 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Facial Expression Transfer via Fine-Grained Semantic Representations
Sep 06, 2019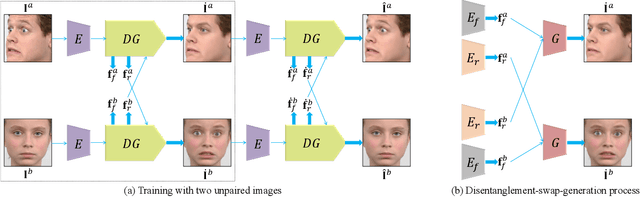

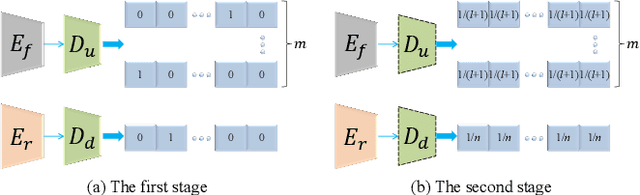
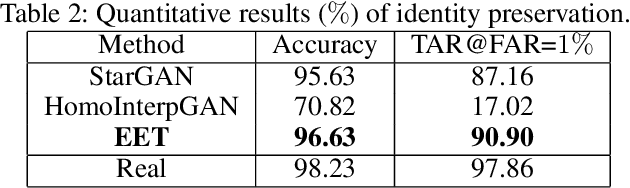
Facial expression transfer between two unpaired images is a challenging problem, as fine-grained expressions are typically tangled with other facial attributes such as identity and pose. Most existing methods treat expression transfer as an application of expression manipulation, and use predicted facial expressions, landmarks or action units (AUs) of a source image to guide the expression edit of a target image. However, the prediction of expressions, landmarks and especially AUs may be inaccurate, which limits the accuracy of transferring fine-grained expressions. Instead of using an intermediate estimated guidance, we propose to explicitly transfer expressions by directly mapping two unpaired images to two synthesized images with swapped expressions. Since each AU semantically describes local expression details, we can synthesize new images with preserved identities and swapped expressions by combining AU-free features with swapped AU-related features. To disentangle the images into AU-related features and AU-free features, we propose a novel adversarial training method which can solve the adversarial learning of multi-class classification problems. Moreover, to obtain reliable expression transfer results of the unpaired input, we introduce a swap consistency loss to make the synthesized images and self-reconstructed images indistinguishable. Extensive experiments on RaFD, MMI and CFD datasets show that our approach can generate photo-realistic expression transfer results between unpaired images with different expression appearances including genders, ages, races and poses.
Deep Multi-Center Learning for Face Alignment
Aug 05, 2018
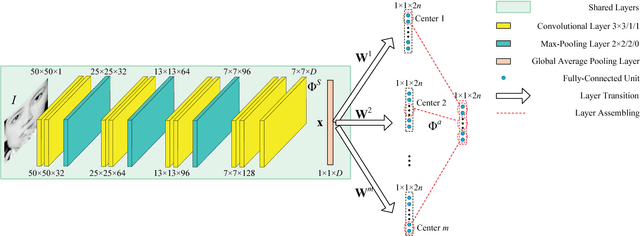
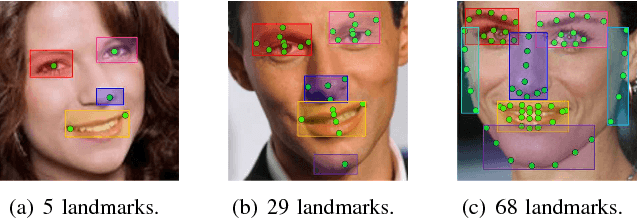

Facial landmarks are highly correlated with each other since a certain landmark can be estimated by its neighboring landmarks. Most of the existing deep learning methods only use one fully-connected layer called shape prediction layer to estimate the location of facial landmarks. In this paper, we propose a novel deep learning framework named Multi-Center Learning with multiple shape prediction layers for face alignment. In particular, each shape prediction layer emphasizes on the detection of a certain cluster of semantically relevant landmarks respectively. Challenging landmarks are focused firstly, and each cluster of landmarks is further optimized respectively. Moreover, to reduce the model complexity, we propose a model assembling method to integrate multiple shape prediction layers into one shape prediction layer. Extensive experiments demonstrate that our method is effective for handling complex occlusions and appearance variations with real-time performance. The code for our method is available at https://github.com/ZhiwenShao/MCNet-Extension.
Deep attention-guided fusion network for lesion segmentation
Jul 25, 2018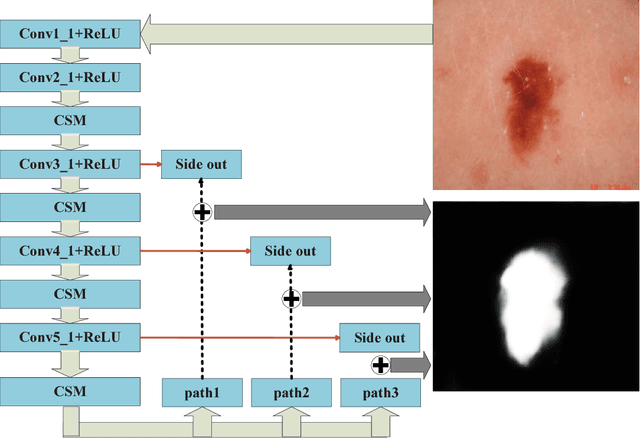
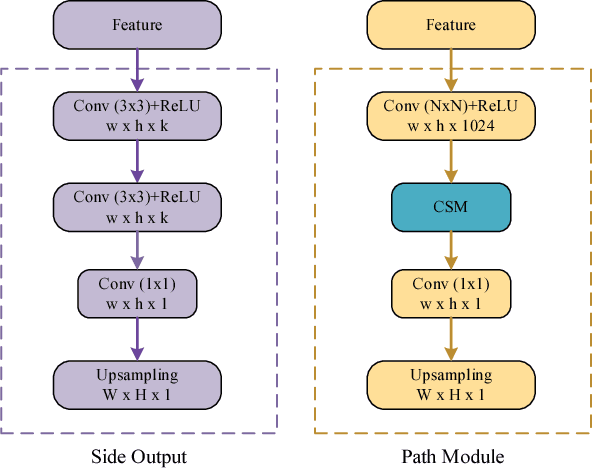
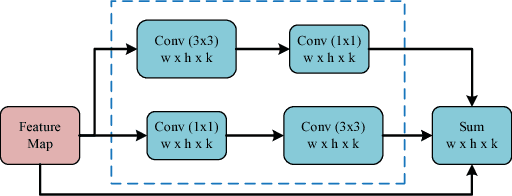
We participated the Task 1: Lesion Segmentation. The paper describes our algorithm and the final result of validation set for the ISIC Challenge 2018 - Skin Lesion Analysis Towards Melanoma Detection.