 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Artificial Intelligence Technology for Mapping Research to Sustainable Development Goals: A Case Study
Nov 09, 2023



The number of publications related to the Sustainable Development Goals (SDGs) continues to grow. These publications cover a diverse spectrum of research, from humanities and social sciences to engineering and health. Given the imperative of funding bodies to monitor outcomes and impacts, linking publications to relevant SDGs is critical but remains time-consuming and difficult given the breadth and complexity of the SDGs. A publication may relate to several goals (interconnection feature of goals), and therefore require multidisciplinary knowledge to tag accurately. Machine learning approaches are promising and have proven particularly valuable for tasks such as manual data labeling and text classification. In this study, we employed over 82,000 publications from an Australian university as a case study. We utilized a similarity measure to map these publications onto Sustainable Development Goals (SDGs). Additionally, we leveraged the OpenAI GPT model to conduct the same task, facilitating a comparative analysis between the two approaches. Experimental results show that about 82.89% of the results obtained by the similarity measure overlap (at least one tag) with the outputs of the GPT model. The adopted model (similarity measure) can complement GPT model for SDG classification. Furthermore, deep learning methods, which include the similarity measure used here, are more accessible and trusted for dealing with sensitive data without the use of commercial AI services or the deployment of expensive computing resources to operate large language models. Our study demonstrates how a crafted combination of the two methods can achieve reliable results for mapping research to the SDGs.
Lightme: Analysing Language in Internet Support Groups for Mental Health
Jul 03, 2020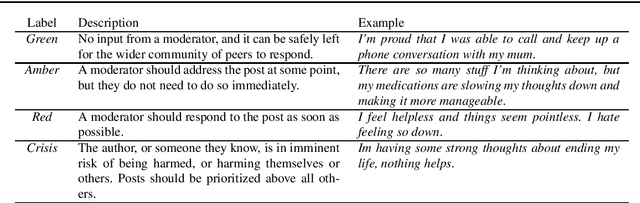
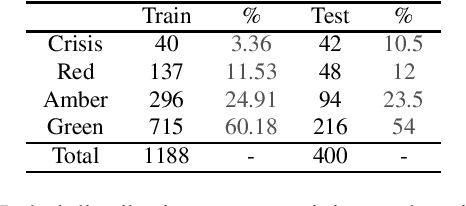
Background: Assisting moderators to triage harmful posts in Internet Support Groups is relevant to ensure its safe use. Automated text classification methods analysing the language expressed in posts of online forums is a promising solution. Methods: Natural Language Processing and Machine Learning technologies were used to build a triage post classifier using a dataset from Reachout mental health forum for young people. Results: When comparing with the state-of-the-art, a solution mainly based on features from lexical resources, received the best classification performance for the crisis posts (52%), which is the most severe class. Six salient linguistic characteristics were found when analysing the crisis post; 1) posts expressing hopelessness, 2) short posts expressing concise negative emotional responses, 3) long posts expressing variations of emotions, 4) posts expressing dissatisfaction with available health services, 5) posts utilising storytelling, and 6) posts expressing users seeking advice from peers during a crisis. Conclusion: It is possible to build a competitive triage classifier using features derived only from the textual content of the post. Further research needs to be done in order to translate our quantitative and qualitative findings into features, as it may improve overall performance.