 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Focused Inference and Extraction Attacks on Diffusion Models
Oct 14, 2024The increasing reliance on diffusion models for generating synthetic images has amplified concerns about the unauthorized use of personal data, particularly facial images, in model training. In this paper, we introduce a novel identity inference framework to hold model owners accountable for including individuals' identities in their training data. Our approach moves beyond traditional membership inference attacks by focusing on identity-level inference, providing a new perspective on data privacy violations. Through comprehensive evaluations on two facial image datasets, Labeled Faces in the Wild (LFW) and CelebA, our experiments demonstrate that the proposed membership inference attack surpasses baseline methods, achieving an attack success rate of up to 89% and an AUC-ROC of 0.91, while the identity inference attack attains 92% on LDM models trained on LFW, and the data extraction attack achieves 91.6% accuracy on DDPMs, validating the effectiveness of our approach across diffusion models.
PTQ4ADM: Post-Training Quantization for Efficient Text Conditional Audio Diffusion Models
Sep 20, 2024Denoising diffusion models have emerged as state-of-the-art in generative tasks across image, audio, and video domains, producing high-quality, diverse, and contextually relevant data. However, their broader adoption is limited by high computational costs and large memory footprints. Post-training quantization (PTQ) offers a promising approach to mitigate these challenges by reducing model complexity through low-bandwidth parameters. Yet, direct application of PTQ to diffusion models can degrade synthesis quality due to accumulated quantization noise across multiple denoising steps, particularly in conditional tasks like text-to-audio synthesis. This work introduces PTQ4ADM, a novel framework for quantizing audio diffusion models(ADMs). Our key contributions include (1) a coverage-driven prompt augmentation method and (2) an activation-aware calibration set generation algorithm for text-conditional ADMs. These techniques ensure comprehensive coverage of audio aspects and modalities while preserving synthesis fidelity. We validate our approach on TANGO, Make-An-Audio, and AudioLDM models for text-conditional audio generation. Extensive experiments demonstrate PTQ4ADM's capability to reduce the model size by up to 70\% while achieving synthesis quality metrics comparable to full-precision models($<$5\% increase in FD scores). We show that specific layers in the backbone network can be quantized to 4-bit weights and 8-bit activations without significant quality loss. This work paves the way for more efficient deployment of ADMs in resource-constrained environments.
FedDM: Enhancing Communication Efficiency and Handling Data Heterogeneity in Federated Diffusion Models
Jul 20, 2024



We introduce FedDM, a novel training framework designed for the federated training of diffusion models. Our theoretical analysis establishes the convergence of diffusion models when trained in a federated setting, presenting the specific conditions under which this convergence is guaranteed. We propose a suite of training algorithms that leverage the U-Net architecture as the backbone for our diffusion models. These include a basic Federated Averaging variant, FedDM-vanilla, FedDM-prox to handle data heterogeneity among clients, and FedDM-quant, which incorporates a quantization module to reduce the model update size, thereby enhancing communication efficiency across the federated network. We evaluate our algorithms on FashionMNIST (28x28 resolution), CIFAR-10 (32x32 resolution), and CelebA (64x64 resolution) for DDPMs, as well as LSUN Church Outdoors (256x256 resolution) for LDMs, focusing exclusively on the imaging modality. Our evaluation results demonstrate that FedDM algorithms maintain high generation quality across image resolutions. At the same time, the use of quantized updates and proximal terms in the local training objective significantly enhances communication efficiency (up to 4x) and model convergence, particularly in non-IID data settings, at the cost of increased FID scores (up to 1.75x).
Opportunistic Episodic Reinforcement Learning
Oct 24, 2022



In this paper, we propose and study opportunistic reinforcement learning - a new variant of reinforcement learning problems where the regret of selecting a suboptimal action varies under an external environmental condition known as the variation factor. When the variation factor is low, so is the regret of selecting a suboptimal action and vice versa. Our intuition is to exploit more when the variation factor is high, and explore more when the variation factor is low. We demonstrate the benefit of this novel framework for finite-horizon episodic MDPs by designing and evaluating OppUCRL2 and OppPSRL algorithms. Our algorithms dynamically balance the exploration-exploitation trade-off for reinforcement learning by introducing variation factor-dependent optimism to guide exploration. We establish an $\tilde{O}(HS \sqrt{AT})$ regret bound for the OppUCRL2 algorithm and show through simulations that both OppUCRL2 and OppPSRL algorithm outperform their original corresponding algorithms.
Adaptive Federated Dropout: Improving Communication Efficiency and Generalization for Federated Learning
Nov 08, 2020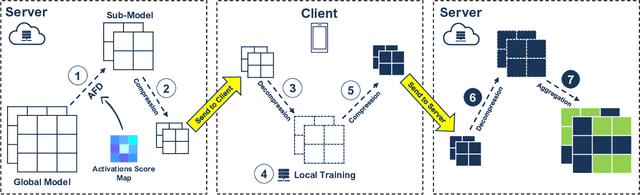
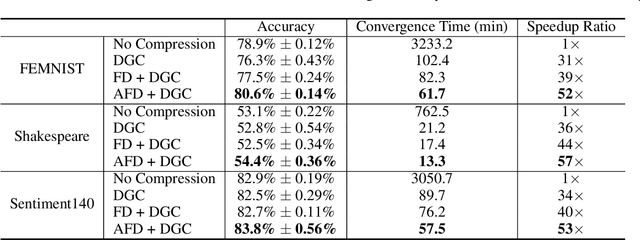
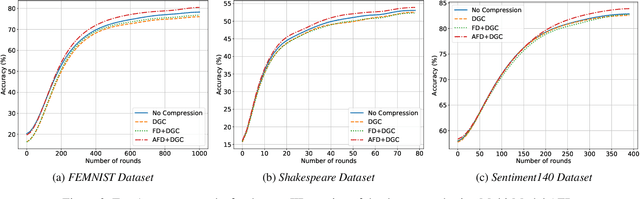
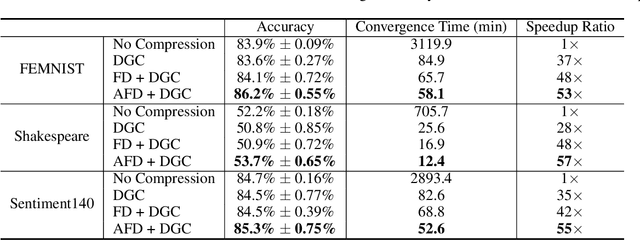
With more regulations tackling users' privacy-sensitive data protection in recent years, access to such data has become increasingly restricted and controversial. To exploit the wealth of data generated and located at distributed entities such as mobile phones, a revolutionary decentralized machine learning setting, known as Federated Learning, enables multiple clients located at different geographical locations to collaboratively learn a machine learning model while keeping all their data on-device. However, the scale and decentralization of federated learning present new challenges. Communication between the clients and the server is considered a main bottleneck in the convergence time of federated learning. In this paper, we propose and study Adaptive Federated Dropout (AFD), a novel technique to reduce the communication costs associated with federated learning. It optimizes both server-client communications and computation costs by allowing clients to train locally on a selected subset of the global model. We empirically show that this strategy, combined with existing compression methods, collectively provides up to 57x reduction in convergence time. It also outperforms the state-of-the-art solutions for communication efficiency. Furthermore, it improves model generalization by up to 1.7%.
An Opportunistic Bandit Approach for User Interface Experimentation
Jun 21, 2020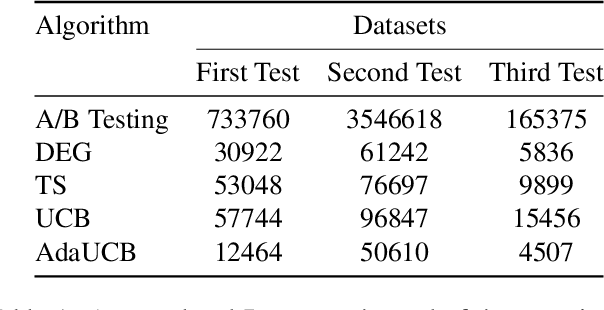
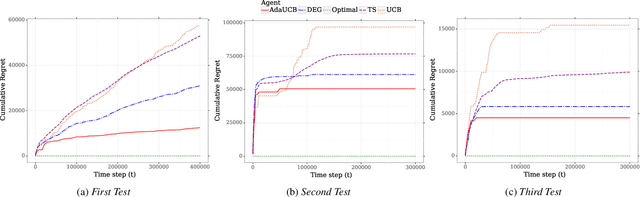
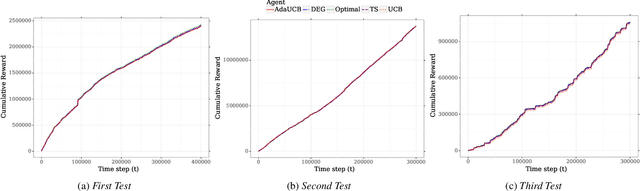
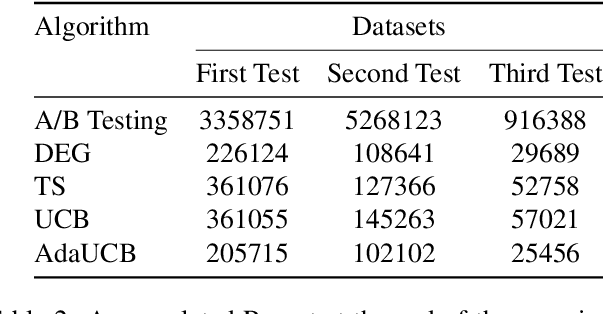
Facing growing competition from online rivals, the retail industry is increasingly investing in their online shopping platforms to win the high-stake battle of customer' loyalty. User experience is playing an essential role in this competition, and retailers are continuously experimenting and optimizing their user interface for better user experience. The cost of experimentation is dominated by the opportunity cost of providing a suboptimal service to the customers. Through this paper, we demonstrate the effectiveness of opportunistic bandits to make the experiments as inexpensive as possible using real online retail data. In fact, we model user interface experimentation as an opportunistic bandit problem, in which the cost of exploration varies under a factor extracted from customer features. We achieve significant regret reduction by mitigating costly exploration and providing extra contextual information that helps to guide the testing process. Moreover, we analyze the advantages and challenges of using opportunistic bandits for online retail experimentation.