHF) have transformed the fine-tuning process of Large Language Models (LLMs) to produce responses that closely mimic human behavior. Leveraging LLMs with RLHF for practical CCQA applications has thus emerged as a promising area of study. Unlike standard code question-answering tasks, CCQA involves multiple possible answers, with varying user preferences for each response. Additionally, code communities often show a preference for new APIs. These challenges prevent LLMs from generating responses that cater to the diverse preferences of users in CCQA tasks. To address these issues, we propose a novel framework called Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering (ALMupQA) to create user-focused responses. Our approach starts with Multi-perspective Preference Ranking Alignment (MPRA), which synthesizes varied user preferences based on the characteristics of answers from code communities. We then introduce a Retrieval-augmented In-context Learning (RIL) module to mitigate the problem of outdated answers by retrieving responses to similar questions from a question bank. Due to the limited availability of high-quality, multi-answer CCQA datasets, we also developed a dataset named StaCCQA from real code communities. Extensive experiments demonstrated the effectiveness of the ALMupQA framework in terms of accuracy and user preference. Compared to the base model, ALMupQA showed nearly an 11% improvement in BLEU, with increases of 20% and 17.5% in BERTScore and CodeBERTScore, respectively.
Gait Characterization in Duchenne Muscular Dystrophy (DMD) Using a Single-Sensor Accelerometer: Classical Machine Learning and Deep Learning Approaches
May 12, 2021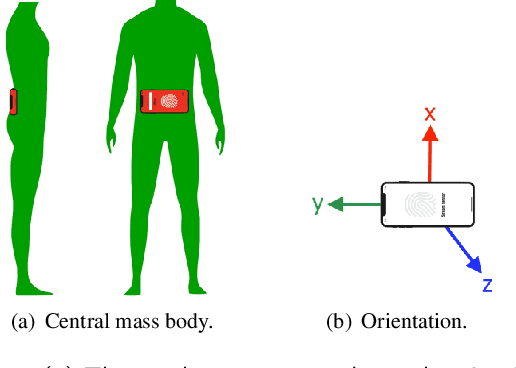
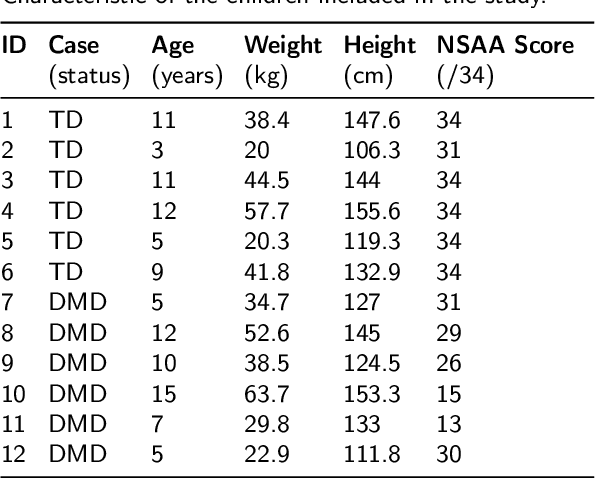
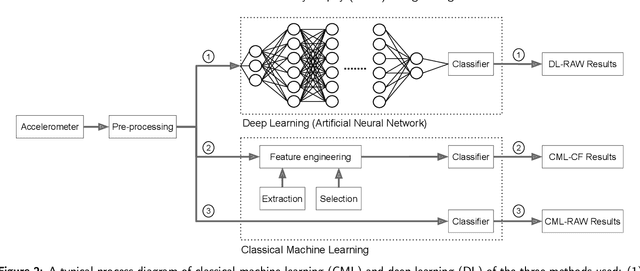
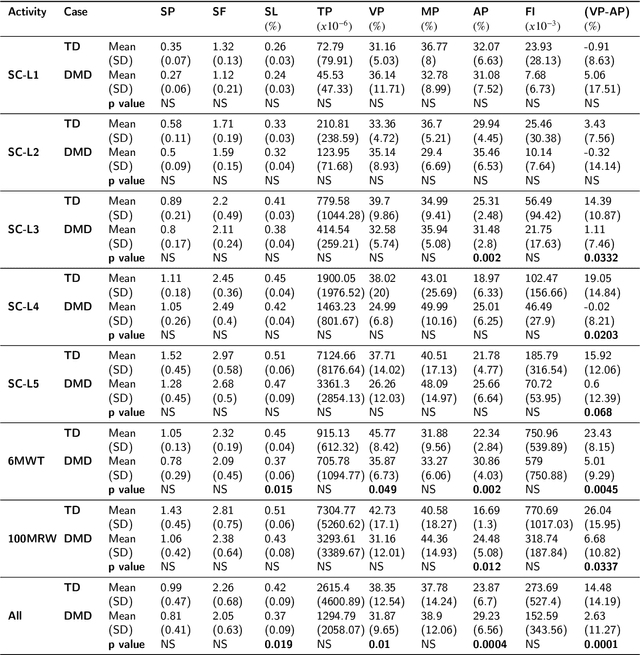
Differences in gait patterns of children with Duchenne muscular dystrophy (DMD) and typically developing (TD) peers are visible to the eye, but quantification of those differences outside of the gait laboratory has been elusive. We measured vertical, mediolateral, and anteroposterior acceleration using a waist-worn iPhone accelerometer during ambulation across a typical range of velocities. Six TD and six DMD children from 3-15 years of age underwent seven walking/running tasks, including five 25m walk/run tests at a slow walk to running speeds, a 6-minute walk test (6MWT), and a 100-meter-run/walk (100MRW). We extracted temporospatial clinical gait features (CFs) and applied multiple Artificial Intelligence (AI) tools to differentiate between DMD and TD control children using extracted features and raw data. Extracted CFs showed reduced step length and a greater mediolateral component of total power (TP) consistent with shorter strides and Trendelenberg-like gait commonly observed in DMD. AI methods using CFs and raw data varied ineffectiveness at differentiating between DMD and TD controls at different speeds, with an accuracy of some methods exceeding 91%. We demonstrate that by using AI tools with accelerometer data from a consumer-level smartphone, we can identify DMD gait disturbance in toddlers to early teens.
Adaptive Federated Dropout: Improving Communication Efficiency and Generalization for Federated Learning
Nov 08, 2020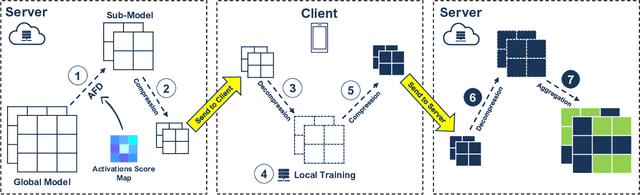
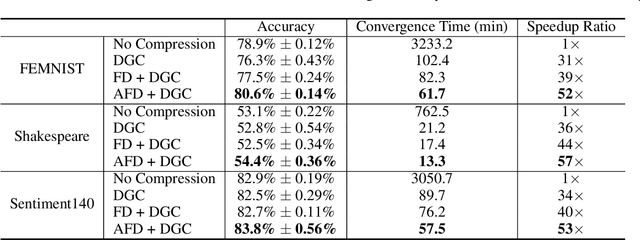
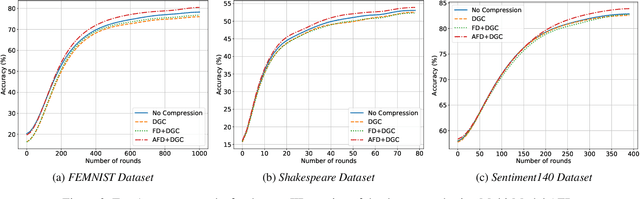
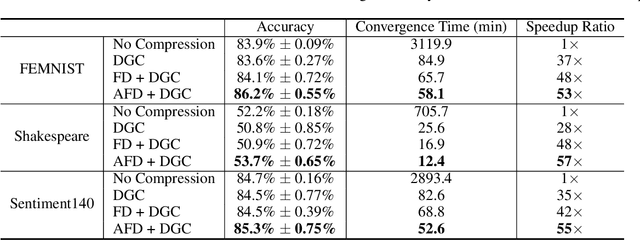
With more regulations tackling users' privacy-sensitive data protection in recent years, access to such data has become increasingly restricted and controversial. To exploit the wealth of data generated and located at distributed entities such as mobile phones, a revolutionary decentralized machine learning setting, known as Federated Learning, enables multiple clients located at different geographical locations to collaboratively learn a machine learning model while keeping all their data on-device. However, the scale and decentralization of federated learning present new challenges. Communication between the clients and the server is considered a main bottleneck in the convergence time of federated learning. In this paper, we propose and study Adaptive Federated Dropout (AFD), a novel technique to reduce the communication costs associated with federated learning. It optimizes both server-client communications and computation costs by allowing clients to train locally on a selected subset of the global model. We empirically show that this strategy, combined with existing compression methods, collectively provides up to 57x reduction in convergence time. It also outperforms the state-of-the-art solutions for communication efficiency. Furthermore, it improves model generalization by up to 1.7%.