 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Frustratingly Simple Decoding Method for Neural Text Generation
May 22, 2023We introduce a frustratingly simple, super efficient and surprisingly effective decoding method, which we call Frustratingly Simple Decoding (FSD), for neural text generation. The idea behind FSD is straightforward: we build an anti-LM based on previously generated text and use this anti-LM to penalize future generation of what has been generated. The anti-LM can be implemented as simple as an n-gram language model or a vectorized variant. In this way, FSD introduces no extra model parameters and negligible computational overhead (FSD can be as fast as greedy search). Despite the simplicity, FSD is surprisingly effective; Experiments show that FSD can outperform the canonical methods to date (i.e., nucleus sampling) as well as several strong baselines that were proposed recently.
Unified Text Structuralization with Instruction-tuned Language Models
Mar 30, 2023Text structuralization is one of the important fields of natural language processing (NLP) consists of information extraction (IE) and structure formalization. However, current studies of text structuralization suffer from a shortage of manually annotated high-quality datasets from different domains and languages, which require specialized professional knowledge. In addition, most IE methods are designed for a specific type of structured data, e.g., entities, relations, and events, making them hard to generalize to others. In this work, we propose a simple and efficient approach to instruct large language model (LLM) to extract a variety of structures from texts. More concretely, we add a prefix and a suffix instruction to indicate the desired IE task and structure type, respectively, before feeding the text into a LLM. Experiments on two LLMs show that this approach can enable language models to perform comparable with other state-of-the-art methods on datasets of a variety of languages and knowledge, and can generalize to other IE sub-tasks via changing the content of instruction. Another benefit of our approach is that it can help researchers to build datasets in low-source and domain-specific scenarios, e.g., fields in finance and law, with low cost.
$N$-gram Is Back: Residual Learning of Neural Text Generation with $n$-gram Language Model
Nov 03, 2022$N$-gram language models (LM) have been largely superseded by neural LMs as the latter exhibits better performance. However, we find that $n$-gram models can achieve satisfactory performance on a large proportion of testing cases, indicating they have already captured abundant knowledge of the language with relatively low computational cost. With this observation, we propose to learn a neural LM that fits the residual between an $n$-gram LM and the real-data distribution. The combination of $n$-gram and neural LMs not only allows the neural part to focus on the deeper understanding of language but also provides a flexible way to customize an LM by switching the underlying $n$-gram model without changing the neural model. Experimental results on three typical language tasks (i.e., language modeling, machine translation, and summarization) demonstrate that our approach attains additional performance gains over popular standalone neural models consistently. We also show that our approach allows for effective domain adaptation by simply switching to a domain-specific $n$-gram model, without any extra training. Our code is released at https://github.com/ghrua/NgramRes.
Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation
Jun 06, 2022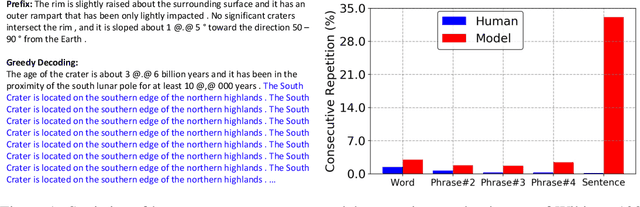
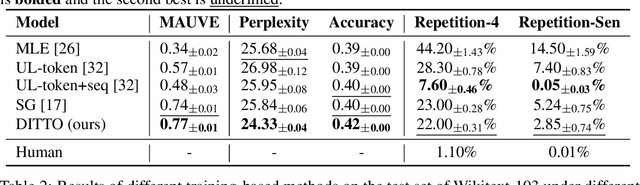
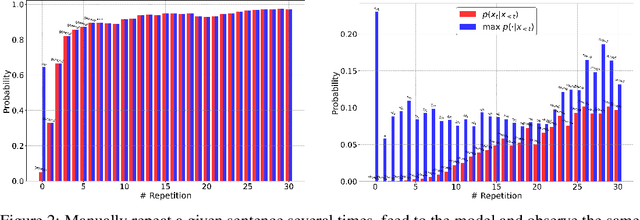
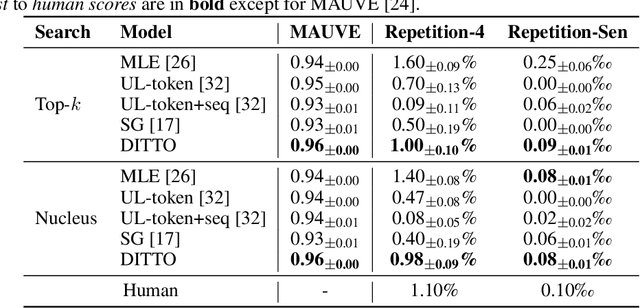
While large-scale neural language models, such as GPT2 and BART, have achieved impressive results on various text generation tasks, they tend to get stuck in undesirable sentence-level loops with maximization-based decoding algorithms (\textit{e.g.}, greedy search). This phenomenon is counter-intuitive since there are few consecutive sentence-level repetitions in human corpora (e.g., 0.02\% in Wikitext-103). To investigate the underlying reasons for generating consecutive sentence-level repetitions, we study the relationship between the probabilities of the repetitive tokens and their previous repetitions in the context. Through our quantitative experiments, we find that 1) Language models have a preference to repeat the previous sentence; 2) The sentence-level repetitions have a \textit{self-reinforcement effect}: the more times a sentence is repeated in the context, the higher the probability of continuing to generate that sentence; 3) The sentences with higher initial probabilities usually have a stronger self-reinforcement effect. Motivated by our findings, we propose a simple and effective training method \textbf{DITTO} (Pseu\underline{D}o-Repet\underline{IT}ion Penaliza\underline{T}i\underline{O}n), where the model learns to penalize probabilities of sentence-level repetitions from pseudo repetitive data. Although our method is motivated by mitigating repetitions, experiments show that DITTO not only mitigates the repetition issue without sacrificing perplexity, but also achieves better generation quality. Extensive experiments on open-ended text generation (Wikitext-103) and text summarization (CNN/DailyMail) demonstrate the generality and effectiveness of our method.
Visualizing the Relationship Between Encoded Linguistic Information and Task Performance
Mar 29, 2022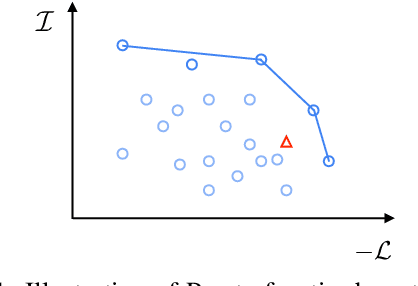
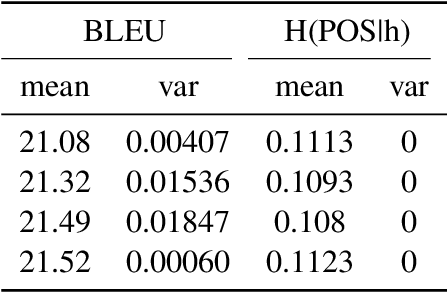
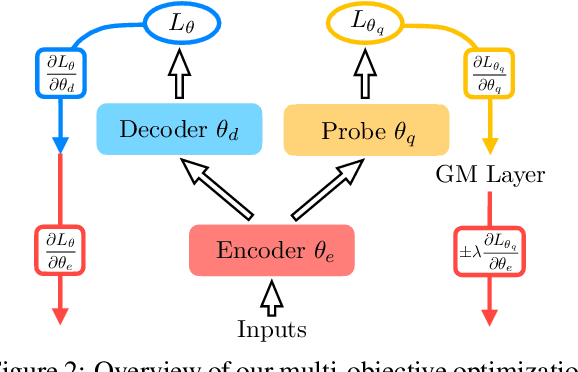
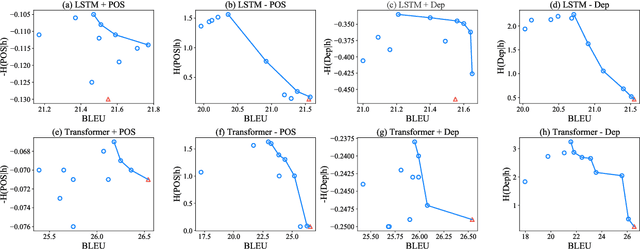
Probing is popular to analyze whether linguistic information can be captured by a well-trained deep neural model, but it is hard to answer how the change of the encoded linguistic information will affect task performance. To this end, we study the dynamic relationship between the encoded linguistic information and task performance from the viewpoint of Pareto Optimality. Its key idea is to obtain a set of models which are Pareto-optimal in terms of both objectives. From this viewpoint, we propose a method to optimize the Pareto-optimal models by formalizing it as a multi-objective optimization problem. We conduct experiments on two popular NLP tasks, i.e., machine translation and language modeling, and investigate the relationship between several kinds of linguistic information and task performances. Experimental results demonstrate that the proposed method is better than a baseline method. Our empirical findings suggest that some syntactic information is helpful for NLP tasks whereas encoding more syntactic information does not necessarily lead to better performance, because the model architecture is also an important factor.
Investigating Data Variance in Evaluations of Automatic Machine Translation Metrics
Mar 29, 2022
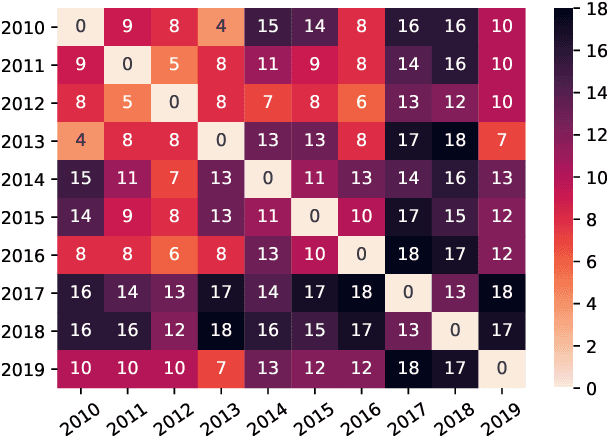
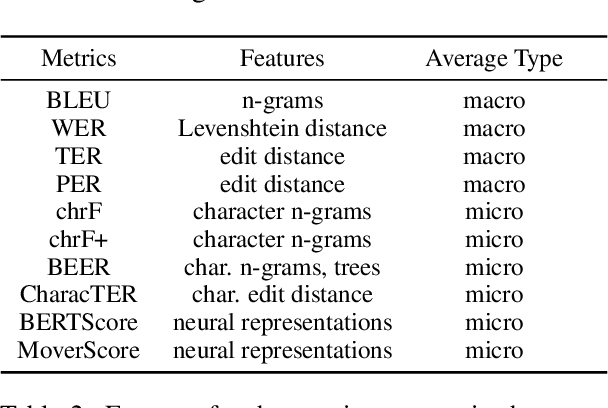
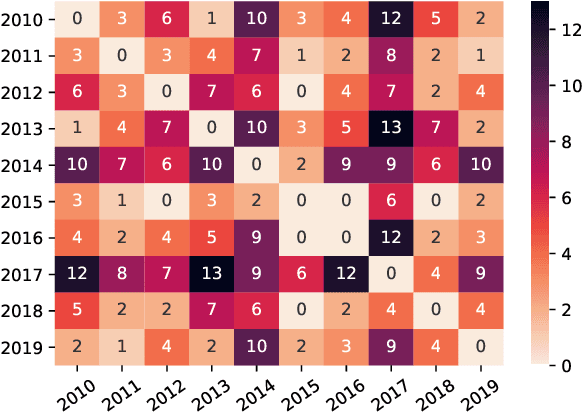
Current practices in metric evaluation focus on one single dataset, e.g., Newstest dataset in each year's WMT Metrics Shared Task. However, in this paper, we qualitatively and quantitatively show that the performances of metrics are sensitive to data. The ranking of metrics varies when the evaluation is conducted on different datasets. Then this paper further investigates two potential hypotheses, i.e., insignificant data points and the deviation of Independent and Identically Distributed (i.i.d) assumption, which may take responsibility for the issue of data variance. In conclusion, our findings suggest that when evaluating automatic translation metrics, researchers should take data variance into account and be cautious to claim the result on a single dataset, because it may leads to inconsistent results with most of other datasets.
A Survey on Retrieval-Augmented Text Generation
Feb 13, 2022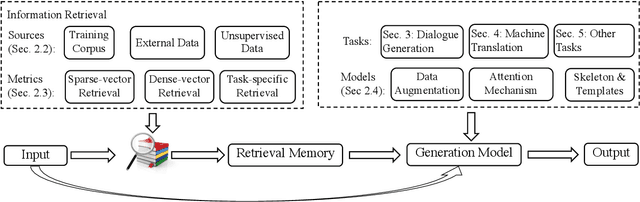
Recently, retrieval-augmented text generation attracted increasing attention of the computational linguistics community. Compared with conventional generation models, retrieval-augmented text generation has remarkable advantages and particularly has achieved state-of-the-art performance in many NLP tasks. This paper aims to conduct a survey about retrieval-augmented text generation. It firstly highlights the generic paradigm of retrieval-augmented generation, and then it reviews notable approaches according to different tasks including dialogue response generation, machine translation, and other generation tasks. Finally, it points out some important directions on top of recent methods to facilitate future research.
Neural Machine Translation with Monolingual Translation Memory
Jun 02, 2021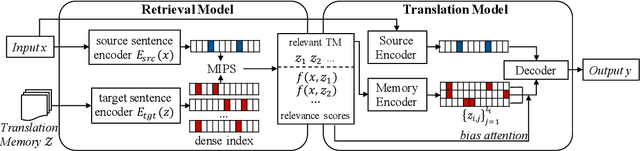
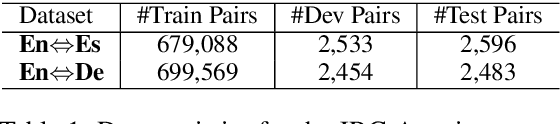
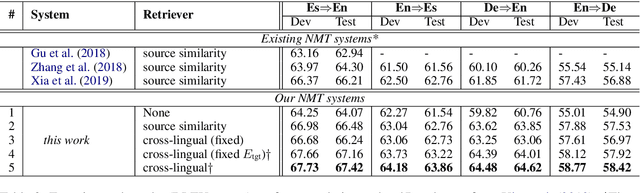
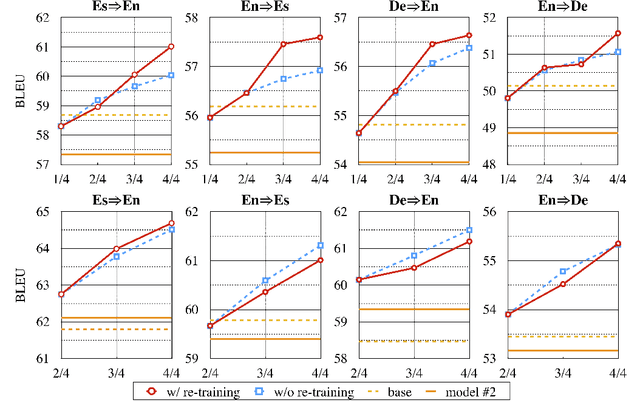
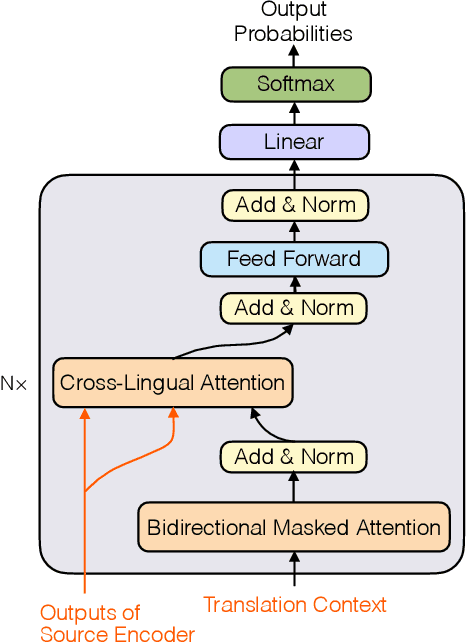
Prior work has proved that Translation memory (TM) can boost the performance of Neural Machine Translation (NMT). In contrast to existing work that uses bilingual corpus as TM and employs source-side similarity search for memory retrieval, we propose a new framework that uses monolingual memory and performs learnable memory retrieval in a cross-lingual manner. Our framework has unique advantages. First, the cross-lingual memory retriever allows abundant monolingual data to be TM. Second, the memory retriever and NMT model can be jointly optimized for the ultimate translation goal. Experiments show that the proposed method obtains substantial improvements. Remarkably, it even outperforms strong TM-augmented NMT baselines using bilingual TM. Owning to the ability to leverage monolingual data, our model also demonstrates effectiveness in low-resource and domain adaptation scenarios.
GWLAN: General Word-Level AutocompletioN for Computer-Aided Translation
May 31, 2021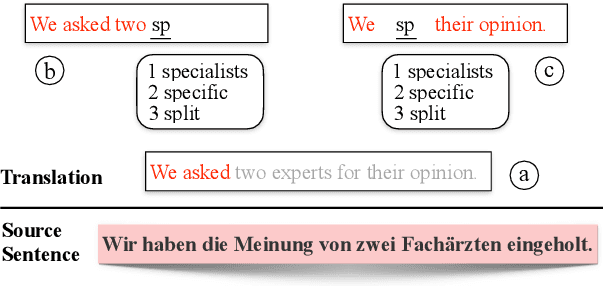
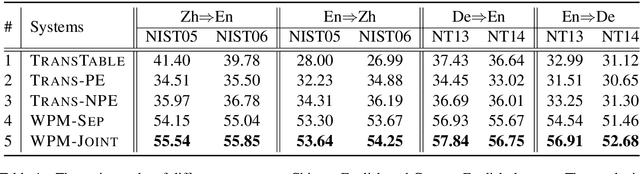
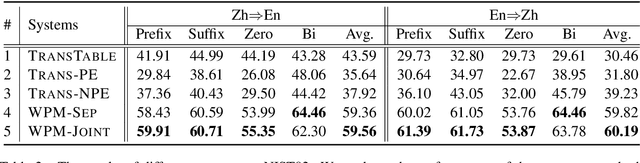
Computer-aided translation (CAT), the use of software to assist a human translator in the translation process, has been proven to be useful in enhancing the productivity of human translators. Autocompletion, which suggests translation results according to the text pieces provided by human translators, is a core function of CAT. There are two limitations in previous research in this line. First, most research works on this topic focus on sentence-level autocompletion (i.e., generating the whole translation as a sentence based on human input), but word-level autocompletion is under-explored so far. Second, almost no public benchmarks are available for the autocompletion task of CAT. This might be among the reasons why research progress in CAT is much slower compared to automatic MT. In this paper, we propose the task of general word-level autocompletion (GWLAN) from a real-world CAT scenario, and construct the first public benchmark to facilitate research in this topic. In addition, we propose an effective method for GWLAN and compare it with several strong baselines. Experiments demonstrate that our proposed method can give significantly more accurate predictions than the baseline methods on our benchmark datasets.
Data Augmentation for Text Generation Without Any Augmented Data
May 28, 2021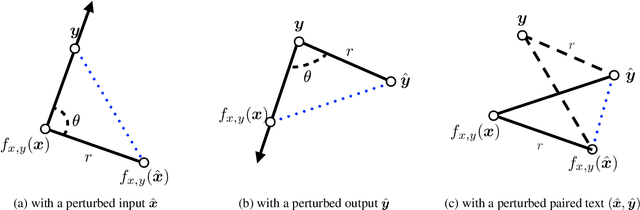
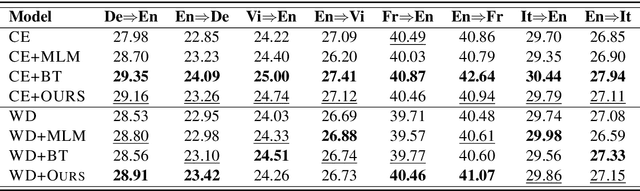
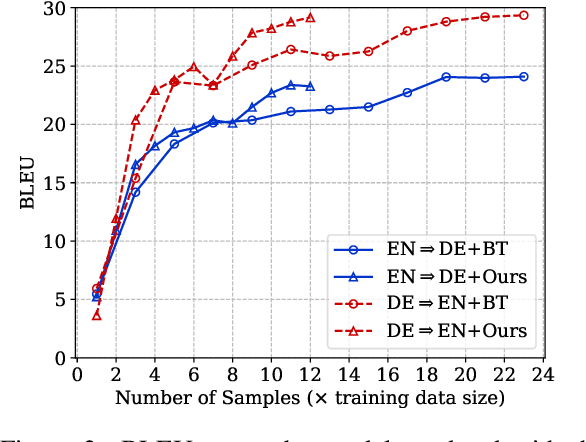
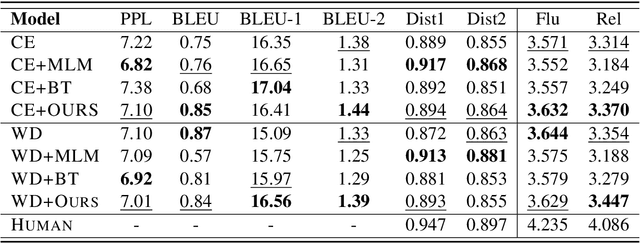
Data augmentation is an effective way to improve the performance of many neural text generation models. However, current data augmentation methods need to define or choose proper data mapping functions that map the original samples into the augmented samples. In this work, we derive an objective to formulate the problem of data augmentation on text generation tasks without any use of augmented data constructed by specific mapping functions. Our proposed objective can be efficiently optimized and applied to popular loss functions on text generation tasks with a convergence rate guarantee. Experiments on five datasets of two text generation tasks show that our approach can approximate or even surpass popular data augmentation methods.