 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Universal Template for Few-shot Dataset Generalization
May 14, 2021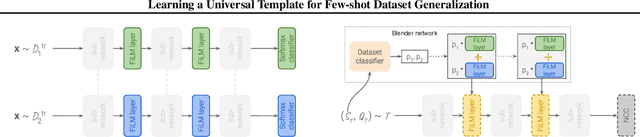
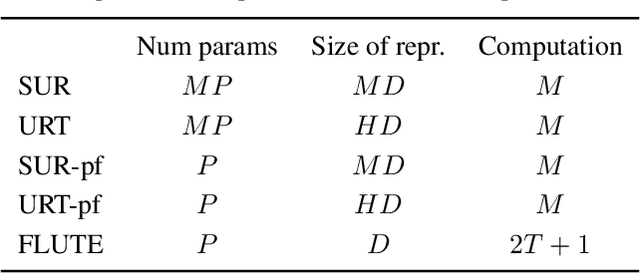
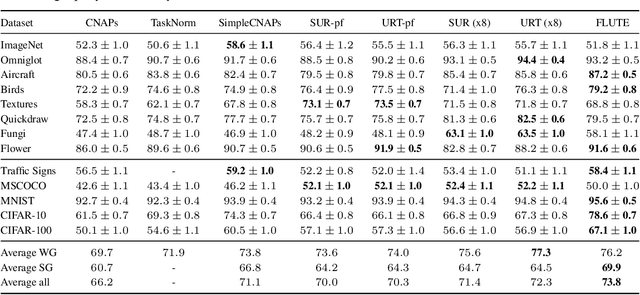

Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from new datasets using only a few examples. To this end, we propose to utilize the diverse training set to construct a universal template: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.
Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark
Apr 06, 2021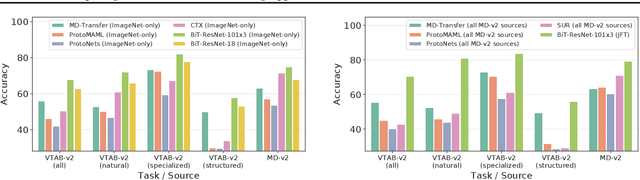
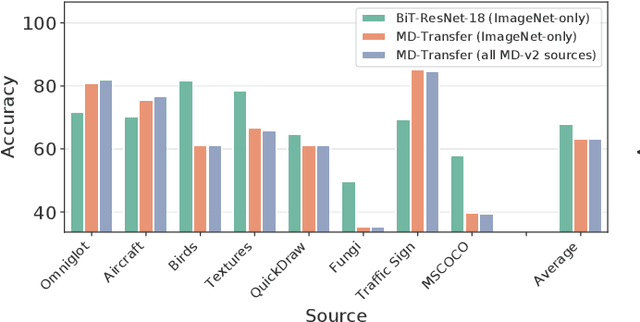

Meta and transfer learning are two successful families of approaches to few-shot learning. Despite highly related goals, state-of-the-art advances in each family are measured largely in isolation of each other. As a result of diverging evaluation norms, a direct or thorough comparison of different approaches is challenging. To bridge this gap, we perform a cross-family study of the best transfer and meta learners on both a large-scale meta-learning benchmark (Meta-Dataset, MD), and a transfer learning benchmark (Visual Task Adaptation Benchmark, VTAB). We find that, on average, large-scale transfer methods (Big Transfer, BiT) outperform competing approaches on MD, even when trained only on ImageNet. In contrast, meta-learning approaches struggle to compete on VTAB when trained and validated on MD. However, BiT is not without limitations, and pushing for scale does not improve performance on highly out-of-distribution MD tasks. In performing this study, we reveal a number of discrepancies in evaluation norms and study some of these in light of the performance gap. We hope that this work facilitates sharing of insights from each community, and accelerates progress on few-shot learning.
Interpretable Multi-Modal Hate Speech Detection
Mar 02, 2021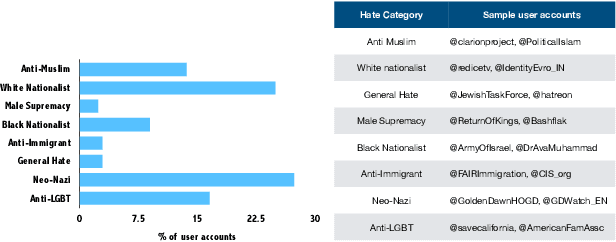

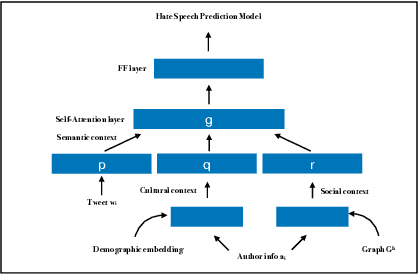
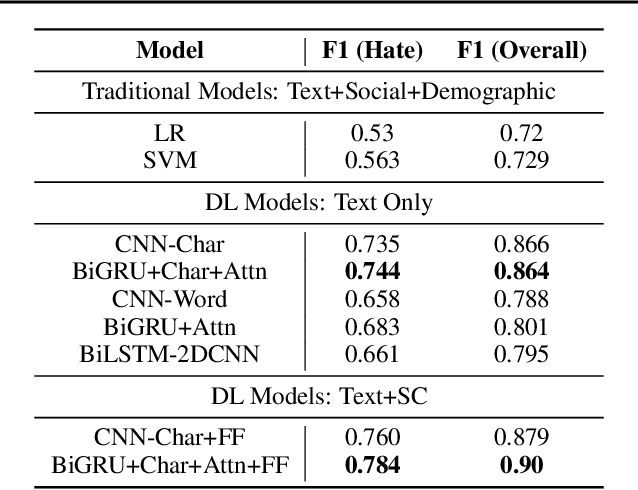
With growing role of social media in shaping public opinions and beliefs across the world, there has been an increased attention to identify and counter the problem of hate speech on social media. Hate speech on online spaces has serious manifestations, including social polarization and hate crimes. While prior works have proposed automated techniques to detect hate speech online, these techniques primarily fail to look beyond the textual content. Moreover, few attempts have been made to focus on the aspects of interpretability of such models given the social and legal implications of incorrect predictions. In this work, we propose a deep neural multi-modal model that can: (a) detect hate speech by effectively capturing the semantics of the text along with socio-cultural context in which a particular hate expression is made, and (b) provide interpretable insights into decisions of our model. By performing a thorough evaluation of different modeling techniques, we demonstrate that our model is able to outperform the existing state-of-the-art hate speech classification approaches. Finally, we show the importance of social and cultural context features towards unearthing clusters associated with different categories of hate.
* 5 pages, Accepted at the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, United States, 2019
Self-Supervised Equivariant Scene Synthesis from Video
Feb 01, 2021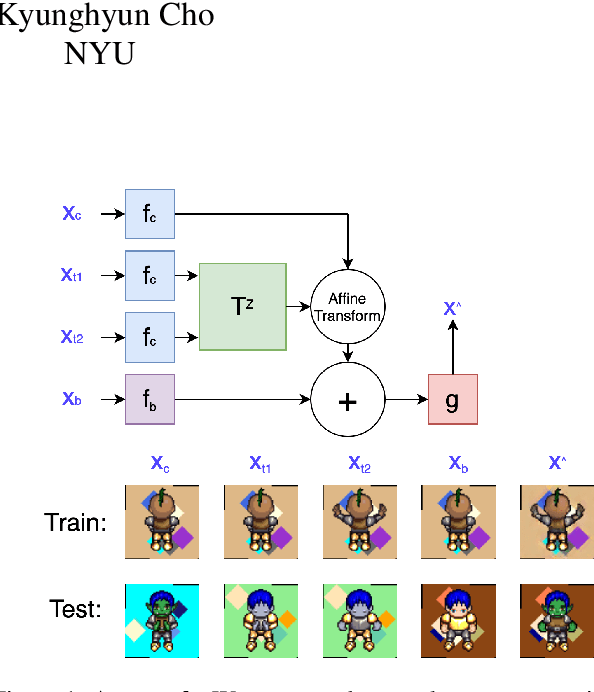
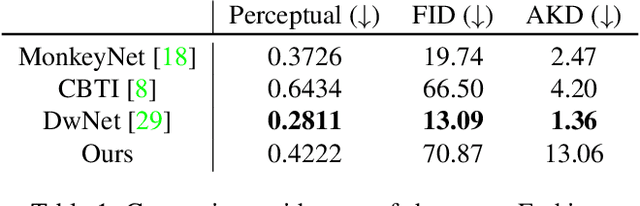
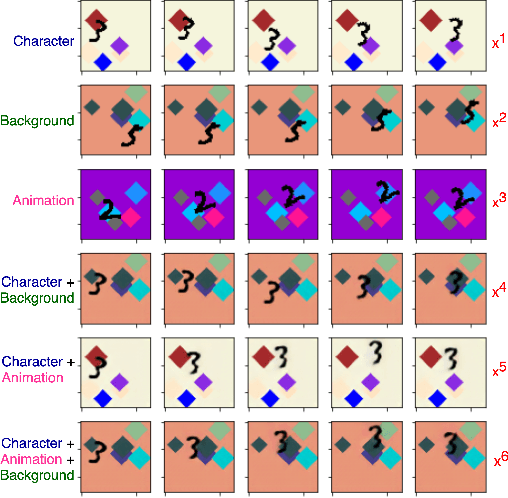
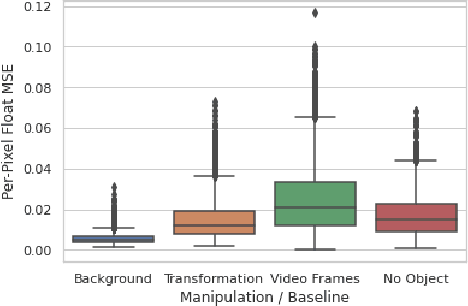
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into background, characters, and their animations. Our method capitalizes on moving characters being equivariant with respect to their transformation across frames and the background being constant with respect to that same transformation. After training, we can manipulate image encodings in real time to create unseen combinations of the delineated components. As far as we know, we are the first method to perform unsupervised extraction and synthesis of interpretable background, character, and animation. We demonstrate results on three datasets: Moving MNIST with backgrounds, 2D video game sprites, and Fashion Modeling.
An Effective Anti-Aliasing Approach for Residual Networks
Nov 20, 2020

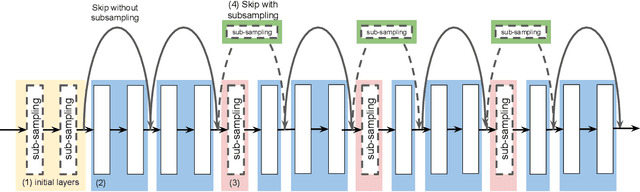

Image pre-processing in the frequency domain has traditionally played a vital role in computer vision and was even part of the standard pipeline in the early days of deep learning. However, with the advent of large datasets, many practitioners concluded that this was unnecessary due to the belief that these priors can be learned from the data itself. Frequency aliasing is a phenomenon that may occur when sub-sampling any signal, such as an image or feature map, causing distortion in the sub-sampled output. We show that we can mitigate this effect by placing non-trainable blur filters and using smooth activation functions at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in out-of-distribution generalization on both image classification under natural corruptions on ImageNet-C [10] and few-shot learning on Meta-Dataset [17], without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Learned Equivariant Rendering without Transformation Supervision
Nov 11, 2020


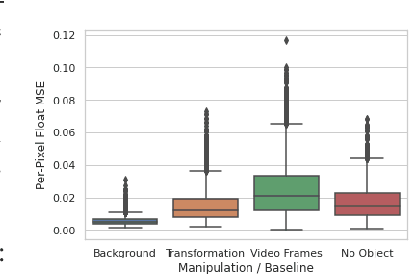
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into objects and background. Our method relies on moving objects being equivariant with respect to their transformation across frames and the background being constant. After training, we can manipulate and render the scenes in real time to create unseen combinations of objects, transformations, and backgrounds. We show results on moving MNIST with backgrounds.
Learning to Execute Programs with Instruction Pointer Attention Graph Neural Networks
Oct 23, 2020

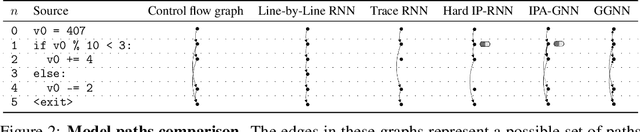
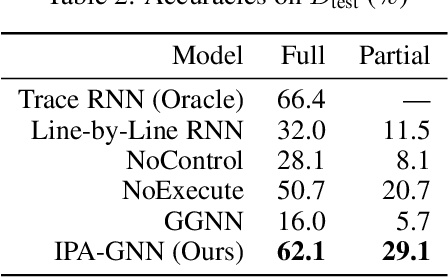
Graph neural networks (GNNs) have emerged as a powerful tool for learning software engineering tasks including code completion, bug finding, and program repair. They benefit from leveraging program structure like control flow graphs, but they are not well-suited to tasks like program execution that require far more sequential reasoning steps than number of GNN propagation steps. Recurrent neural networks (RNNs), on the other hand, are well-suited to long sequential chains of reasoning, but they do not naturally incorporate program structure and generally perform worse on the above tasks. Our aim is to achieve the best of both worlds, and we do so by introducing a novel GNN architecture, the Instruction Pointer Attention Graph Neural Networks (IPA-GNN), which achieves improved systematic generalization on the task of learning to execute programs using control flow graphs. The model arises by considering RNNs operating on program traces with branch decisions as latent variables. The IPA-GNN can be seen either as a continuous relaxation of the RNN model or as a GNN variant more tailored to execution. To test the models, we propose evaluating systematic generalization on learning to execute using control flow graphs, which tests sequential reasoning and use of program structure. More practically, we evaluate these models on the task of learning to execute partial programs, as might arise if using the model as a heuristic function in program synthesis. Results show that the IPA-GNN outperforms a variety of RNN and GNN baselines on both tasks.
Revisiting Fundamentals of Experience Replay
Jul 13, 2020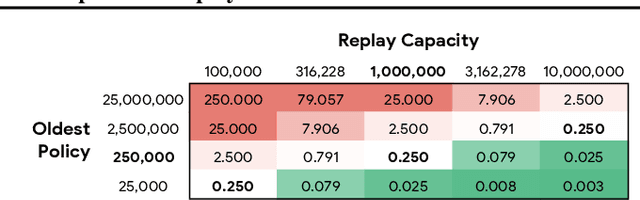

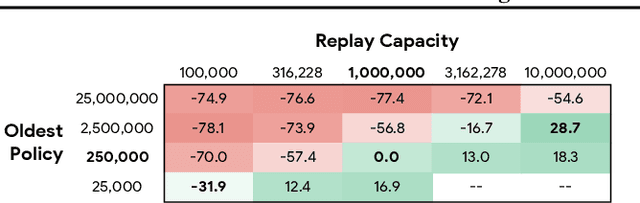
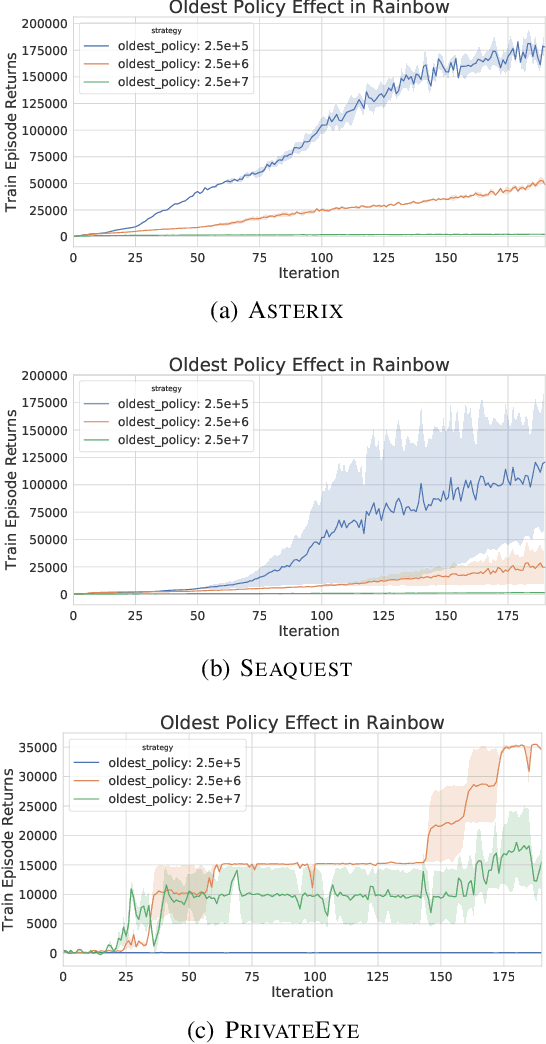
Experience replay is central to off-policy algorithms in deep reinforcement learning (RL), but there remain significant gaps in our understanding. We therefore present a systematic and extensive analysis of experience replay in Q-learning methods, focusing on two fundamental properties: the replay capacity and the ratio of learning updates to experience collected (replay ratio). Our additive and ablative studies upend conventional wisdom around experience replay -- greater capacity is found to substantially increase the performance of certain algorithms, while leaving others unaffected. Counterintuitively we show that theoretically ungrounded, uncorrected n-step returns are uniquely beneficial while other techniques confer limited benefit for sifting through larger memory. Separately, by directly controlling the replay ratio we contextualize previous observations in the literature and empirically measure its importance across a variety of deep RL algorithms. Finally, we conclude by testing a set of hypotheses on the nature of these performance benefits.
Learning Graph Structure With A Finite-State Automaton Layer
Jul 09, 2020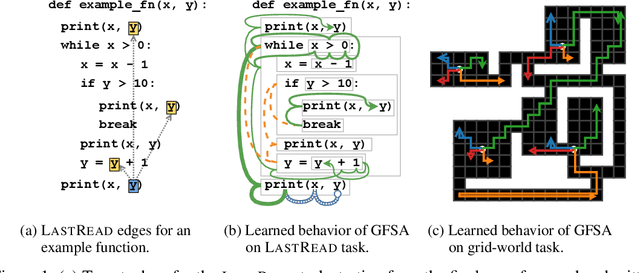
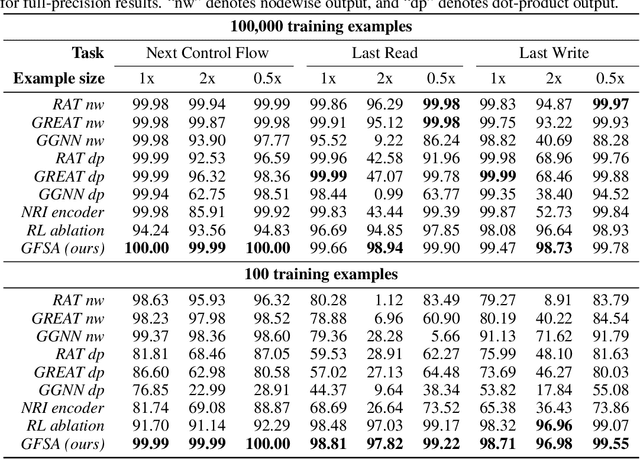
Graph-based neural network models are producing strong results in a number of domains, in part because graphs provide flexibility to encode domain knowledge in the form of relational structure (edges) between nodes in the graph. In practice, edges are used both to represent intrinsic structure (e.g., abstract syntax trees of programs) and more abstract relations that aid reasoning for a downstream task (e.g., results of relevant program analyses). In this work, we study the problem of learning to derive abstract relations from the intrinsic graph structure. Motivated by their power in program analyses, we consider relations defined by paths on the base graph accepted by a finite-state automaton. We show how to learn these relations end-to-end by relaxing the problem into learning finite-state automata policies on a graph-based POMDP and then training these policies using implicit differentiation. The result is a differentiable Graph Finite-State Automaton (GFSA) layer that adds a new edge type (expressed as a weighted adjacency matrix) to a base graph. We demonstrate that this layer can find shortcuts in grid-world graphs and reproduce simple static analyses on Python programs. Additionally, we combine the GFSA layer with a larger graph-based model trained end-to-end on the variable misuse program understanding task, and find that using the GFSA layer leads to better performance than using hand-engineered semantic edges or other baseline methods for adding learned edge types.
A Universal Representation Transformer Layer for Few-Shot Image Classification
Jun 25, 2020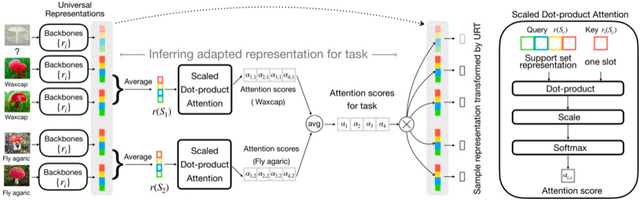
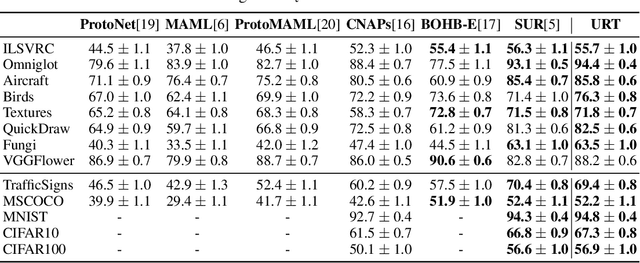
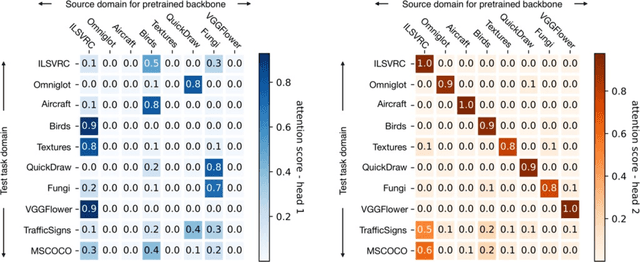
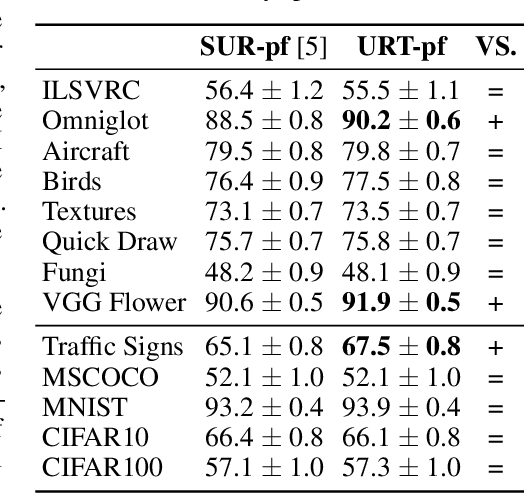
Few-shot classification aims to recognize unseen classes when presented with only a small number of samples. We consider the problem of multi-domain few-shot image classification, where unseen classes and examples come from diverse data sources. This problem has seen growing interest and has inspired the development of benchmarks such as Meta-Dataset. A key challenge in this multi-domain setting is to effectively integrate the feature representations from the diverse set of training domains. Here, we propose a Universal Representation Transformer (URT) layer, that meta-learns to leverage universal features for few-shot classification by dynamically re-weighting and composing the most appropriate domain-specific representations. In experiments, we show that URT sets a new state-of-the-art result on Meta-Dataset. Specifically, it outperforms the best previous model on three data sources or performs the same in others. We analyze variants of URT and present a visualization of the attention score heatmaps that sheds light on how the model performs cross-domain generalization. Our code is available at https://github.com/liulu112601/URT.