 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemperature Schedules for Self-Supervised Contrastive Methods on Long-Tail Data
Mar 23, 2023Most approaches for self-supervised learning (SSL) are optimised on curated balanced datasets, e.g. ImageNet, despite the fact that natural data usually exhibits long-tail distributions. In this paper, we analyse the behaviour of one of the most popular variants of SSL, i.e. contrastive methods, on long-tail data. In particular, we investigate the role of the temperature parameter $\tau$ in the contrastive loss, by analysing the loss through the lens of average distance maximisation, and find that a large $\tau$ emphasises group-wise discrimination, whereas a small $\tau$ leads to a higher degree of instance discrimination. While $\tau$ has thus far been treated exclusively as a constant hyperparameter, in this work, we propose to employ a dynamic $\tau$ and show that a simple cosine schedule can yield significant improvements in the learnt representations. Such a schedule results in a constant `task switching' between an emphasis on instance discrimination and group-wise discrimination and thereby ensures that the model learns both group-wise features, as well as instance-specific details. Since frequent classes benefit from the former, while infrequent classes require the latter, we find this method to consistently improve separation between the classes in long-tail data without any additional computational cost.
MAtch, eXpand and Improve: Unsupervised Finetuning for Zero-Shot Action Recognition with Language Knowledge
Mar 15, 2023



Large scale Vision-Language (VL) models have shown tremendous success in aligning representations between visual and text modalities. This enables remarkable progress in zero-shot recognition, image generation & editing, and many other exciting tasks. However, VL models tend to over-represent objects while paying much less attention to verbs, and require additional tuning on video data for best zero-shot action recognition performance. While previous work relied on large-scale, fully-annotated data, in this work we propose an unsupervised approach. We adapt a VL model for zero-shot and few-shot action recognition using a collection of unlabeled videos and an unpaired action dictionary. Based on that, we leverage Large Language Models and VL models to build a text bag for each unlabeled video via matching, text expansion and captioning. We use those bags in a Multiple Instance Learning setup to adapt an image-text backbone to video data. Although finetuned on unlabeled video data, our resulting models demonstrate high transferability to numerous unseen zero-shot downstream tasks, improving the base VL model performance by up to 14\%, and even comparing favorably to fully-supervised baselines in both zero-shot and few-shot video recognition transfer. The code will be released later at \url{https://github.com/wlin-at/MAXI}.
TAEC: Unsupervised Action Segmentation with Temporal-Aware Embedding and Clustering
Mar 09, 2023



Temporal action segmentation in untrimmed videos has gained increased attention recently. However, annotating action classes and frame-wise boundaries is extremely time consuming and cost intensive, especially on large-scale datasets. To address this issue, we propose an unsupervised approach for learning action classes from untrimmed video sequences. In particular, we propose a temporal embedding network that combines relative time prediction, feature reconstruction, and sequence-to-sequence learning, to preserve the spatial layout and sequential nature of the video features. A two-step clustering pipeline on these embedded feature representations then allows us to enforce temporal consistency within, as well as across videos. Based on the identified clusters, we decode the video into coherent temporal segments that correspond to semantically meaningful action classes. Our evaluation on three challenging datasets shows the impact of each component and, furthermore, demonstrates our state-of-the-art unsupervised action segmentation results.
Learning by Sorting: Self-supervised Learning with Group Ordering Constraints
Jan 05, 2023



Contrastive learning has become a prominent ingredient in learning representations from unlabeled data. However, existing methods primarily consider pairwise relations. This paper proposes a new approach towards self-supervised contrastive learning based on Group Ordering Constraints (GroCo). The GroCo loss leverages the idea of comparing groups of positive and negative images instead of pairs of images. Building on the recent success of differentiable sorting algorithms, group ordering constraints enforce that the distances of all positive samples (a positive group) are smaller than the distances of all negative images (a negative group); thus, enforcing positive samples to gather around an anchor. This leads to a more holistic optimization of the local neighborhoods. We evaluate the proposed setting on a suite of competitive self-supervised learning benchmarks and show that our method is not only competitive to current methods in the case of linear probing but also leads to higher consistency in local representations, as can be seen from a significantly improved k-NN performance across all benchmarks.
Video Test-Time Adaptation for Action Recognition
Dec 02, 2022



Although action recognition systems can achieve top performance when evaluated on in-distribution test points, they are vulnerable to unanticipated distribution shifts in test data. However, test-time adaptation of video action recognition models against common distribution shifts has so far not been demonstrated. We propose to address this problem with an approach tailored to spatio-temporal models that is capable of adaptation on a single video sample at a step. It consists in a feature distribution alignment technique that aligns online estimates of test set statistics towards the training statistics. We further enforce prediction consistency over temporally augmented views of the same test video sample. Evaluations on three benchmark action recognition datasets show that our proposed technique is architecture-agnostic and able to significantly boost the performance on both, the state of the art convolutional architecture TANet and the Video Swin Transformer. Our proposed method demonstrates a substantial performance gain over existing test-time adaptation approaches in both evaluations of a single distribution shift and the challenging case of random distribution shifts. Code will be available at \url{https://github.com/wlin-at/ViTTA}.
Deep Differentiable Logic Gate Networks
Oct 15, 2022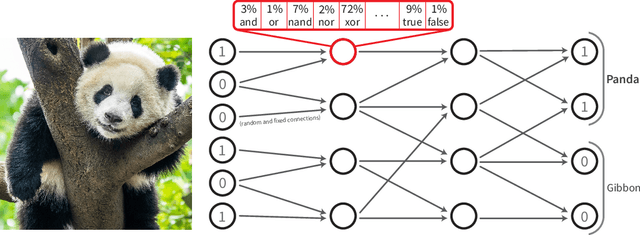

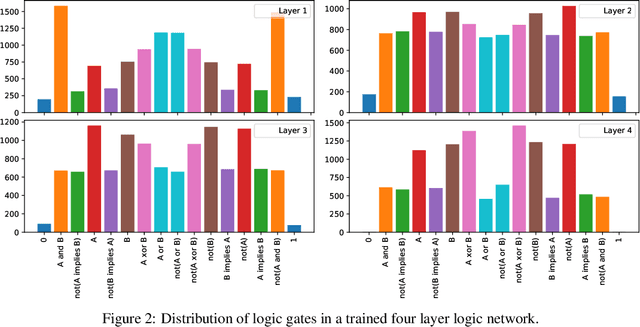
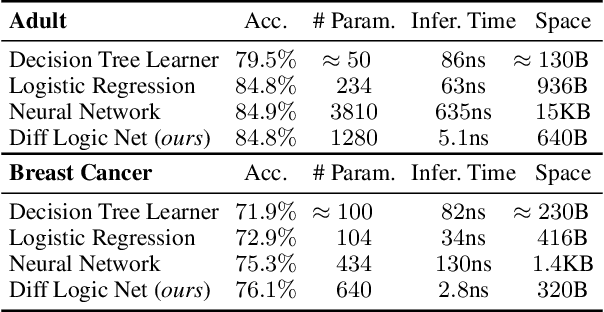
Recently, research has increasingly focused on developing efficient neural network architectures. In this work, we explore logic gate networks for machine learning tasks by learning combinations of logic gates. These networks comprise logic gates such as "AND" and "XOR", which allow for very fast execution. The difficulty in learning logic gate networks is that they are conventionally non-differentiable and therefore do not allow training with gradient descent. Thus, to allow for effective training, we propose differentiable logic gate networks, an architecture that combines real-valued logics and a continuously parameterized relaxation of the network. The resulting discretized logic gate networks achieve fast inference speeds, e.g., beyond a million images of MNIST per second on a single CPU core.
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022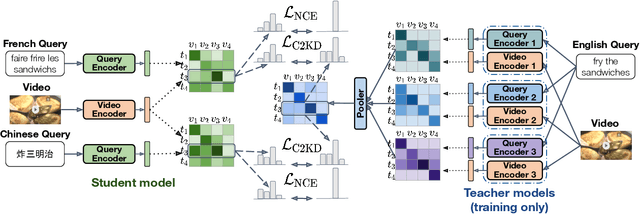
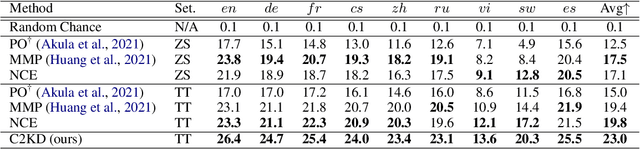

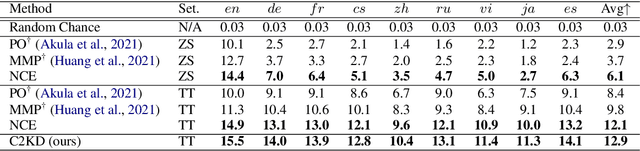
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
VL-Taboo: An Analysis of Attribute-based Zero-shot Capabilities of Vision-Language Models
Sep 12, 2022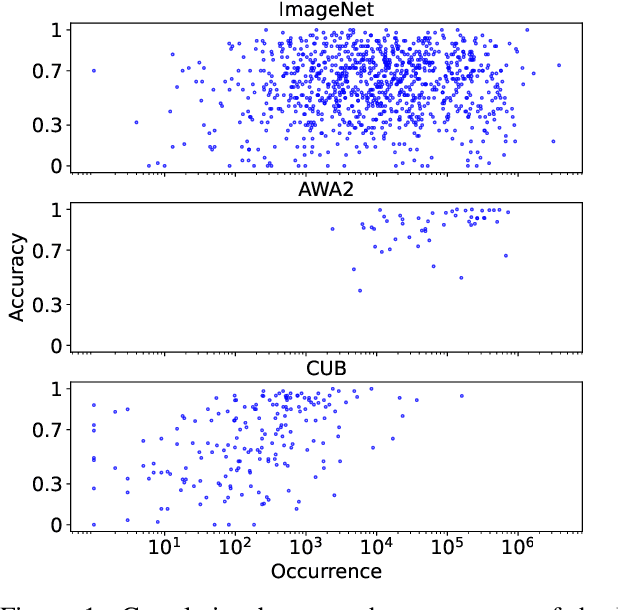
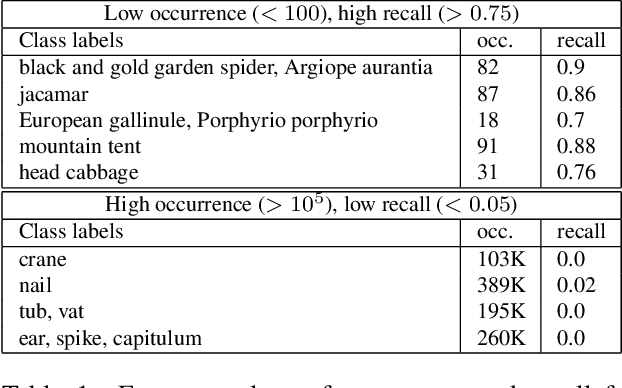
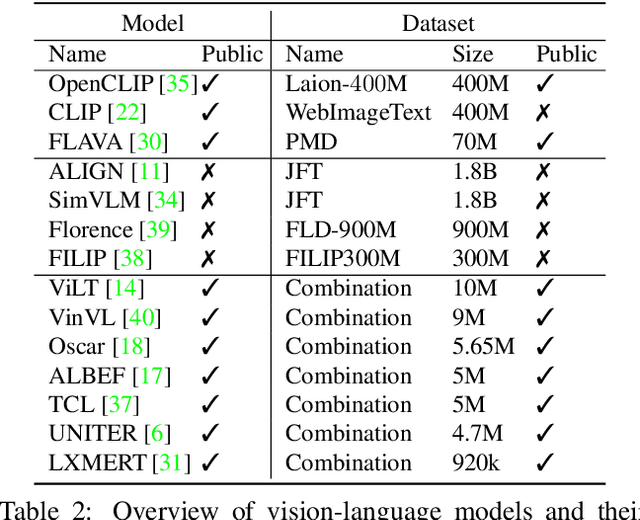
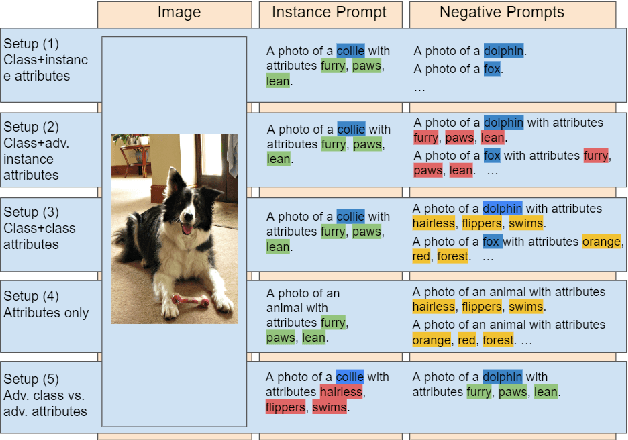
Vision-language models trained on large, randomly collected data had significant impact in many areas since they appeared. But as they show great performance in various fields, such as image-text-retrieval, their inner workings are still not fully understood. The current work analyses the true zero-shot capabilities of those models. We start from the analysis of the training corpus assessing to what extent (and which of) the test classes are really zero-shot and how this correlates with individual classes performance. We follow up with the analysis of the attribute-based zero-shot learning capabilities of these models, evaluating how well this classical zero-shot notion emerges from large-scale webly supervision. We leverage the recently released LAION400M data corpus as well as the publicly available pretrained models of CLIP, OpenCLIP, and FLAVA, evaluating the attribute-based zero-shot capabilities on CUB and AWA2 benchmarks. Our analysis shows that: (i) most of the classes in popular zero-shot benchmarks are observed (a lot) during pre-training; (ii) zero-shot performance mainly comes out of models' capability of recognizing class labels, whenever they are present in the text, and a significantly lower performing capability of attribute-based zeroshot learning is only observed when class labels are not used; (iii) the number of the attributes used can have a significant effect on performance, and can easily cause a significant performance decrease.
Augmentation Learning for Semi-Supervised Classification
Aug 03, 2022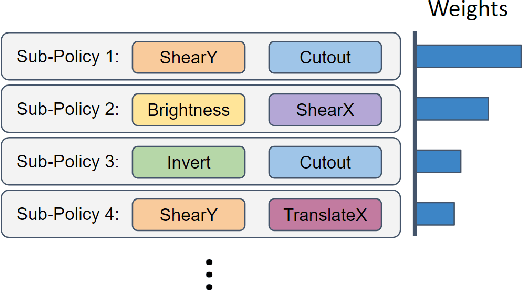
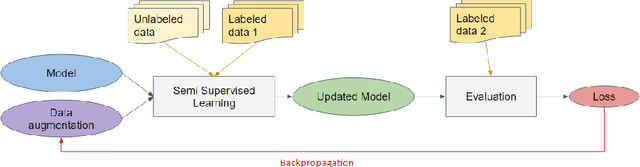
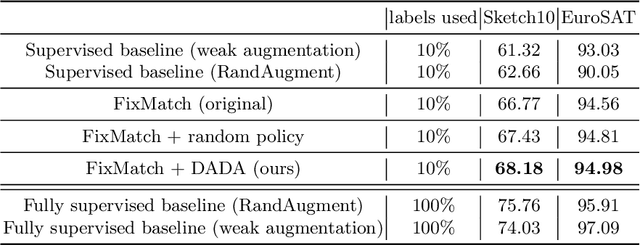
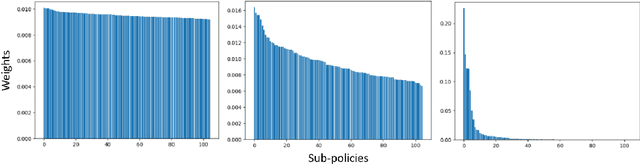
Recently, a number of new Semi-Supervised Learning methods have emerged. As the accuracy for ImageNet and similar datasets increased over time, the performance on tasks beyond the classification of natural images is yet to be explored. Most Semi-Supervised Learning methods rely on a carefully manually designed data augmentation pipeline that is not transferable for learning on images of other domains. In this work, we propose a Semi-Supervised Learning method that automatically selects the most effective data augmentation policy for a particular dataset. We build upon the Fixmatch method and extend it with meta-learning of augmentations. The augmentation is learned in additional training before the classification training and makes use of bi-level optimization, to optimize the augmentation policy and maximize accuracy. We evaluate our approach on two domain-specific datasets, containing satellite images and hand-drawn sketches, and obtain state-of-the-art results. We further investigate in an ablation the different parameters relevant for learning augmentation policies and show how policy learning can be used to adapt augmentations to datasets beyond ImageNet.
Weakly Supervised Grounding for VQA in Vision-Language Transformers
Jul 05, 2022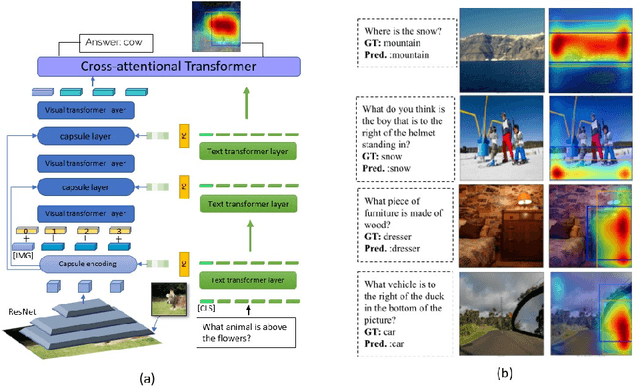
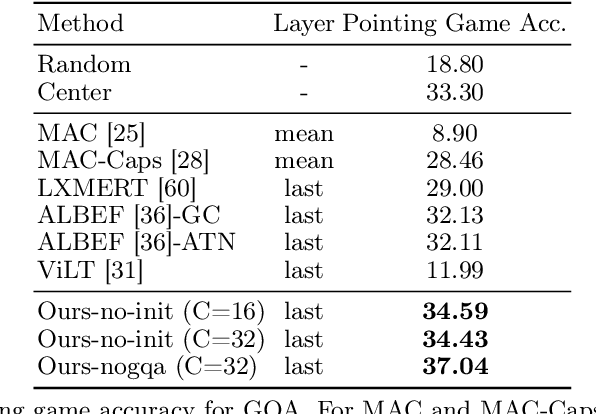
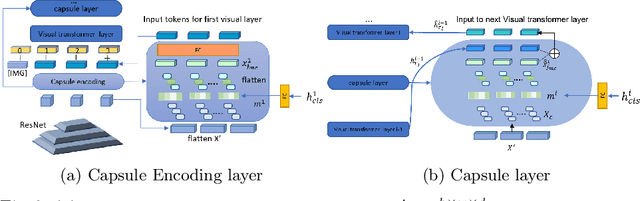
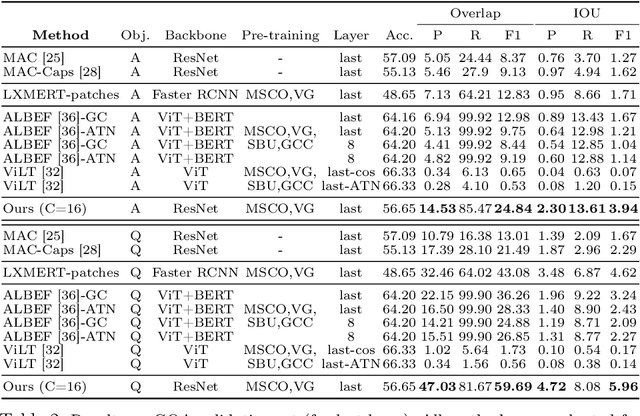
Transformers for visual-language representation learning have been getting a lot of interest and shown tremendous performance on visual question answering (VQA) and grounding. But most systems that show good performance of those tasks still rely on pre-trained object detectors during training, which limits their applicability to the object classes available for those detectors. To mitigate this limitation, the following paper focuses on the problem of weakly supervised grounding in context of visual question answering in transformers. The approach leverages capsules by grouping each visual token in the visual encoder and uses activations from language self-attention layers as a text-guided selection module to mask those capsules before they are forwarded to the next layer. We evaluate our approach on the challenging GQA as well as VQA-HAT dataset for VQA grounding. Our experiments show that: while removing the information of masked objects from standard transformer architectures leads to a significant drop in performance, the integration of capsules significantly improves the grounding ability of such systems and provides new state-of-the-art results compared to other approaches in the field.