 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasure Preserving Flows for Ergodic Search in Convoluted Environments
Sep 13, 2024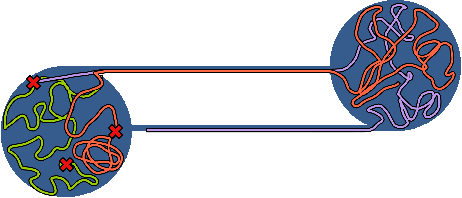
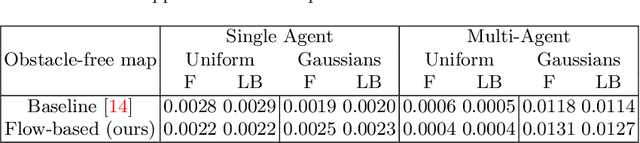
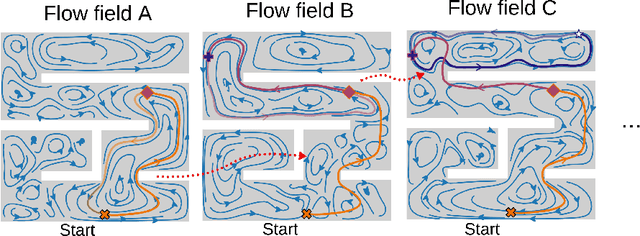
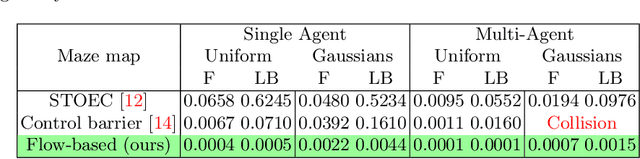
Autonomous robotic search has important applications in robotics, such as the search for signs of life after a disaster. When \emph{a priori} information is available, for example in the form of a distribution, a planner can use that distribution to guide the search. Ergodic search is one method that uses the information distribution to generate a trajectory that minimizes the ergodic metric, in that it encourages the robot to spend more time in regions with high information and proportionally less time in the remaining regions. Unfortunately, prior works in ergodic search do not perform well in complex environments with obstacles such as a building's interior or a maze. To address this, our work presents a modified ergodic metric using the Laplace-Beltrami eigenfunctions to capture map geometry and obstacle locations within the ergodic metric. Further, we introduce an approach to generate trajectories that minimize the ergodic metric while guaranteeing obstacle avoidance using measure-preserving vector fields. Finally, we leverage the divergence-free nature of these vector fields to generate collision-free trajectories for multiple agents. We demonstrate our approach via simulations with single and multi-agent systems on maps representing interior hallways and long corridors with non-uniform information distribution. In particular, we illustrate the generation of feasible trajectories in complex environments where prior methods fail.
Assigning Credit with Partial Reward Decoupling in Multi-Agent Proximal Policy Optimization
Aug 08, 2024Multi-agent proximal policy optimization (MAPPO) has recently demonstrated state-of-the-art performance on challenging multi-agent reinforcement learning tasks. However, MAPPO still struggles with the credit assignment problem, wherein the sheer difficulty in ascribing credit to individual agents' actions scales poorly with team size. In this paper, we propose a multi-agent reinforcement learning algorithm that adapts recent developments in credit assignment to improve upon MAPPO. Our approach leverages partial reward decoupling (PRD), which uses a learned attention mechanism to estimate which of a particular agent's teammates are relevant to its learning updates. We use this estimate to dynamically decompose large groups of agents into smaller, more manageable subgroups. We empirically demonstrate that our approach, PRD-MAPPO, decouples agents from teammates that do not influence their expected future reward, thereby streamlining credit assignment. We additionally show that PRD-MAPPO yields significantly higher data efficiency and asymptotic performance compared to both MAPPO and other state-of-the-art methods across several multi-agent tasks, including StarCraft II. Finally, we propose a version of PRD-MAPPO that is applicable to \textit{shared} reward settings, where PRD was previously not applicable, and empirically show that this also leads to performance improvements over MAPPO.
Propagative Distance Optimization for Constrained Inverse Kinematics
Jun 17, 2024This paper investigates a constrained inverse kinematic (IK) problem that seeks a feasible configuration of an articulated robot under various constraints such as joint limits and obstacle collision avoidance. Due to the high-dimensionality and complex constraints, this problem is often solved numerically via iterative local optimization. Classic local optimization methods take joint angles as the decision variable, which suffers from non-linearity caused by the trigonometric constraints. Recently, distance-based IK methods have been developed as an alternative approach that formulates IK as an optimization over the distances among points attached to the robot and the obstacles. Although distance-based methods have demonstrated unique advantages, they still suffer from low computational efficiency, since these approaches usually ignore the chain structure in the kinematics of serial robots. This paper proposes a new method called propagative distance optimization for constrained inverse kinematics (PDO-IK), which captures and leverages the chain structure in the distance-based formulation and expedites the optimization by computing forward kinematics and the Jacobian propagatively along the kinematic chain. Test results show that PDO-IK runs up to two orders of magnitude faster than the existing distance-based methods under joint limits constraints and obstacle avoidance constraints. It also achieves up to three times higher success rates than the conventional joint-angle-based optimization methods for IK problems. The high runtime efficiency of PDO-IK allows the real-time computation (10$-$1500 Hz) and enables a simulated humanoid robot with 19 degrees of freedom (DoFs) to avoid moving obstacles, which is otherwise hard to achieve with the baselines.
General Place Recognition Survey: Towards Real-World Autonomy
May 08, 2024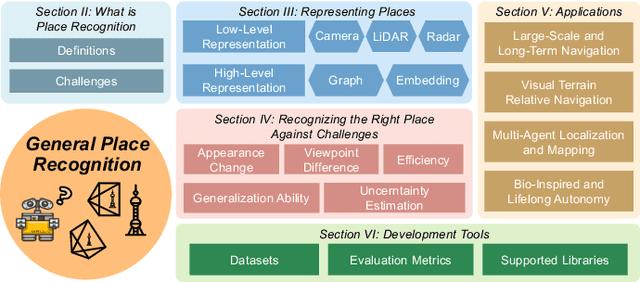
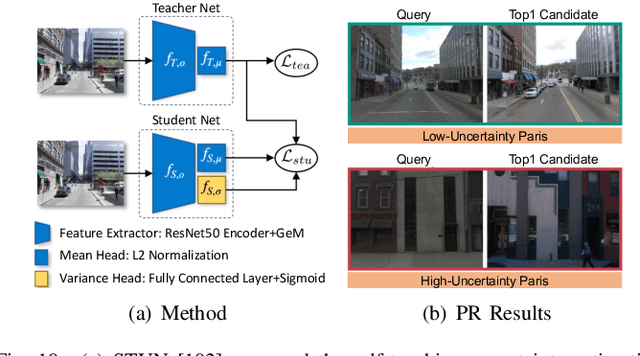
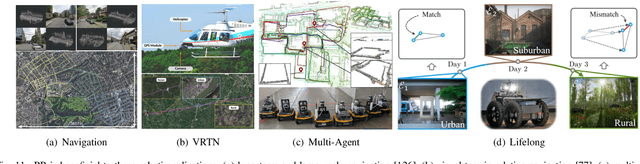
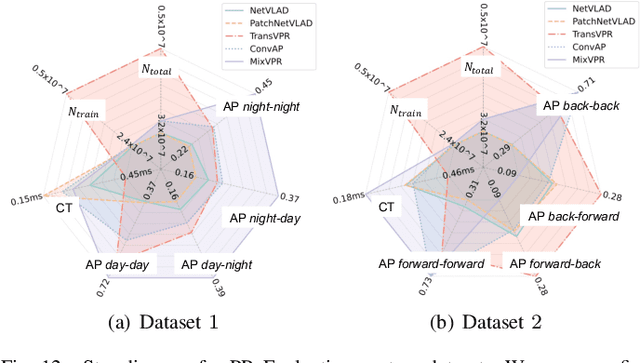
In the realm of robotics, the quest for achieving real-world autonomy, capable of executing large-scale and long-term operations, has positioned place recognition (PR) as a cornerstone technology. Despite the PR community's remarkable strides over the past two decades, garnering attention from fields like computer vision and robotics, the development of PR methods that sufficiently support real-world robotic systems remains a challenge. This paper aims to bridge this gap by highlighting the crucial role of PR within the framework of Simultaneous Localization and Mapping (SLAM) 2.0. This new phase in robotic navigation calls for scalable, adaptable, and efficient PR solutions by integrating advanced artificial intelligence (AI) technologies. For this goal, we provide a comprehensive review of the current state-of-the-art (SOTA) advancements in PR, alongside the remaining challenges, and underscore its broad applications in robotics. This paper begins with an exploration of PR's formulation and key research challenges. We extensively review literature, focusing on related methods on place representation and solutions to various PR challenges. Applications showcasing PR's potential in robotics, key PR datasets, and open-source libraries are discussed. We also emphasizes our open-source package, aimed at new development and benchmark for general PR. We conclude with a discussion on PR's future directions, accompanied by a summary of the literature covered and access to our open-source library, available to the robotics community at: https://github.com/MetaSLAM/GPRS.
A Convex Formulation of the Soft-Capture Problem
May 01, 2024



We present a fast trajectory optimization algorithm for the soft capture of uncooperative tumbling space objects. Our algorithm generates safe, dynamically feasible, and minimum-fuel trajectories for a six-degree-of-freedom servicing spacecraft to achieve soft capture (near-zero relative velocity at contact) between predefined locations on the servicer spacecraft and target body. We solve a convex problem by enforcing a convex relaxation of the field-of-view constraint, followed by a sequential convex program correcting the trajectory for collision avoidance. The optimization problems can be solved with a standard second-order cone programming solver, making the algorithm both fast and practical for implementation in flight software. We demonstrate the performance and robustness of our algorithm in simulation over a range of object tumble rates up to 10{\deg}/s.
A Mixed-Integer Conic Program for the Moving-Target Traveling Salesman Problem based on a Graph of Convex Sets
Mar 11, 2024



This paper introduces a new formulation that finds the optimum for the Moving-Target Traveling Salesman Problem (MT-TSP), which seeks to find a shortest path for an agent, that starts at a depot, visits a set of moving targets exactly once within their assigned time-windows, and returns to the depot. The formulation relies on the key idea that when the targets move along lines, their trajectories become convex sets within the space-time coordinate system. The problem then reduces to finding the shortest path within a graph of convex sets, subject to some speed constraints. We compare our formulation with the current state-of-the-art Mixed Integer Conic Program (MICP) solver for the MT-TSP. The experimental results show that our formulation outperforms the MICP for instances with up to 20 targets, with up to two orders of magnitude reduction in runtime, and up to a 60\% tighter optimality gap. We also show that the solution cost from the convex relaxation of our formulation provides significantly tighter lower bounds for the MT-TSP than the ones from the MICP.
PINSAT: Parallelized Interleaving of Graph Search and Trajectory Optimization for Kinodynamic Motion Planning
Jan 17, 2024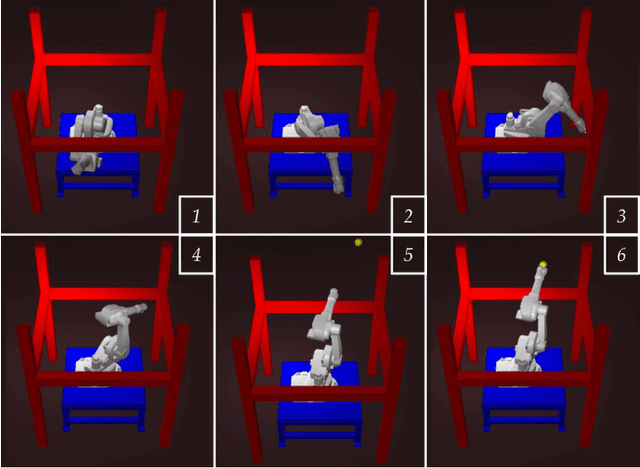

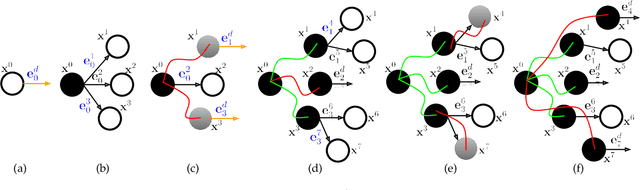

Trajectory optimization is a widely used technique in robot motion planning for letting the dynamics and constraints on the system shape and synthesize complex behaviors. Several previous works have shown its benefits in high-dimensional continuous state spaces and under differential constraints. However, long time horizons and planning around obstacles in non-convex spaces pose challenges in guaranteeing convergence or finding optimal solutions. As a result, discrete graph search planners and sampling-based planers are preferred when facing obstacle-cluttered environments. A recently developed algorithm called INSAT effectively combines graph search in the low-dimensional subspace and trajectory optimization in the full-dimensional space for global kinodynamic planning over long horizons. Although INSAT successfully reasoned about and solved complex planning problems, the numerous expensive calls to an optimizer resulted in large planning times, thereby limiting its practical use. Inspired by the recent work on edge-based parallel graph search, we present PINSAT, which introduces systematic parallelization in INSAT to achieve lower planning times and higher success rates, while maintaining significantly lower costs over relevant baselines. We demonstrate PINSAT by evaluating it on 6 DoF kinodynamic manipulation planning with obstacles.
Preprocessing-based Kinodynamic Motion Planning Framework for Intercepting Projectiles using a Robot Manipulator
Jan 16, 2024



We are interested in studying sports with robots and starting with the problem of intercepting a projectile moving toward a robot manipulator equipped with a shield. To successfully perform this task, the robot needs to (i) detect the incoming projectile, (ii) predict the projectile's future motion, (iii) plan a minimum-time rapid trajectory that can evade obstacles and intercept the projectile, and (iv) execute the planned trajectory. These four steps must be performed under the manipulator's dynamic limits and extreme time constraints (<350ms in our setting) to successfully intercept the projectile. In addition, we want these trajectories to be smooth to reduce the robot's joint torques and the impulse on the platform on which it is mounted. To this end, we propose a kinodynamic motion planning framework that preprocesses smooth trajectories offline to allow real-time collision-free executions online. We present an end-to-end pipeline along with our planning framework, including perception, prediction, and execution modules. We evaluate our framework experimentally in simulation and show that it has a higher blocking success rate than the baselines. Further, we deploy our pipeline on a robotic system comprising an industrial arm (ABB IRB-1600) and an onboard stereo camera (ZED 2i), which achieves a 78% success rate in projectile interceptions.
DMS*: Minimizing Makespan for Multi-Agent Combinatorial Path Finding
Dec 11, 2023Multi-Agent Combinatorial Path Finding (MCPF) seeks collision-free paths for multiple agents from their initial to goal locations, while visiting a set of intermediate target locations in the middle of the paths. MCPF is challenging as it involves both planning collision-free paths for multiple agents and target sequencing, i.e., solving traveling salesman problems to assign targets to and find the visiting order for the agents. Recent work develops methods to address MCPF while minimizing the sum of individual arrival times at goals. Such a problem formulation may result in paths with different arrival times and lead to a long makespan, the maximum arrival time, among the agents. This paper proposes a min-max variant of MCPF, denoted as MCPF-max, that minimizes the makespan of the agents. While the existing methods (such as MS*) for MCPF can be adapted to solve MCPF-max, we further develop two new techniques based on MS* to defer the expensive target sequencing during planning to expedite the overall computation. We analyze the properties of the resulting algorithm Deferred MS* (DMS*), and test DMS* with up to 20 agents and 80 targets. We demonstrate the use of DMS* on differential-drive robots.
C*: A New Bounding Approach for the Moving-Target Traveling Salesman Problem
Dec 09, 2023We introduce a new bounding approach called Continuity* (C*) that provides optimality guarantees to the Moving-Target Traveling Salesman Problem (MT-TSP). Our approach relies on relaxing the continuity constraints on the agent's tour. This is done by partitioning the targets' trajectories into small sub-segments and allowing the agent to arrive at any point in one of the sub-segments and depart from any point in the same sub-segment when visiting each target. This lets us pose the bounding problem as a Generalized Traveling Salesman Problem (GTSP) in a graph where the cost of traveling an edge requires us to solve a new problem called the Shortest Feasible Travel (SFT). We also introduce C*-lite, which follows the same approach as C*, but uses simple and easy to compute lower-bounds to the SFT. We first prove that the proposed algorithms provide lower bounds to the MT-TSP. We also provide computational results to corroborate the performance of C* and C*-lite for instances with up to 15 targets. For the special case where targets travel along lines, we compare our C* variants with the SOCP based method, which is the current state-of-the-art solver for MT-TSP. While the SOCP based method performs well for instances with 5 and 10 targets, C* outperforms the SOCP based method for instances with 15 targets. For the general case, on average, our approaches find feasible solutions within ~4% of the lower bounds for the tested instances.