 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain Tumor Segmentation with Deep Neural Networks
May 20, 2016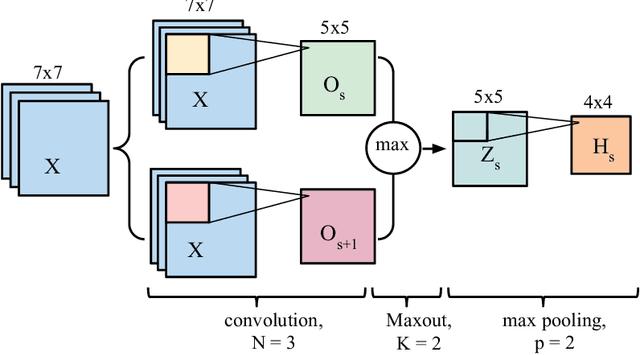
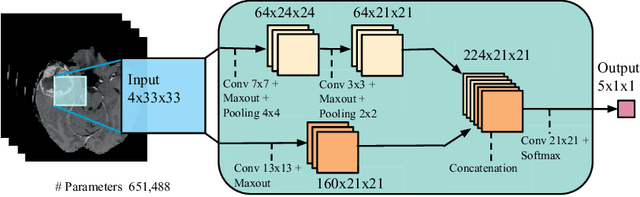

In this paper, we present a fully automatic brain tumor segmentation method based on Deep Neural Networks (DNNs). The proposed networks are tailored to glioblastomas (both low and high grade) pictured in MR images. By their very nature, these tumors can appear anywhere in the brain and have almost any kind of shape, size, and contrast. These reasons motivate our exploration of a machine learning solution that exploits a flexible, high capacity DNN while being extremely efficient. Here, we give a description of different model choices that we've found to be necessary for obtaining competitive performance. We explore in particular different architectures based on Convolutional Neural Networks (CNN), i.e. DNNs specifically adapted to image data. We present a novel CNN architecture which differs from those traditionally used in computer vision. Our CNN exploits both local features as well as more global contextual features simultaneously. Also, different from most traditional uses of CNNs, our networks use a final layer that is a convolutional implementation of a fully connected layer which allows a 40 fold speed up. We also describe a 2-phase training procedure that allows us to tackle difficulties related to the imbalance of tumor labels. Finally, we explore a cascade architecture in which the output of a basic CNN is treated as an additional source of information for a subsequent CNN. Results reported on the 2013 BRATS test dataset reveal that our architecture improves over the currently published state-of-the-art while being over 30 times faster.
Movie Description
May 12, 2016
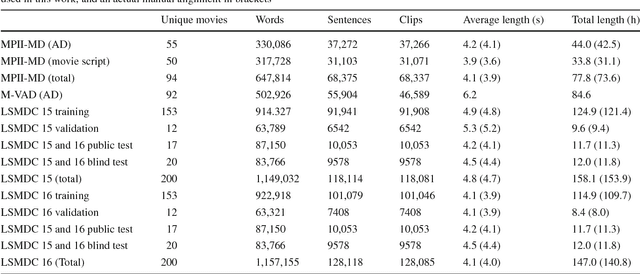

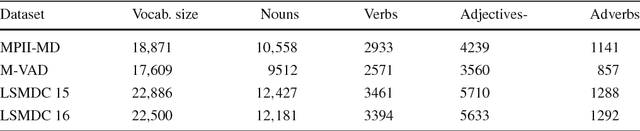
Audio Description (AD) provides linguistic descriptions of movies and allows visually impaired people to follow a movie along with their peers. Such descriptions are by design mainly visual and thus naturally form an interesting data source for computer vision and computational linguistics. In this work we propose a novel dataset which contains transcribed ADs, which are temporally aligned to full length movies. In addition we also collected and aligned movie scripts used in prior work and compare the two sources of descriptions. In total the Large Scale Movie Description Challenge (LSMDC) contains a parallel corpus of 118,114 sentences and video clips from 202 movies. First we characterize the dataset by benchmarking different approaches for generating video descriptions. Comparing ADs to scripts, we find that ADs are indeed more visual and describe precisely what is shown rather than what should happen according to the scripts created prior to movie production. Furthermore, we present and compare the results of several teams who participated in a challenge organized in the context of the workshop "Describing and Understanding Video & The Large Scale Movie Description Challenge (LSMDC)", at ICCV 2015.
Document Neural Autoregressive Distribution Estimation
Mar 18, 2016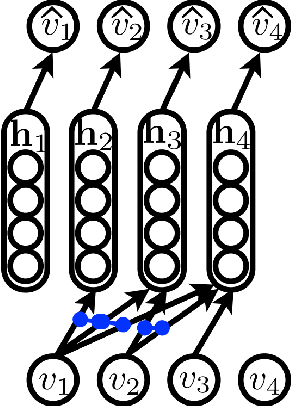

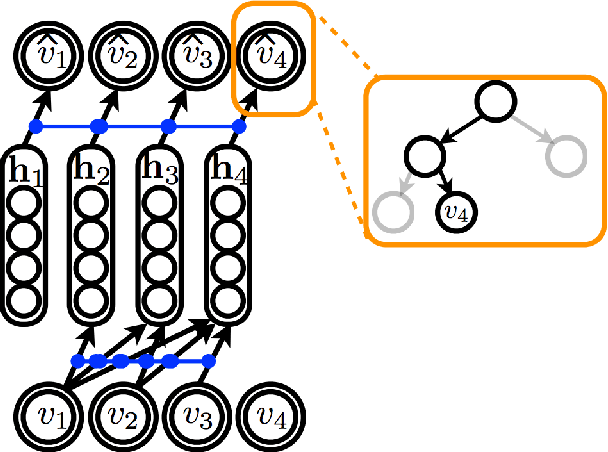
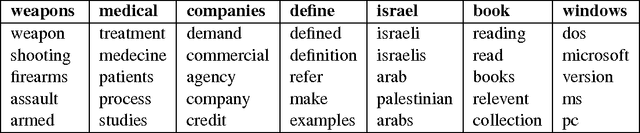
We present an approach based on feed-forward neural networks for learning the distribution of textual documents. This approach is inspired by the Neural Autoregressive Distribution Estimator(NADE) model, which has been shown to be a good estimator of the distribution of discrete-valued igh-dimensional vectors. In this paper, we present how NADE can successfully be adapted to the case of textual data, retaining from NADE the property that sampling or computing the probability of observations can be done exactly and efficiently. The approach can also be used to learn deep representations of documents that are competitive to those learned by the alternative topic modeling approaches. Finally, we describe how the approach can be combined with a regular neural network N-gram model and substantially improve its performance, by making its learned representation sensitive to the larger, document-specific context.
An Infinite Restricted Boltzmann Machine
Mar 18, 2016We present a mathematical construction for the restricted Boltzmann machine (RBM) that doesn't require specifying the number of hidden units. In fact, the hidden layer size is adaptive and can grow during training. This is obtained by first extending the RBM to be sensitive to the ordering of its hidden units. Then, thanks to a carefully chosen definition of the energy function, we show that the limit of infinitely many hidden units is well defined. As with RBM, approximate maximum likelihood training can be performed, resulting in an algorithm that naturally and adaptively adds trained hidden units during learning. We empirically study the behaviour of this infinite RBM, showing that its performance is competitive to that of the RBM, while not requiring the tuning of a hidden layer size.
Autoencoding beyond pixels using a learned similarity metric
Feb 10, 2016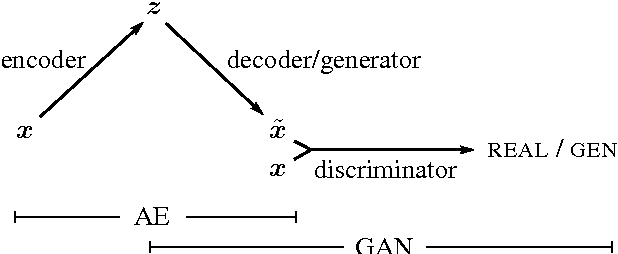

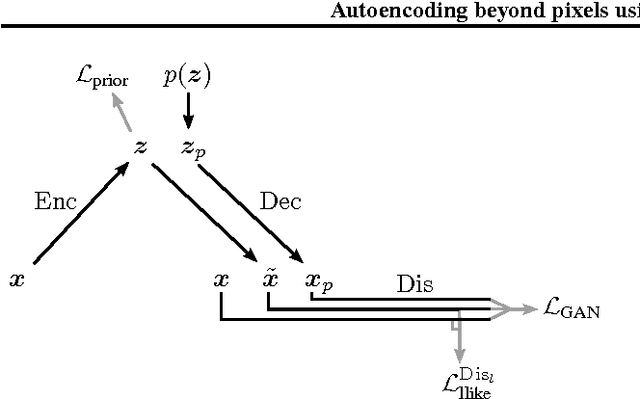

We present an autoencoder that leverages learned representations to better measure similarities in data space. By combining a variational autoencoder with a generative adversarial network we can use learned feature representations in the GAN discriminator as basis for the VAE reconstruction objective. Thereby, we replace element-wise errors with feature-wise errors to better capture the data distribution while offering invariance towards e.g. translation. We apply our method to images of faces and show that it outperforms VAEs with element-wise similarity measures in terms of visual fidelity. Moreover, we show that the method learns an embedding in which high-level abstract visual features (e.g. wearing glasses) can be modified using simple arithmetic.
A Deep and Autoregressive Approach for Topic Modeling of Multimodal Data
Dec 31, 2015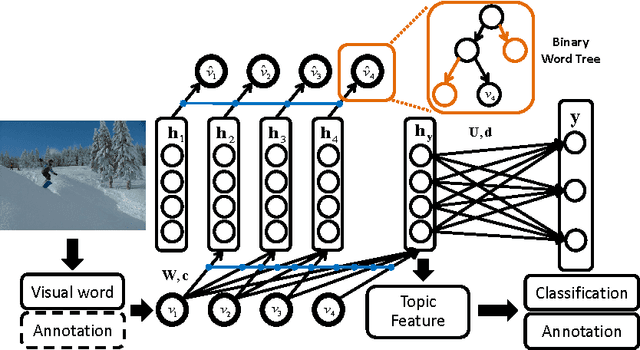
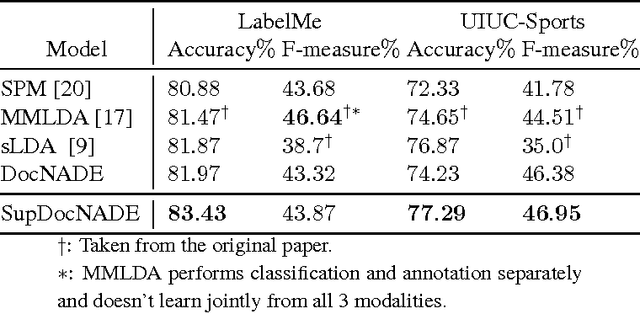
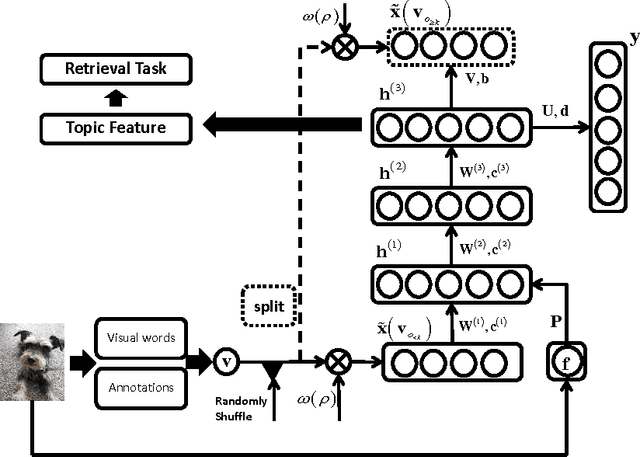

Topic modeling based on latent Dirichlet allocation (LDA) has been a framework of choice to deal with multimodal data, such as in image annotation tasks. Another popular approach to model the multimodal data is through deep neural networks, such as the deep Boltzmann machine (DBM). Recently, a new type of topic model called the Document Neural Autoregressive Distribution Estimator (DocNADE) was proposed and demonstrated state-of-the-art performance for text document modeling. In this work, we show how to successfully apply and extend this model to multimodal data, such as simultaneous image classification and annotation. First, we propose SupDocNADE, a supervised extension of DocNADE, that increases the discriminative power of the learned hidden topic features and show how to employ it to learn a joint representation from image visual words, annotation words and class label information. We test our model on the LabelMe and UIUC-Sports data sets and show that it compares favorably to other topic models. Second, we propose a deep extension of our model and provide an efficient way of training the deep model. Experimental results show that our deep model outperforms its shallow version and reaches state-of-the-art performance on the Multimedia Information Retrieval (MIR) Flickr data set.
Clustering is Efficient for Approximate Maximum Inner Product Search
Nov 30, 2015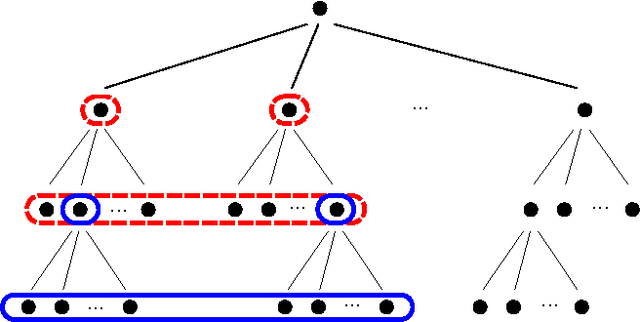
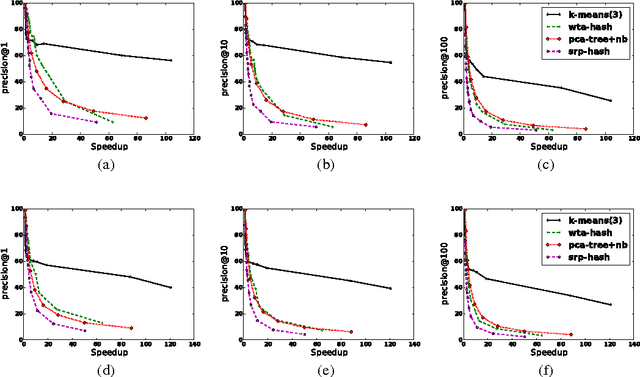
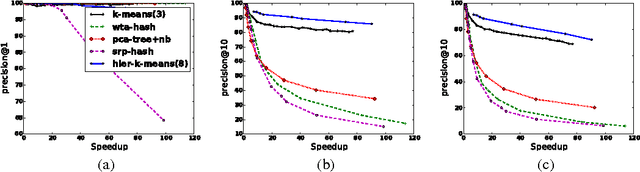
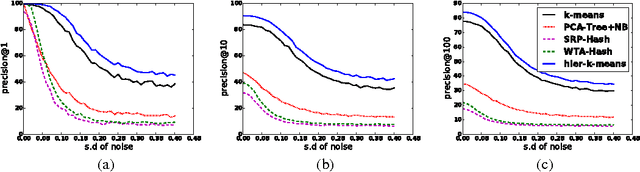
Efficient Maximum Inner Product Search (MIPS) is an important task that has a wide applicability in recommendation systems and classification with a large number of classes. Solutions based on locality-sensitive hashing (LSH) as well as tree-based solutions have been investigated in the recent literature, to perform approximate MIPS in sublinear time. In this paper, we compare these to another extremely simple approach for solving approximate MIPS, based on variants of the k-means clustering algorithm. Specifically, we propose to train a spherical k-means, after having reduced the MIPS problem to a Maximum Cosine Similarity Search (MCSS). Experiments on two standard recommendation system benchmarks as well as on large vocabulary word embeddings, show that this simple approach yields much higher speedups, for the same retrieval precision, than current state-of-the-art hashing-based and tree-based methods. This simple method also yields more robust retrievals when the query is corrupted by noise.
Correlational Neural Networks
Oct 12, 2015Common Representation Learning (CRL), wherein different descriptions (or views) of the data are embedded in a common subspace, is receiving a lot of attention recently. Two popular paradigms here are Canonical Correlation Analysis (CCA) based approaches and Autoencoder (AE) based approaches. CCA based approaches learn a joint representation by maximizing correlation of the views when projected to the common subspace. AE based methods learn a common representation by minimizing the error of reconstructing the two views. Each of these approaches has its own advantages and disadvantages. For example, while CCA based approaches outperform AE based approaches for the task of transfer learning, they are not as scalable as the latter. In this work we propose an AE based approach called Correlational Neural Network (CorrNet), that explicitly maximizes correlation among the views when projected to the common subspace. Through a series of experiments, we demonstrate that the proposed CorrNet is better than the above mentioned approaches with respect to its ability to learn correlated common representations. Further, we employ CorrNet for several cross language tasks and show that the representations learned using CorrNet perform better than the ones learned using other state of the art approaches.
Within-Brain Classification for Brain Tumor Segmentation
Oct 05, 2015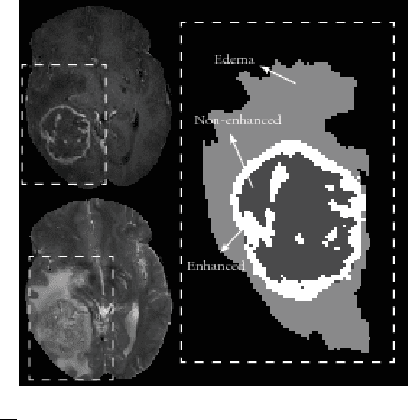

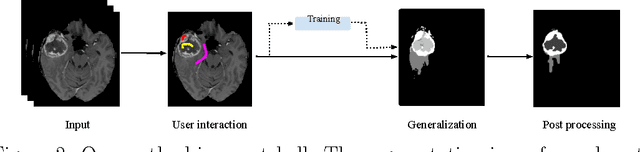
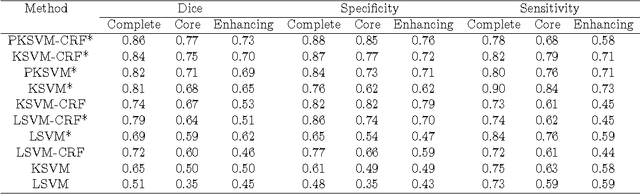
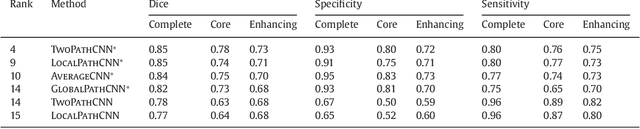
Purpose: In this paper, we investigate a framework for interactive brain tumor segmentation which, at its core, treats the problem of interactive brain tumor segmentation as a machine learning problem. Methods: This method has an advantage over typical machine learning methods for this task where generalization is made across brains. The problem with these methods is that they need to deal with intensity bias correction and other MRI-specific noise. In this paper, we avoid these issues by approaching the problem as one of within brain generalization. Specifically, we propose a semi-automatic method that segments a brain tumor by training and generalizing within that brain only, based on some minimum user interaction. Conclusion: We investigate how adding spatial feature coordinates (i.e. $i$, $j$, $k$) to the intensity features can significantly improve the performance of different classification methods such as SVM, kNN and random forests. This would only be possible within an interactive framework. We also investigate the use of a more appropriate kernel and the adaptation of hyper-parameters specifically for each brain. Results: As a result of these experiments, we obtain an interactive method whose results reported on the MICCAI-BRATS 2013 dataset are the second most accurate compared to published methods, while using significantly less memory and processing power than most state-of-the-art methods.
Describing Videos by Exploiting Temporal Structure
Oct 01, 2015
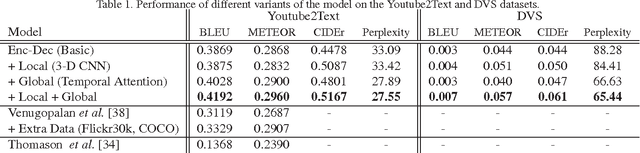
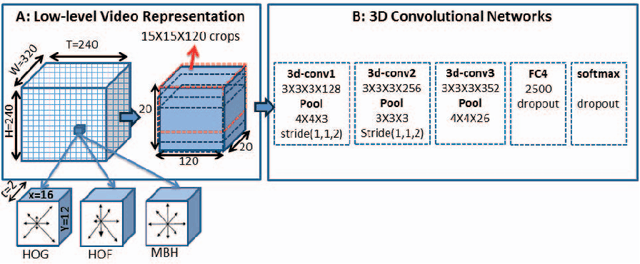
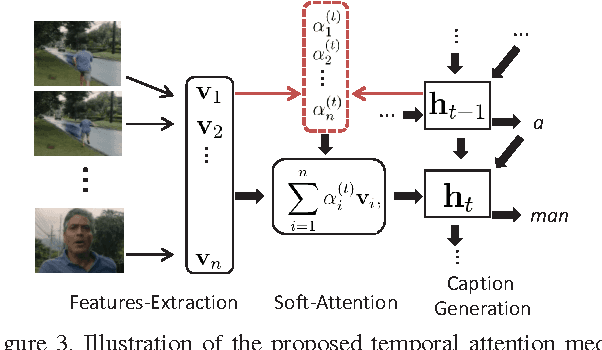
Recent progress in using recurrent neural networks (RNNs) for image description has motivated the exploration of their application for video description. However, while images are static, working with videos requires modeling their dynamic temporal structure and then properly integrating that information into a natural language description. In this context, we propose an approach that successfully takes into account both the local and global temporal structure of videos to produce descriptions. First, our approach incorporates a spatial temporal 3-D convolutional neural network (3-D CNN) representation of the short temporal dynamics. The 3-D CNN representation is trained on video action recognition tasks, so as to produce a representation that is tuned to human motion and behavior. Second we propose a temporal attention mechanism that allows to go beyond local temporal modeling and learns to automatically select the most relevant temporal segments given the text-generating RNN. Our approach exceeds the current state-of-art for both BLEU and METEOR metrics on the Youtube2Text dataset. We also present results on a new, larger and more challenging dataset of paired video and natural language descriptions.