 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-HyPO: An Adaptive Private Hyperparameter Optimization Framework
Jun 09, 2023



Hyperparameter optimization, also known as hyperparameter tuning, is a widely recognized technique for improving model performance. Regrettably, when training private ML models, many practitioners often overlook the privacy risks associated with hyperparameter optimization, which could potentially expose sensitive information about the underlying dataset. Currently, the sole existing approach to allow privacy-preserving hyperparameter optimization is to uniformly and randomly select hyperparameters for a number of runs, subsequently reporting the best-performing hyperparameter. In contrast, in non-private settings, practitioners commonly utilize "adaptive" hyperparameter optimization methods such as Gaussian process-based optimization, which select the next candidate based on information gathered from previous outputs. This substantial contrast between private and non-private hyperparameter optimization underscores a critical concern. In our paper, we introduce DP-HyPO, a pioneering framework for "adaptive" private hyperparameter optimization, aiming to bridge the gap between private and non-private hyperparameter optimization. To accomplish this, we provide a comprehensive differential privacy analysis of our framework. Furthermore, we empirically demonstrate the effectiveness of DP-HyPO on a diverse set of real-world and synthetic datasets.
A Lite Fireworks Algorithm with Fractal Dimension Constraint for Feature Selection
Mar 09, 2023As the use of robotics becomes more widespread, the huge amount of vision data leads to a dramatic increase in data dimensionality. Although deep learning methods can effectively process these high-dimensional vision data. Due to the limitation of computational resources, some special scenarios still rely on traditional machine learning methods. However, these high-dimensional visual data lead to great challenges for traditional machine learning methods. Therefore, we propose a Lite Fireworks Algorithm with Fractal Dimension constraint for feature selection (LFWA+FD) and use it to solve the feature selection problem driven by robot vision. The "LFWA+FD" focuses on searching the ideal feature subset by simplifying the fireworks algorithm and constraining the dimensionality of selected features by fractal dimensionality, which in turn reduces the approximate features and reduces the noise in the original data to improve the accuracy of the model. The comparative experimental results of two publicly available datasets from UCI show that the proposed method can effectively select a subset of features useful for model inference and remove a large amount of noise noise present in the original data to improve the performance.
Deep-Learning-Based Computer Vision Approach For The Segmentation Of Ball Deliveries And Tracking In Cricket
Nov 22, 2022



There has been a significant increase in the adoption of technology in cricket recently. This trend has created the problem of duplicate work being done in similar computer vision-based research works. Our research tries to solve one of these problems by segmenting ball deliveries in a cricket broadcast using deep learning models, MobileNet and YOLO, thus enabling researchers to use our work as a dataset for their research. The output from our research can be used by cricket coaches and players to analyze ball deliveries which are played during the match. This paper presents an approach to segment and extract video shots in which only the ball is being delivered. The video shots are a series of continuous frames that make up the whole scene of the video. Object detection models are applied to reach a high level of accuracy in terms of correctly extracting video shots. The proof of concept for building large datasets of video shots for ball deliveries is proposed which paves the way for further processing on those shots for the extraction of semantics. Ball tracking in these video shots is also done using a separate RetinaNet model as a sample of the usefulness of the proposed dataset. The position on the cricket pitch where the ball lands is also extracted by tracking the ball along the y-axis. The video shot is then classified as a full-pitched, good-length or short-pitched delivery.
SMiLE: Schema-augmented Multi-level Contrastive Learning for Knowledge Graph Link Prediction
Oct 10, 2022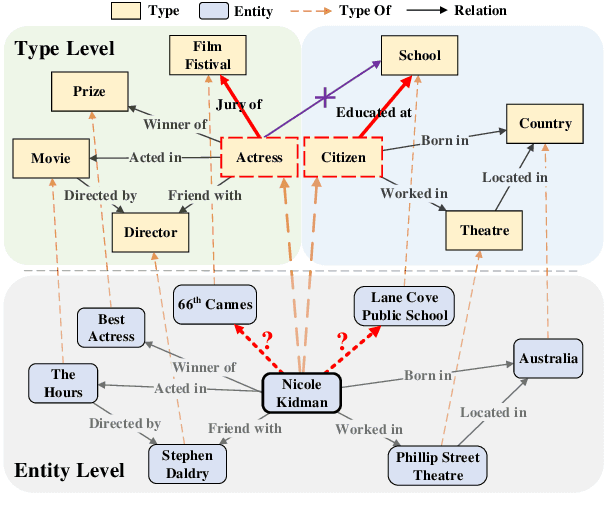
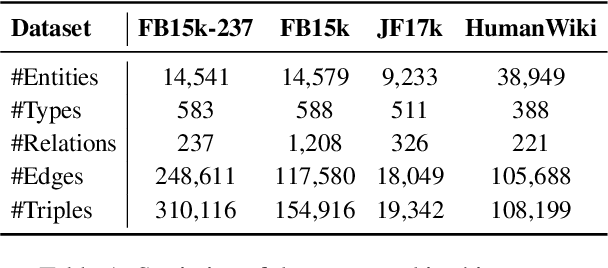
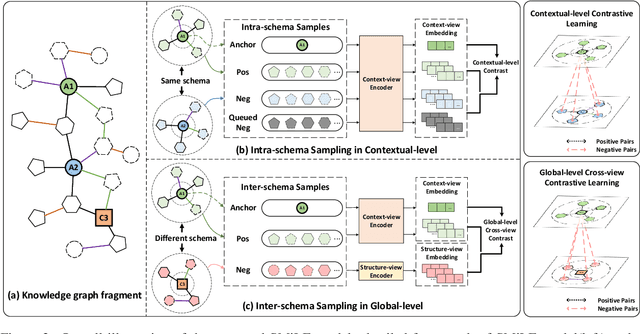
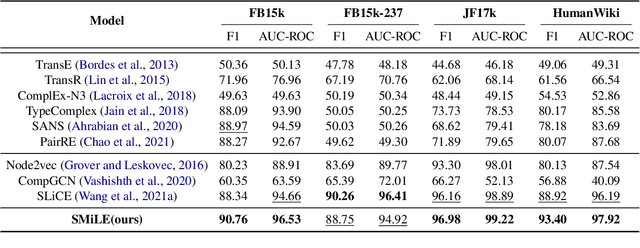
Link prediction is the task of inferring missing links between entities in knowledge graphs. Embedding-based methods have shown effectiveness in addressing this problem by modeling relational patterns in triples. However, the link prediction task often requires contextual information in entity neighborhoods, while most existing embedding-based methods fail to capture it. Additionally, little attention is paid to the diversity of entity representations in different contexts, which often leads to false prediction results. In this situation, we consider that the schema of knowledge graph contains the specific contextual information, and it is beneficial for preserving the consistency of entities across contexts. In this paper, we propose a novel schema-augmented multi-level contrastive learning framework (SMiLE) to conduct knowledge graph link prediction. Specifically, we first exploit network schema as the prior constraint to sample negatives and pre-train our model by employing a multi-level contrastive learning method to yield both prior schema and contextual information. Then we fine-tune our model under the supervision of individual triples to learn subtler representations for link prediction. Extensive experimental results on four knowledge graph datasets with thorough analysis of each component demonstrate the effectiveness of our proposed framework against state-of-the-art baselines.
SLAM-TKA: Real-time Intra-operative Measurement of Tibial Resection Plane in Conventional Total Knee Arthroplasty
Aug 08, 2022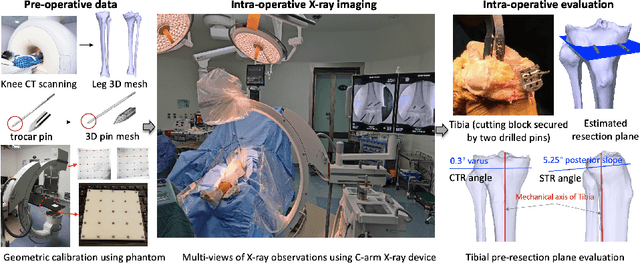
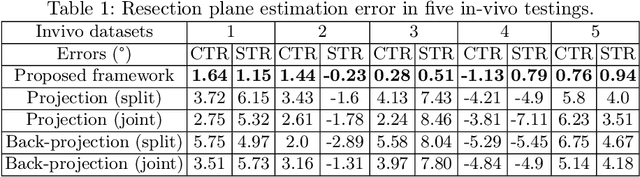
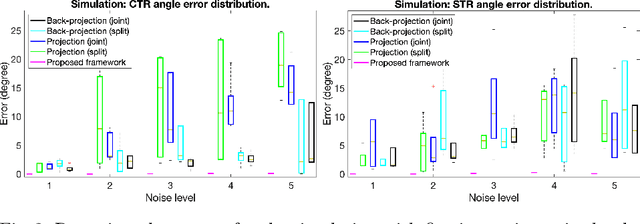
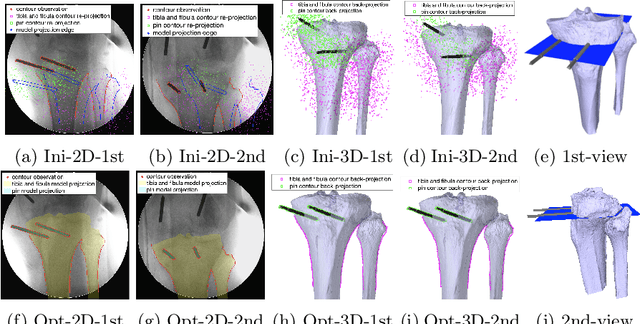
Total knee arthroplasty (TKA) is a common orthopaedic surgery to replace a damaged knee joint with artificial implants. The inaccuracy of achieving the planned implant position can result in the risk of implant component aseptic loosening, wear out, and even a joint revision, and those failures most of the time occur on the tibial side in the conventional jig-based TKA (CON-TKA). This study aims to precisely evaluate the accuracy of the proximal tibial resection plane intra-operatively in real-time such that the evaluation processing changes very little on the CON-TKA operative procedure. Two X-ray radiographs captured during the proximal tibial resection phase together with a pre-operative patient-specific tibia 3D mesh model segmented from computed tomography (CT) scans and a trocar pin 3D mesh model are used in the proposed simultaneous localisation and mapping (SLAM) system to estimate the proximal tibial resection plane. Validations using both simulation and in-vivo datasets are performed to demonstrate the robustness and the potential clinical value of the proposed algorithm.
Analytical Composition of Differential Privacy via the Edgeworth Accountant
Jun 09, 2022

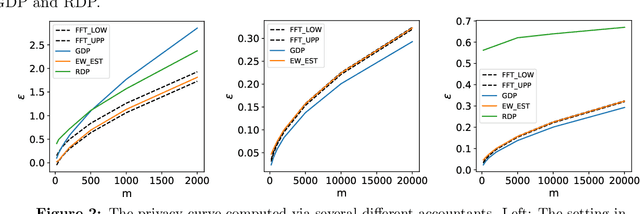
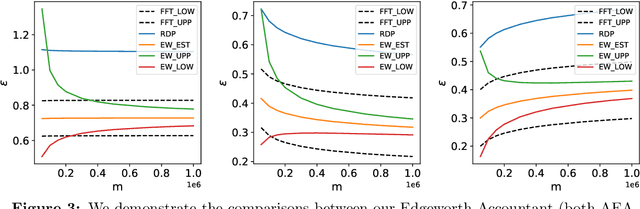
Many modern machine learning algorithms are composed of simple private algorithms; thus, an increasingly important problem is to efficiently compute the overall privacy loss under composition. In this study, we introduce the Edgeworth Accountant, an analytical approach to composing differential privacy guarantees of private algorithms. The Edgeworth Accountant starts by losslessly tracking the privacy loss under composition using the $f$-differential privacy framework, which allows us to express the privacy guarantees using privacy-loss log-likelihood ratios (PLLRs). As the name suggests, this accountant next uses the Edgeworth expansion to the upper and lower bounds the probability distribution of the sum of the PLLRs. Moreover, by relying on a technique for approximating complex distributions using simple ones, we demonstrate that the Edgeworth Accountant can be applied to the composition of any noise-addition mechanism. Owing to certain appealing features of the Edgeworth expansion, the $(\epsilon, \delta)$-differential privacy bounds offered by this accountant are non-asymptotic, with essentially no extra computational cost, as opposed to the prior approaches in, wherein the running times increase with the number of compositions. Finally, we demonstrate that our upper and lower $(\epsilon, \delta)$-differential privacy bounds are tight in federated analytics and certain regimes of training private deep learning models.
Deep Learning Assisted End-to-End Synthesis of mm-Wave Passive Networks with 3D EM Structures: A Study on A Transformer-Based Matching Network
Jan 06, 2022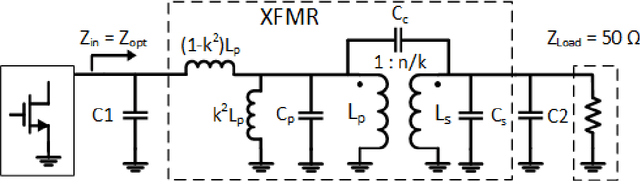
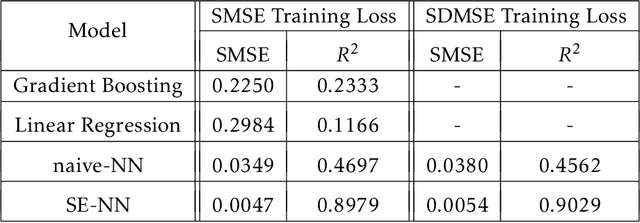
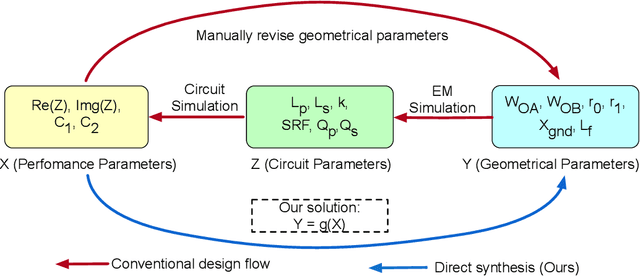
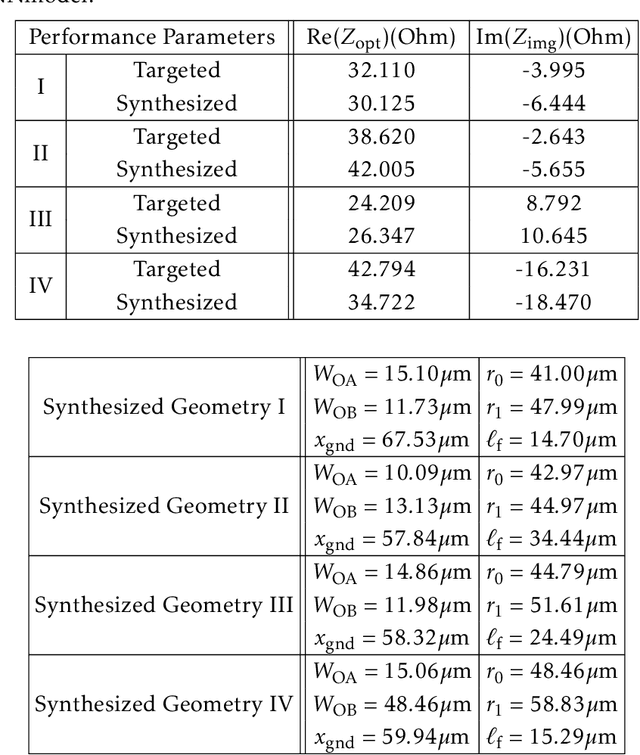
This paper presents a deep learning assisted synthesis approach for direct end-to-end generation of RF/mm-wave passive matching network with 3D EM structures. Different from prior approaches that synthesize EM structures from target circuit component values and target topologies, our proposed approach achieves the direct synthesis of the passive network given the network topology from desired performance values as input. We showcase the proposed synthesis Neural Network (NN) model on an on-chip 1:1 transformer-based impedance matching network. By leveraging parameter sharing, the synthesis NN model successfully extracts relevant features from the input impedance and load capacitors, and predict the transformer 3D EM geometry in a 45nm SOI process that will match the standard 50$\Omega$ load to the target input impedance while absorbing the two loading capacitors. As a proof-of-concept, several example transformer geometries were synthesized, and verified in Ansys HFSS to provide the desired input impedance.
Imitating Deep Learning Dynamics via Locally Elastic Stochastic Differential Equations
Oct 11, 2021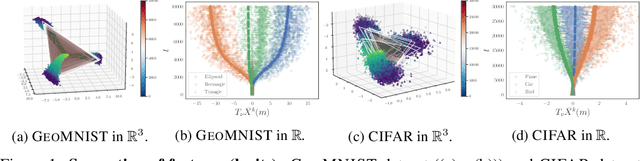
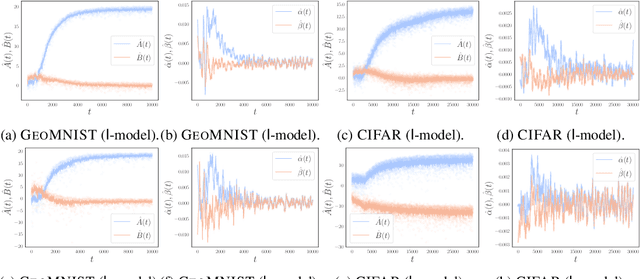
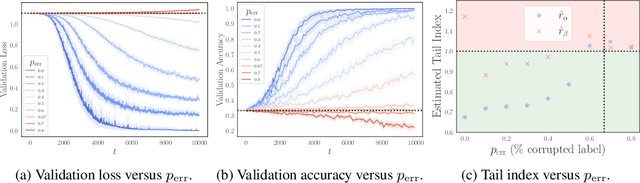
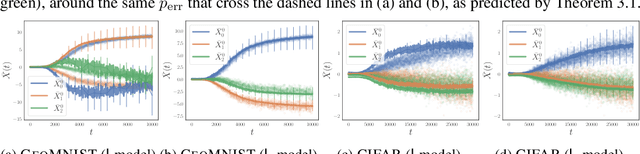
Understanding the training dynamics of deep learning models is perhaps a necessary step toward demystifying the effectiveness of these models. In particular, how do data from different classes gradually become separable in their feature spaces when training neural networks using stochastic gradient descent? In this study, we model the evolution of features during deep learning training using a set of stochastic differential equations (SDEs) that each corresponds to a training sample. As a crucial ingredient in our modeling strategy, each SDE contains a drift term that reflects the impact of backpropagation at an input on the features of all samples. Our main finding uncovers a sharp phase transition phenomenon regarding the {intra-class impact: if the SDEs are locally elastic in the sense that the impact is more significant on samples from the same class as the input, the features of the training data become linearly separable, meaning vanishing training loss; otherwise, the features are not separable, regardless of how long the training time is. Moreover, in the presence of local elasticity, an analysis of our SDEs shows that the emergence of a simple geometric structure called the neural collapse of the features. Taken together, our results shed light on the decisive role of local elasticity in the training dynamics of neural networks. We corroborate our theoretical analysis with experiments on a synthesized dataset of geometric shapes and CIFAR-10.
Angle Estimation for Terahertz Ultra-Massive MIMO-Based Space-to-Air Communications
Aug 02, 2021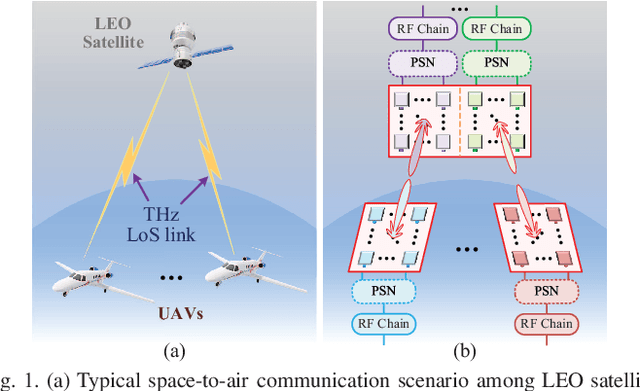
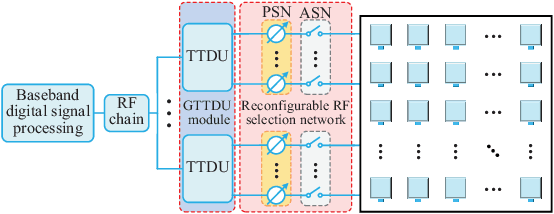
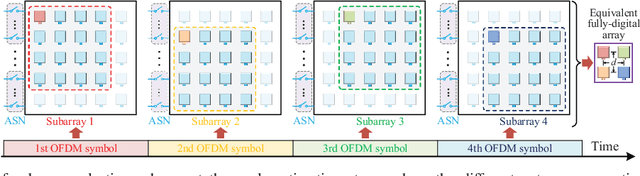
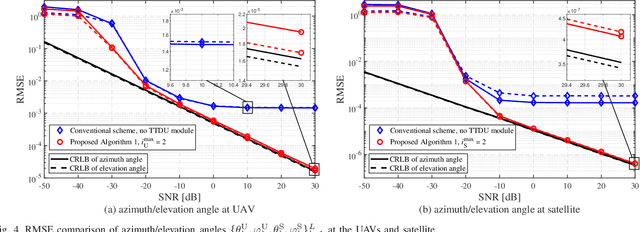
This paper investigates terahertz ultra-massive (UM)-MIMO-based angle estimation for space-to-air communications, which can solve the performance degradation problem caused by the dual delay-beam squint effects of terahertz UM-MIMO channels. Specifically, we first design a grouping true-time delay unit module that can significantly mitigate the impact of delay-beam squint effects to establish the space-to-air THz link. Based on the subarray selection scheme, the UM hybrid array can be equivalently considered as a low-dimensional fully-digital array, and then the fine estimates of azimuth/elevation angles at both UAVs and satellite can be separately acquired using the proposed prior-aided iterative angle estimation algorithm. The simulation results that close to Cram\'{e}r-Rao lower bounds verify the effectiveness of our solution.
On the Convergence of Deep Learning with Differential Privacy
Jun 15, 2021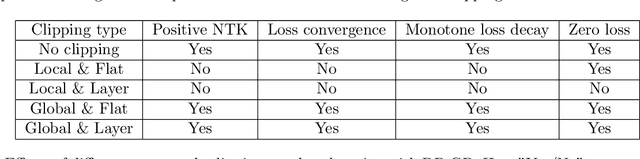
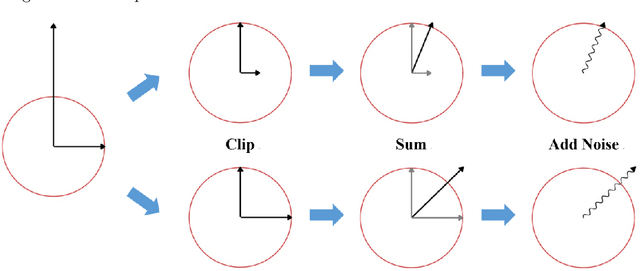
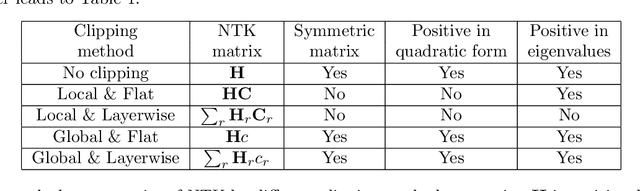
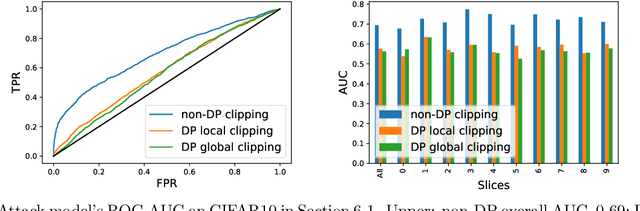
In deep learning with differential privacy (DP), the neural network achieves the privacy usually at the cost of slower convergence (and thus lower performance) than its non-private counterpart. This work gives the first convergence analysis of the DP deep learning, through the lens of training dynamics and the neural tangent kernel (NTK). Our convergence theory successfully characterizes the effects of two key components in the DP training: the per-sample clipping (flat or layerwise) and the noise addition. Our analysis not only initiates a general principled framework to understand the DP deep learning with any network architecture and loss function, but also motivates a new clipping method -- the global clipping, that significantly improves the convergence while preserving the same privacy guarantee as the existing local clipping. In terms of theoretical results, we establish the precise connection between the per-sample clipping and NTK matrix. We show that in the gradient flow, i.e., with infinitesimal learning rate, the noise level of DP optimizers does not affect the convergence. We prove that DP gradient descent (GD) with global clipping guarantees the monotone convergence to zero loss, which can be violated by the existing DP-GD with local clipping. Notably, our analysis framework easily extends to other optimizers, e.g., DP-Adam. Empirically speaking, DP optimizers equipped with global clipping perform strongly on a wide range of classification and regression tasks. In particular, our global clipping is surprisingly effective at learning calibrated classifiers, in contrast to the existing DP classifiers which are oftentimes over-confident and unreliable. Implementation-wise, the new clipping can be realized by adding one line of code into the Opacus library.