 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-training with Mixup May Hurt Generalization
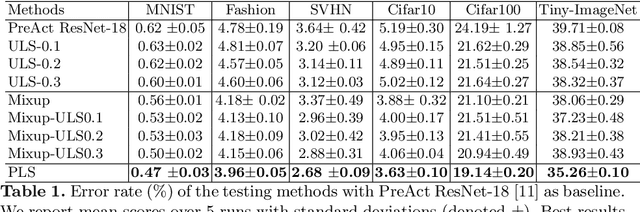
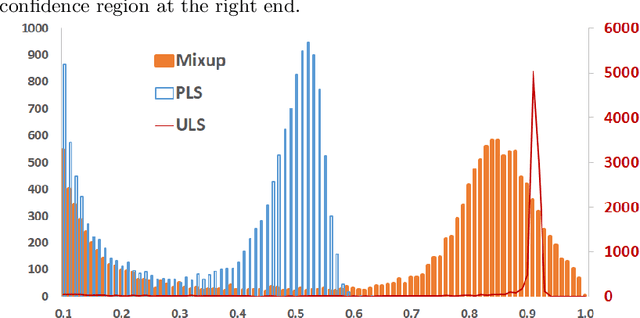
Mar 02, 2023Mixup, which creates synthetic training instances by linearly interpolating random sample pairs, is a simple and yet effective regularization technique to boost the performance of deep models trained with SGD. In this work, we report a previously unobserved phenomenon in Mixup training: on a number of standard datasets, the performance of Mixup-trained models starts to decay after training for a large number of epochs, giving rise to a U-shaped generalization curve. This behavior is further aggravated when the size of original dataset is reduced. To help understand such a behavior of Mixup, we show theoretically that Mixup training may introduce undesired data-dependent label noises to the synthesized data. Via analyzing a least-square regression problem with a random feature model, we explain why noisy labels may cause the U-shaped curve to occur: Mixup improves generalization through fitting the clean patterns at the early training stage, but as training progresses, Mixup becomes over-fitting to the noise in the synthetic data. Extensive experiments are performed on a variety of benchmark datasets, validating this explanation.
T-Cell Receptor Optimization with Reinforcement Learning and Mutation Policies for Precesion Immunotherapy
Mar 02, 2023T cells monitor the health status of cells by identifying foreign peptides displayed on their surface. T-cell receptors (TCRs), which are protein complexes found on the surface of T cells, are able to bind to these peptides. This process is known as TCR recognition and constitutes a key step for immune response. Optimizing TCR sequences for TCR recognition represents a fundamental step towards the development of personalized treatments to trigger immune responses killing cancerous or virus-infected cells. In this paper, we formulated the search for these optimized TCRs as a reinforcement learning (RL) problem, and presented a framework TCRPPO with a mutation policy using proximal policy optimization. TCRPPO mutates TCRs into effective ones that can recognize given peptides. TCRPPO leverages a reward function that combines the likelihoods of mutated sequences being valid TCRs measured by a new scoring function based on deep autoencoders, with the probabilities of mutated sequences recognizing peptides from a peptide-TCR interaction predictor. We compared TCRPPO with multiple baseline methods and demonstrated that TCRPPO significantly outperforms all the baseline methods to generate positive binding and valid TCRs. These results demonstrate the potential of TCRPPO for both precision immunotherapy and peptide-recognizing TCR motif discovery.
A Text-guided Protein Design Framework
Feb 09, 2023



Current AI-assisted protein design mainly utilizes protein sequential and structural information. Meanwhile, there exists tremendous knowledge curated by humans in the text format describing proteins' high-level properties. Yet, whether the incorporation of such text data can help protein design tasks has not been explored. To bridge this gap, we propose ProteinDT, a multi-modal framework that leverages textual descriptions for protein design. ProteinDT consists of three subsequent steps: ProteinCLAP that aligns the representation of two modalities, a facilitator that generates the protein representation from the text modality, and a decoder that generates the protein sequences from the representation. To train ProteinDT, we construct a large dataset, SwissProtCLAP, with 441K text and protein pairs. We empirically verify the effectiveness of ProteinDT from three aspects: (1) consistently superior performance on four out of six protein property prediction benchmarks; (2) over 90% accuracy for text-guided protein generation; and (3) promising results for zero-shot text-guided protein editing.
Modeling driver's evasive behavior during safety-critical lane changes:Two-dimensional time-to-collision and deep reinforcement learning
Sep 29, 2022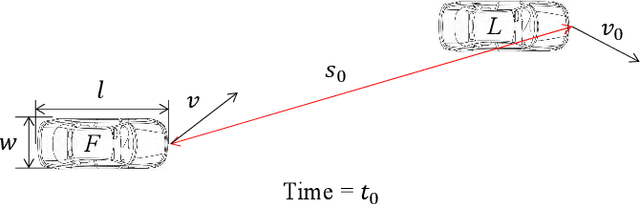
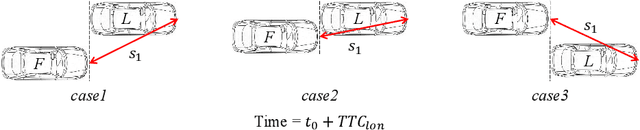

Lane changes are complex driving behaviors and frequently involve safety-critical situations. This study aims to develop a lane-change-related evasive behavior model, which can facilitate the development of safety-aware traffic simulations and predictive collision avoidance systems. Large-scale connected vehicle data from the Safety Pilot Model Deployment (SPMD) program were used for this study. A new surrogate safety measure, two-dimensional time-to-collision (2D-TTC), was proposed to identify the safety-critical situations during lane changes. The validity of 2D-TTC was confirmed by showing a high correlation between the detected conflict risks and the archived crashes. A deep deterministic policy gradient (DDPG) algorithm, which could learn the sequential decision-making process over continuous action spaces, was used to model the evasive behaviors in the identified safety-critical situations. The results showed the superiority of the proposed model in replicating both the longitudinal and lateral evasive behaviors.
Molecular Geometry Pretraining with SE(3)-Invariant Denoising Distance Matching
Jun 27, 2022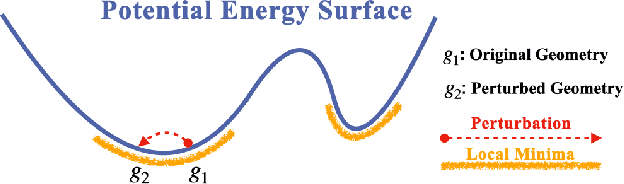
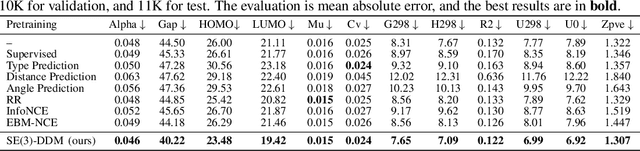
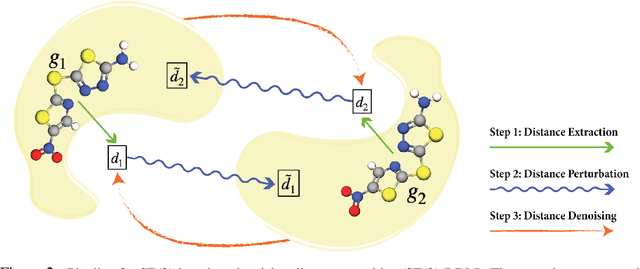
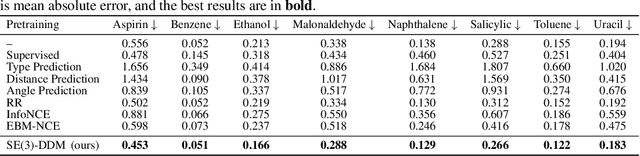
Pretraining molecular representations is critical in a variety of applications in drug and material discovery due to the limited number of labeled molecules, yet most of existing work focuses on pretraining on 2D molecular graphs. The power of pretraining on 3D geometric structures, however, has been less explored, owning to the difficulty of finding a sufficient proxy task to empower the pretraining to effectively extract essential features from the geometric structures. Motivated by the dynamic nature of 3D molecules, where the continuous motion of a molecule in the 3D Euclidean space forms a smooth potential energy surface, we propose a 3D coordinate denoising pretraining framework to model such an energy landscape. Leveraging a SE(3)-invariant score matching method, we propose SE(3)-DDM where the coordinate denoising proxy task is effectively boiled down to the denoising of the pairwise atomic distances in a molecule. Our comprehensive experiments confirm the effectiveness and robustness of our proposed method.
SoftEdge: Regularizing Graph Classification with Random Soft Edges
Apr 21, 2022
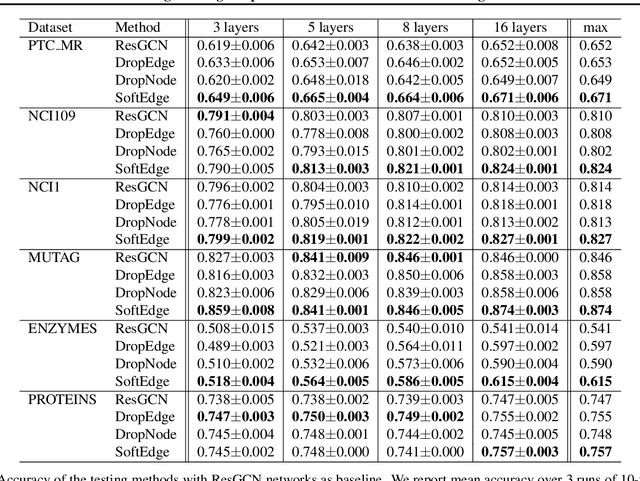
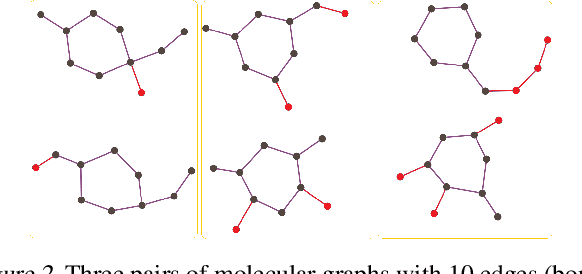
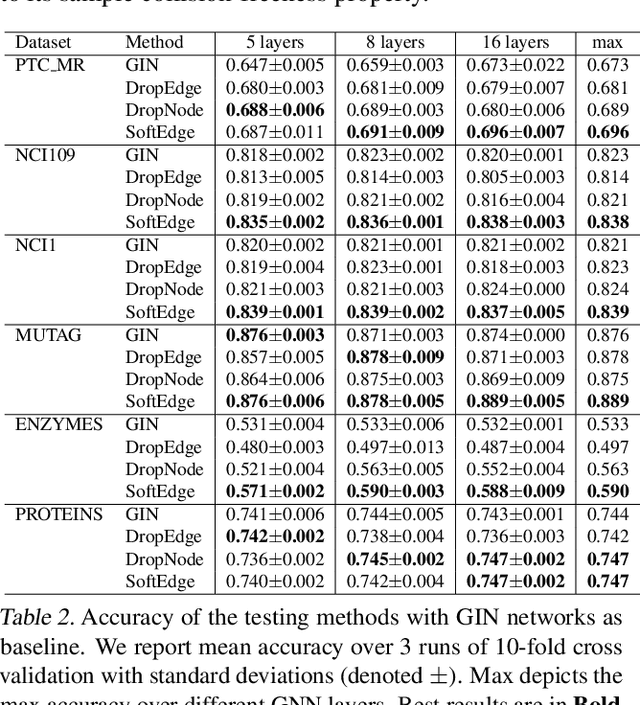
Graph data augmentation plays a vital role in regularizing Graph Neural Networks (GNNs), which leverage information exchange along edges in graphs, in the form of message passing, for learning. Due to their effectiveness, simple edge and node manipulations (e.g., addition and deletion) have been widely used in graph augmentation. In this paper, we identify a limitation in such a common augmentation technique. That is, simple edge and node manipulations can create graphs with an identical structure or indistinguishable structures to message passing GNNs but of conflict labels, leading to the sample collision issue and thus the degradation of model performance. To address this problem, we propose SoftEdge, which assigns random weights to a portion of the edges of a given graph to construct dynamic neighborhoods over the graph. We prove that SoftEdge creates collision-free augmented graphs. We also show that this simple method obtains superior accuracy to popular node and edge manipulation approaches and notable resilience to the accuracy degradation with the GNN depth.
Intrusion-Free Graph Mixup
Oct 18, 2021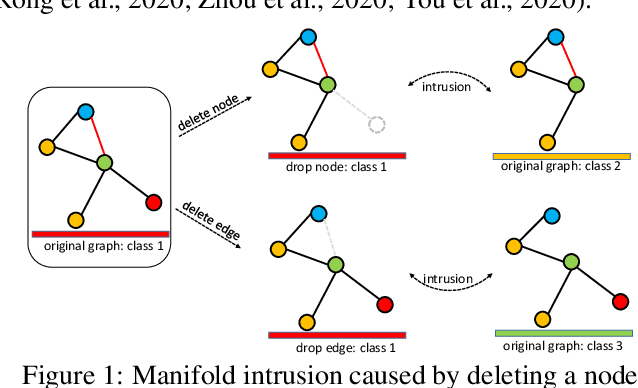
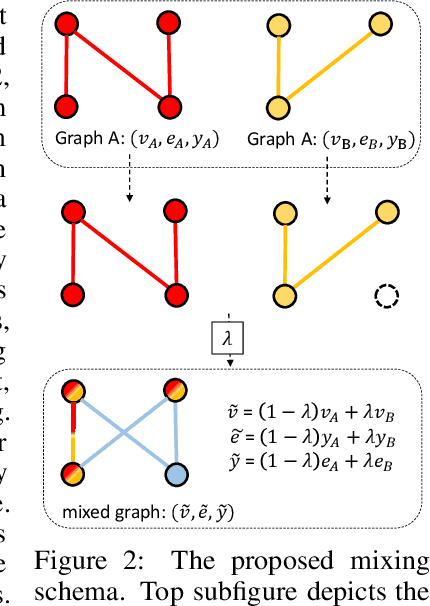
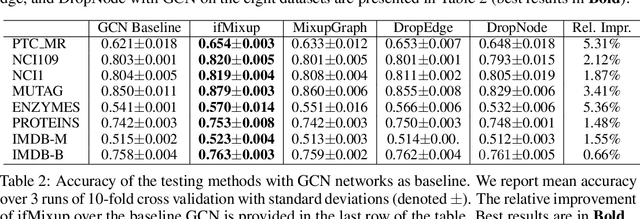
We present a simple and yet effective interpolation-based regularization technique to improve the generalization of Graph Neural Networks (GNNs). We leverage the recent advances in Mixup regularizer for vision and text, where random sample pairs and their labels are interpolated to create synthetic samples for training. Unlike images or natural sentences, which embrace a grid or linear sequence format, graphs have arbitrary structure and topology, which play a vital role on the semantic information of a graph. Consequently, even simply deleting or adding one edge from a graph can dramatically change its semantic meanings. This makes interpolating graph inputs very challenging because mixing random graph pairs may naturally create graphs with identical structure but with different labels, causing the manifold intrusion issue. To cope with this obstacle, we propose the first input mixing schema for Mixup on graph. We theoretically prove that our mixing strategy can recover the source graphs from the mixed graph, and guarantees that the mixed graphs are manifold intrusion free. We also empirically show that our method can effectively regularize the graph classification learning, resulting in superior predictive accuracy over popular graph augmentation baselines.
Pre-training Molecular Graph Representation with 3D Geometry
Oct 07, 2021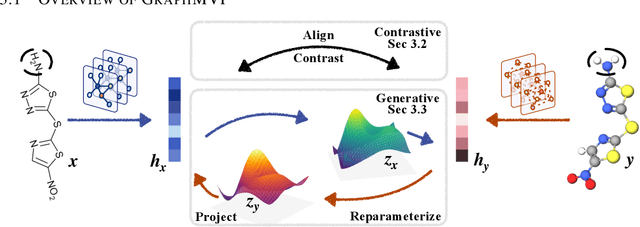
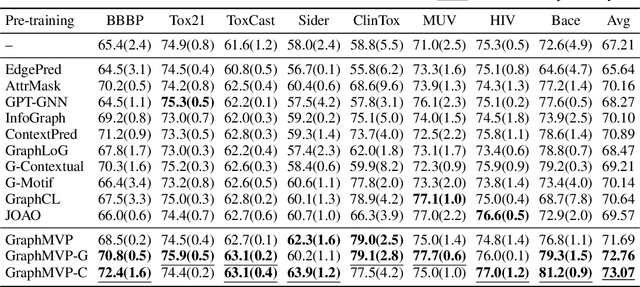

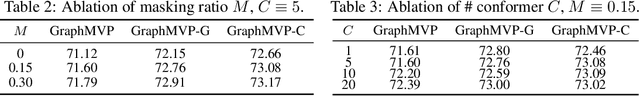
Molecular graph representation learning is a fundamental problem in modern drug and material discovery. Molecular graphs are typically modeled by their 2D topological structures, but it has been recently discovered that 3D geometric information plays a more vital role in predicting molecular functionalities. However, the lack of 3D information in real-world scenarios has significantly impeded the learning of geometric graph representation. To cope with this challenge, we propose the Graph Multi-View Pre-training (GraphMVP) framework where self-supervised learning (SSL) is performed by leveraging the correspondence and consistency between 2D topological structures and 3D geometric views. GraphMVP effectively learns a 2D molecular graph encoder that is enhanced by richer and more discriminative 3D geometry. We further provide theoretical insights to justify the effectiveness of GraphMVP. Finally, comprehensive experiments show that GraphMVP can consistently outperform existing graph SSL methods.
Midpoint Regularization: from High Uncertainty Training to Conservative Classification
Jun 26, 2021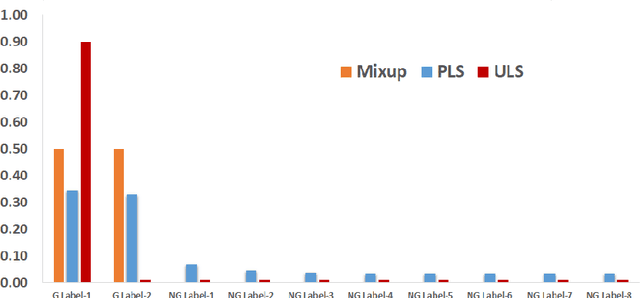
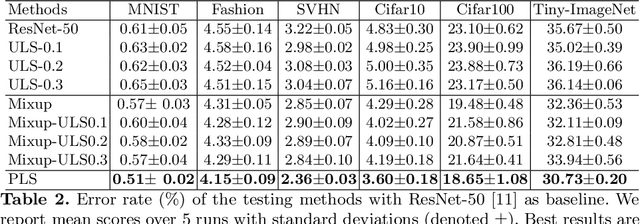
Label Smoothing (LS) improves model generalization through penalizing models from generating overconfident output distributions. For each training sample the LS strategy smooths the one-hot encoded training signal by distributing its distribution mass over the non-ground truth classes. We extend this technique by considering example pairs, coined PLS. PLS first creates midpoint samples by averaging random sample pairs and then learns a smoothing distribution during training for each of these midpoint samples, resulting in midpoints with high uncertainty labels for training. We empirically show that PLS significantly outperforms LS, achieving up to 30% of relative classification error reduction. We also visualize that PLS produces very low winning softmax scores for both in and out of distribution samples.
Symmetric Wasserstein Autoencoders
Jun 24, 2021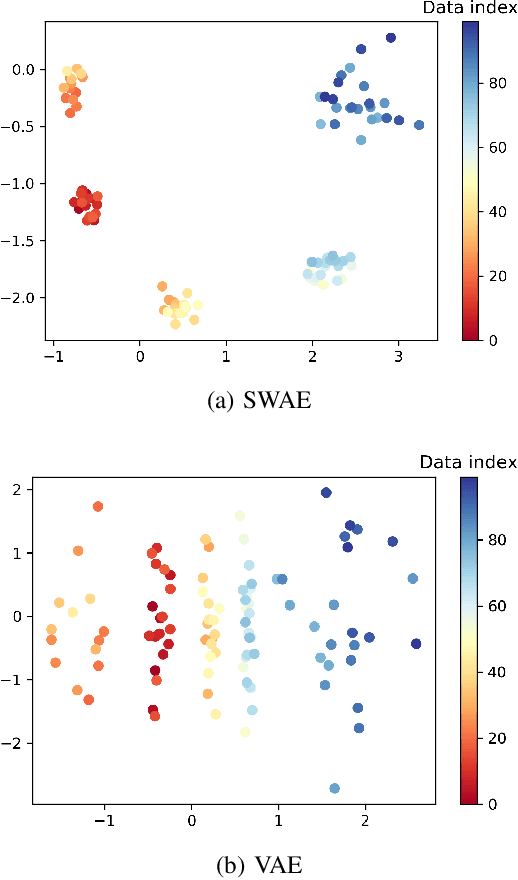
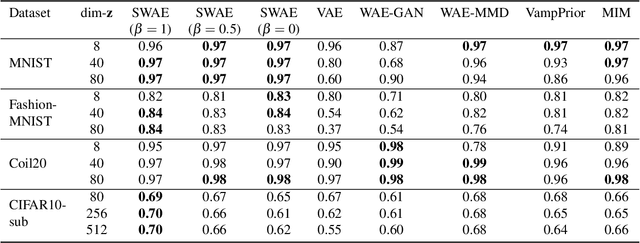
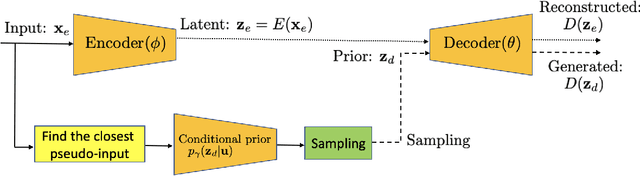

Leveraging the framework of Optimal Transport, we introduce a new family of generative autoencoders with a learnable prior, called Symmetric Wasserstein Autoencoders (SWAEs). We propose to symmetrically match the joint distributions of the observed data and the latent representation induced by the encoder and the decoder. The resulting algorithm jointly optimizes the modelling losses in both the data and the latent spaces with the loss in the data space leading to the denoising effect. With the symmetric treatment of the data and the latent representation, the algorithm implicitly preserves the local structure of the data in the latent space. To further improve the quality of the latent representation, we incorporate a reconstruction loss into the objective, which significantly benefits both the generation and reconstruction. We empirically show the superior performance of SWAEs over the state-of-the-art generative autoencoders in terms of classification, reconstruction, and generation.