 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryptoAnalystBench: Failures in Multi-Tool Long-Form LLM Analysis
Feb 11, 2026Modern analyst agents must reason over complex, high token inputs, including dozens of retrieved documents, tool outputs, and time sensitive data. While prior work has produced tool calling benchmarks and examined factuality in knowledge augmented systems, relatively little work studies their intersection: settings where LLMs must integrate large volumes of dynamic, structured and unstructured multi tool outputs. We investigate LLM failure modes in this regime using crypto as a representative high data density domain. We introduce (1) CryptoAnalystBench, an analyst aligned benchmark of 198 production crypto and DeFi queries spanning 11 categories; (2) an agentic harness equipped with relevant crypto and DeFi tools to generate responses across multiple frontier LLMs; and (3) an evaluation pipeline with citation verification and an LLM as a judge rubric spanning four user defined success dimensions: relevance, temporal relevance, depth, and data consistency. Using human annotation, we develop a taxonomy of seven higher order error types that are not reliably captured by factuality checks or LLM based quality scoring. We find that these failures persist even in state of the art systems and can compromise high stakes decisions. Based on this taxonomy, we refine the judge rubric to better capture these errors. While the judge does not align with human annotators on precise scoring across rubric iterations, it reliably identifies critical failure modes, enabling scalable feedback for developers and researchers studying analyst style agents. We release CryptoAnalystBench with annotated queries, the evaluation pipeline, judge rubrics, and the error taxonomy, and outline mitigation strategies and open challenges in evaluating long form, multi tool augmented systems.
PAL : Pretext-based Active Learning
Oct 29, 2020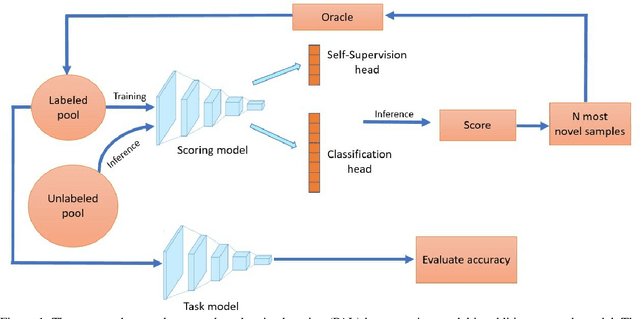
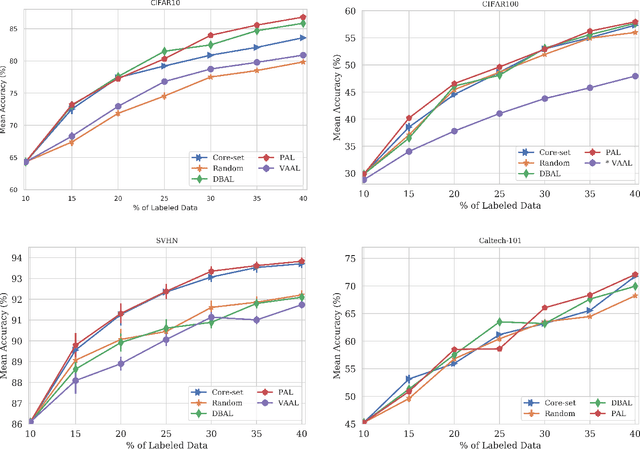
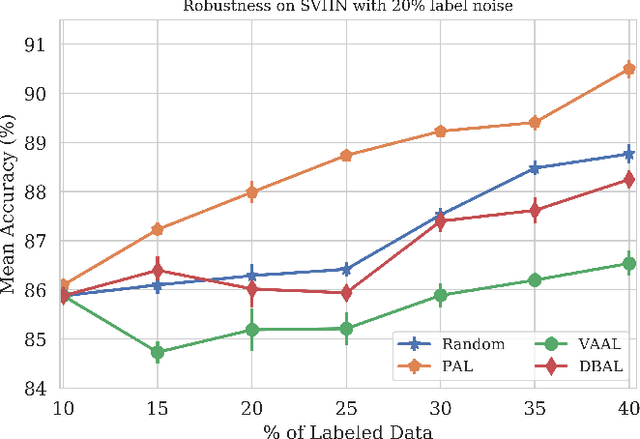
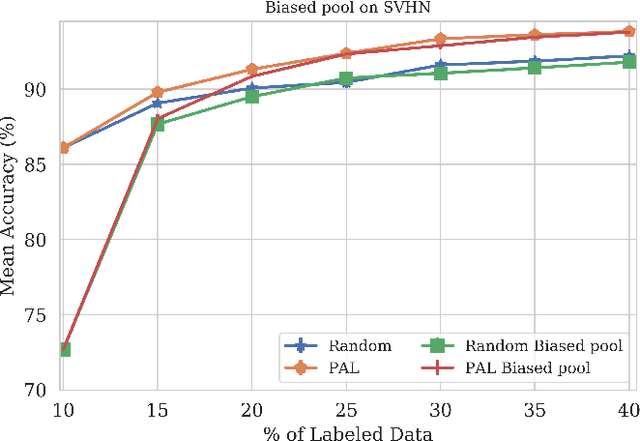
When obtaining labels is expensive, the requirement of a large labeled training data set for deep learning can be mitigated by active learning. Active learning refers to the development of algorithms to judiciously pick limited subsets of unlabeled samples that can be sent for labeling by an oracle. We propose an intuitive active learning technique that, in addition to the task neural network (e.g., for classification), uses an auxiliary self-supervised neural network that assesses the utility of an unlabeled sample for inclusion in the labeled set. Our core idea is that the difficulty of the auxiliary network trained on labeled samples to solve a self-supervision task on an unlabeled sample represents the utility of obtaining the label of that unlabeled sample. Specifically, we assume that an unlabeled image on which the precision of predicting a random applied geometric transform is low must be out of the distribution represented by the current set of labeled images. These images will therefore maximize the relative information gain when labeled by the oracle. We also demonstrate that augmenting the auxiliary network with task specific training further improves the results. We demonstrate strong performance on a range of widely used datasets and establish a new state of the art for active learning. We also make our code publicly available to encourage further research.