 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiparametric Efficient Bilevel Gradient Estimation
May 20, 2026Functional bilevel methods estimate a lower-level function and plug it into a hypergradient, but this plug-in gradient can retain first-order bias when the lower-level problem is learned nonparametrically. To remove this bias, we develop a semiparametric debiasing theory for population bilevel gradients based on the efficient influence function. This perspective leads to a cross-fitted orthogonal hypergradient estimator for which we establish asymptotic normality together with uniform control over the outer parameter. Under quadratic losses, the estimator reduces to a simple doubly robust score based on conditional mean nuisances. On synthetic bilevel benchmarks with known ground truth, the method tracks the oracle efficient-gradient benchmark and improves over plug-in functional hypergradients and regularized kernel bilevel baselines.
Doubly Robust Proxy Causal Learning with Neural Mean Embeddings
May 10, 2026Unobserved confounding prevents standard covariate adjustment from identifying causal response functions in observational studies. Proxy causal learning addresses this problem through bridge equations involving treatment- and outcome-inducing proxies, avoiding direct recovery of the latent confounder. Existing doubly robust proxy estimators combine outcome and treatment bridges, but typically rely on fixed kernels, sieves, or low-dimensional semiparametric models; existing neural proxy methods are more flexible, but are largely single-bridge estimators. We develop a neural doubly robust framework for proxy causal learning with continuous and structured treatments. Our method introduces a neural mean-embedding estimator for the treatment bridge, combines it with a neural outcome bridge, and estimates the doubly robust correction through a final regression stage. The framework covers population, heterogeneous, and conditional dose-response functions, yielding full response-curve estimators rather than binary-treatment effects. The algorithms use two stages for each bridge and history-aware updates of the final linear layers to stabilize stochastic multi-stage training. We prove consistency of the algorithms showing that the doubly robust error is controlled by the final averaging and regression errors together with the smaller of the outcome- and treatment-side weak-norm bridge errors. Across synthetic and image-valued benchmarks, the proposed estimators outperform existing baselines and single-bridge neural estimators, showing the benefit of combining learned outcome and treatment bridges in a doubly robust construction. Our implementation is available at https://github.com/BariscanBozkurt/DRPCL-Neural-Mean-Embedding.
Instrumental Variable Analysis Without Structural Equations
Apr 27, 2026We consider debiased inference on least-squares solutions to inverse problems as a way to avoid having to assume exact solutions exist. Such assumptions are substantive and not innocuous and their failure may well imperil inference when we impose them on the statistical model. Our approach instead allows us to conduct inference on a quantity that is defined regardless of solutions existing and coincides with the usual estimands when they do. For the case of instrumental variables, this means we can motivate the analysis with structural models but these do not need to hold exactly for the inferential procedure to remain valid.
Functional Natural Policy Gradients
Mar 30, 2026We propose a cross-fitted debiasing device for policy learning from offline data. A key consequence of the resulting learning principle is $\sqrt N$ regret even for policy classes with complexity greater than Donsker, provided a product-of-errors nuisance remainder is $O(N^{-1/2})$. The regret bound factors into a plug-in policy error factor governed by policy-class complexity and an environment nuisance factor governed by the complexity of the environment dynamics, making explicit how one may be traded against the other.
Efficient Inference after Directionally Stable Adaptive Experiments
Feb 25, 2026We study inference on scalar-valued pathwise differentiable targets after adaptive data collection, such as a bandit algorithm. We introduce a novel target-specific condition, directional stability, which is strictly weaker than previously imposed target-agnostic stability conditions. Under directional stability, we show that estimators that would have been efficient under i.i.d. data remain asymptotically normal and semiparametrically efficient when computed from adaptively collected trajectories. The canonical gradient has a martingale form, and directional stability guarantees stabilization of its predictable quadratic variation, enabling high-dimensional asymptotic normality. We characterize efficiency using a convolution theorem for the adaptive-data setting, and give a condition under which the one-step estimator attains the efficiency bound. We verify directional stability for LinUCB, yielding the first semiparametric efficiency guarantee for a regular scalar target under LinUCB sampling.
Density Ratio-Free Doubly Robust Proxy Causal Learning
May 26, 2025We study the problem of causal function estimation in the Proxy Causal Learning (PCL) framework, where confounders are not observed but proxies for the confounders are available. Two main approaches have been proposed: outcome bridge-based and treatment bridge-based methods. In this work, we propose two kernel-based doubly robust estimators that combine the strengths of both approaches, and naturally handle continuous and high-dimensional variables. Our identification strategy builds on a recent density ratio-free method for treatment bridge-based PCL; furthermore, in contrast to previous approaches, it does not require indicator functions or kernel smoothing over the treatment variable. These properties make it especially well-suited for continuous or high-dimensional treatments. By using kernel mean embeddings, we have closed-form solutions and strong consistency guarantees. Our estimators outperform existing methods on PCL benchmarks, including a prior doubly robust method that requires both kernel smoothing and density ratio estimation.
Causal mediation analysis with one or multiple mediators: a comparative study
May 12, 2025Mediation analysis breaks down the causal effect of a treatment on an outcome into an indirect effect, acting through a third group of variables called mediators, and a direct effect, operating through other mechanisms. Mediation analysis is hard because confounders between treatment, mediators, and outcome blur effect estimates in observational studies. Many estimators have been proposed to adjust on those confounders and provide accurate causal estimates. We consider parametric and non-parametric implementations of classical estimators and provide a thorough evaluation for the estimation of the direct and indirect effects in the context of causal mediation analysis for binary, continuous, and multi-dimensional mediators. We assess several approaches in a comprehensive benchmark on simulated data. Our results show that advanced statistical approaches such as the multiply robust and the double machine learning estimators achieve good performances in most of the simulated settings and on real data. As an example of application, we propose a thorough analysis of factors known to influence cognitive functions to assess if the mechanism involves modifications in brain morphology using the UK Biobank brain imaging cohort. This analysis shows that for several physiological factors, such as hypertension and obesity, a substantial part of the effect is mediated by changes in the brain structure. This work provides guidance to the practitioner from the formulation of a valid causal mediation problem, including the verification of the identification assumptions, to the choice of an adequate estimator.
Covariance-Adaptive Least-Squares Algorithm for Stochastic Combinatorial Semi-Bandits
Feb 23, 2024



We address the problem of stochastic combinatorial semi-bandits, where a player can select from P subsets of a set containing d base items. Most existing algorithms (e.g. CUCB, ESCB, OLS-UCB) require prior knowledge on the reward distribution, like an upper bound on a sub-Gaussian proxy-variance, which is hard to estimate tightly. In this work, we design a variance-adaptive version of OLS-UCB, relying on an online estimation of the covariance structure. Estimating the coefficients of a covariance matrix is much more manageable in practical settings and results in improved regret upper bounds compared to proxy variance-based algorithms. When covariance coefficients are all non-negative, we show that our approach efficiently leverages the semi-bandit feedback and provably outperforms bandit feedback approaches, not only in exponential regimes where P $\gg$ d but also when P $\le$ d, which is not straightforward from most existing analyses.
Sequential Counterfactual Risk Minimization
Feb 23, 2023Counterfactual Risk Minimization (CRM) is a framework for dealing with the logged bandit feedback problem, where the goal is to improve a logging policy using offline data. In this paper, we explore the case where it is possible to deploy learned policies multiple times and acquire new data. We extend the CRM principle and its theory to this scenario, which we call "Sequential Counterfactual Risk Minimization (SCRM)." We introduce a novel counterfactual estimator and identify conditions that can improve the performance of CRM in terms of excess risk and regret rates, by using an analysis similar to restart strategies in accelerated optimization methods. We also provide an empirical evaluation of our method in both discrete and continuous action settings, and demonstrate the benefits of multiple deployments of CRM.
Nested bandits
Jun 19, 2022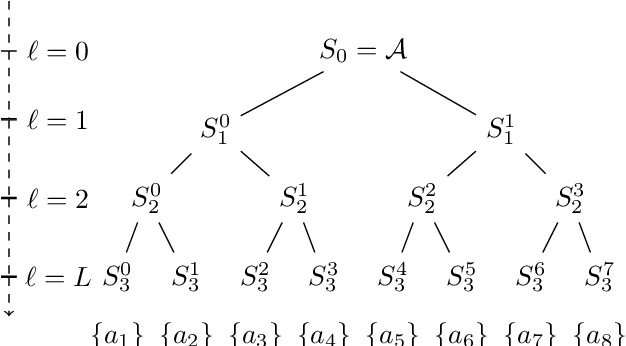
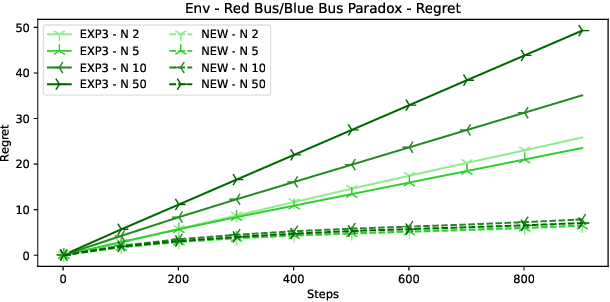
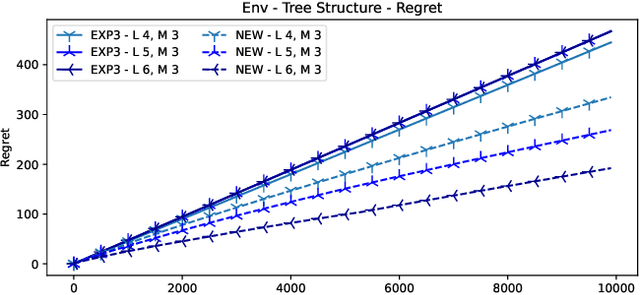
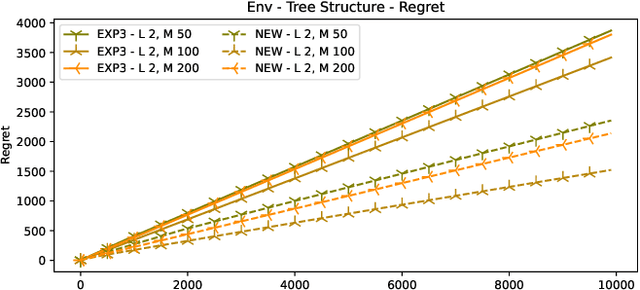
In many online decision processes, the optimizing agent is called to choose between large numbers of alternatives with many inherent similarities; in turn, these similarities imply closely correlated losses that may confound standard discrete choice models and bandit algorithms. We study this question in the context of nested bandits, a class of adversarial multi-armed bandit problems where the learner seeks to minimize their regret in the presence of a large number of distinct alternatives with a hierarchy of embedded (non-combinatorial) similarities. In this setting, optimal algorithms based on the exponential weights blueprint (like Hedge, EXP3, and their variants) may incur significant regret because they tend to spend excessive amounts of time exploring irrelevant alternatives with similar, suboptimal costs. To account for this, we propose a nested exponential weights (NEW) algorithm that performs a layered exploration of the learner's set of alternatives based on a nested, step-by-step selection method. In so doing, we obtain a series of tight bounds for the learner's regret showing that online learning problems with a high degree of similarity between alternatives can be resolved efficiently, without a red bus / blue bus paradox occurring.