 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThat was the last straw, we need more: Are Translation Systems Sensitive to Disambiguating Context?
Oct 23, 2023The translation of ambiguous text presents a challenge for translation systems, as it requires using the surrounding context to disambiguate the intended meaning as much as possible. While prior work has studied ambiguities that result from different grammatical features of the source and target language, we study semantic ambiguities that exist in the source (English in this work) itself. In particular, we focus on idioms that are open to both literal and figurative interpretations (e.g., goose egg), and collect TIDE, a dataset of 512 pairs of English sentences containing idioms with disambiguating context such that one is literal (it laid a goose egg) and another is figurative (they scored a goose egg, as in a score of zero). In experiments, we compare MT-specific models and language models for (i) their preference when given an ambiguous subsentence, (ii) their sensitivity to disambiguating context, and (iii) the performance disparity between figurative and literal source sentences. We find that current MT models consistently translate English idioms literally, even when the context suggests a figurative interpretation. On the other hand, LMs are far more context-aware, although there remain disparities across target languages. Our findings underline the potential of LMs as a strong backbone for context-aware translation.
BUFFET: Benchmarking Large Language Models for Few-shot Cross-lingual Transfer
May 24, 2023



Despite remarkable advancements in few-shot generalization in natural language processing, most models are developed and evaluated primarily in English. To facilitate research on few-shot cross-lingual transfer, we introduce a new benchmark, called BUFFET, which unifies 15 diverse tasks across 54 languages in a sequence-to-sequence format and provides a fixed set of few-shot examples and instructions. BUFFET is designed to establish a rigorous and equitable evaluation framework for few-shot cross-lingual transfer across a broad range of tasks and languages. Using BUFFET, we perform thorough evaluations of state-of-the-art multilingual large language models with different transfer methods, namely in-context learning and fine-tuning. Our findings reveal significant room for improvement in few-shot in-context cross-lingual transfer. In particular, ChatGPT with in-context learning often performs worse than much smaller mT5-base models fine-tuned on English task data and few-shot in-language examples. Our analysis suggests various avenues for future research in few-shot cross-lingual transfer, such as improved pretraining, understanding, and future evaluations.
Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models
May 23, 2023Language models have graduated from being research prototypes to commercialized products offered as web APIs, and recent works have highlighted the multilingual capabilities of these products. The API vendors charge their users based on usage, more specifically on the number of ``tokens'' processed or generated by the underlying language models. What constitutes a token, however, is training data and model dependent with a large variance in the number of tokens required to convey the same information in different languages. In this work, we analyze the effect of this non-uniformity on the fairness of an API's pricing policy across languages. We conduct a systematic analysis of the cost and utility of OpenAI's language model API on multilingual benchmarks in 22 typologically diverse languages. We show evidence that speakers of a large number of the supported languages are overcharged while obtaining poorer results. These speakers tend to also come from regions where the APIs are less affordable to begin with. Through these analyses, we aim to increase transparency around language model APIs' pricing policies and encourage the vendors to make them more equitable.
Dictionary-based Phrase-level Prompting of Large Language Models for Machine Translation
Feb 15, 2023



Large language models (LLMs) demonstrate remarkable machine translation (MT) abilities via prompting, even though they were not explicitly trained for this task. However, even given the incredible quantities of data they are trained on, LLMs can struggle to translate inputs with rare words, which are common in low resource or domain transfer scenarios. We show that LLM prompting can provide an effective solution for rare words as well, by using prior knowledge from bilingual dictionaries to provide control hints in the prompts. We propose a novel method, DiPMT, that provides a set of possible translations for a subset of the input words, thereby enabling fine-grained phrase-level prompted control of the LLM. Extensive experiments show that DiPMT outperforms the baseline both in low-resource MT, as well as for out-of-domain MT. We further provide a qualitative analysis of the benefits and limitations of this approach, including the overall level of controllability that is achieved.
XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models
Jan 25, 2023



Large multilingual language models typically rely on a single vocabulary shared across 100+ languages. As these models have increased in parameter count and depth, vocabulary size has remained largely unchanged. This vocabulary bottleneck limits the representational capabilities of multilingual models like XLM-R. In this paper, we introduce a new approach for scaling to very large multilingual vocabularies by de-emphasizing token sharing between languages with little lexical overlap and assigning vocabulary capacity to achieve sufficient coverage for each individual language. Tokenizations using our vocabulary are typically more semantically meaningful and shorter compared to XLM-R. Leveraging this improved vocabulary, we train XLM-V, a multilingual language model with a one million token vocabulary. XLM-V outperforms XLM-R on every task we tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).
Toward Human Readable Prompt Tuning: Kubrick's The Shining is a good movie, and a good prompt too?
Dec 20, 2022



Large language models can perform new tasks in a zero-shot fashion, given natural language prompts that specify the desired behavior. Such prompts are typically hand engineered, but can also be learned with gradient-based methods from labeled data. However, it is underexplored what factors make the prompts effective, especially when the prompts are natural language. In this paper, we investigate common attributes shared by effective prompts. We first propose a human readable prompt tuning method (F LUENT P ROMPT) based on Langevin dynamics that incorporates a fluency constraint to find a diverse distribution of effective and fluent prompts. Our analysis reveals that effective prompts are topically related to the task domain and calibrate the prior probability of label words. Based on these findings, we also propose a method for generating prompts using only unlabeled data, outperforming strong baselines by an average of 7.0% accuracy across three tasks.
Demystifying Prompts in Language Models via Perplexity Estimation
Dec 08, 2022



Language models can be prompted to perform a wide variety of zero- and few-shot learning problems. However, performance varies significantly with the choice of prompt, and we do not yet understand why this happens or how to pick the best prompts. In this work, we analyze the factors that contribute to this variance and establish a new empirical hypothesis: the performance of a prompt is coupled with the extent to which the model is familiar with the language it contains. Over a wide range of tasks, we show that the lower the perplexity of the prompt is, the better the prompt is able to perform the task. As a result, we devise a method for creating prompts: (1) automatically extend a small seed set of manually written prompts by paraphrasing using GPT3 and backtranslation and (2) choose the lowest perplexity prompts to get significant gains in performance.
Prompting Language Models for Linguistic Structure
Nov 15, 2022



Although pretrained language models (PLMs) can be prompted to perform a wide range of language tasks, it remains an open question how much this ability comes from generalizable linguistic representations versus more surface-level lexical patterns. To test this, we present a structured prompting approach that can be used to prompt for linguistic structure prediction tasks, allowing us to perform zero- and few-shot sequence tagging with autoregressive PLMs. We evaluate this approach on part-of-speech tagging, named entity recognition, and sentence chunking and demonstrate strong few-shot performance in all cases. We also find that, though the surface forms of the tags provide some signal, structured prompting can retrieve linguistic structure even with arbitrary labels, indicating that PLMs contain this knowledge in a general manner robust to label choice.
Analyzing the Mono- and Cross-Lingual Pretraining Dynamics of Multilingual Language Models
May 24, 2022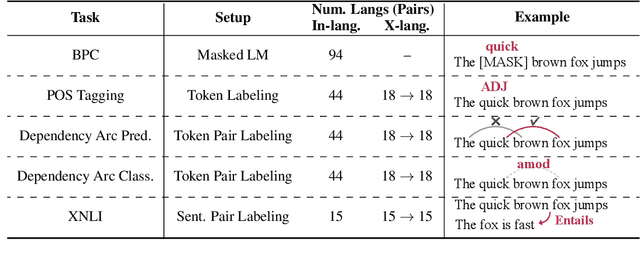

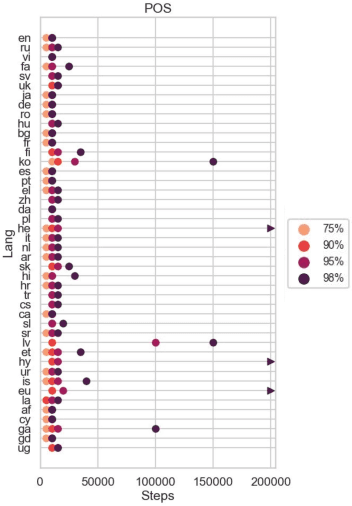
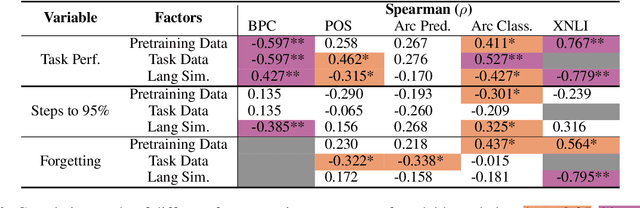
The emergent cross-lingual transfer seen in multilingual pretrained models has sparked significant interest in studying their behavior. However, because these analyses have focused on fully trained multilingual models, little is known about the dynamics of the multilingual pretraining process. We investigate when these models acquire their in-language and cross-lingual abilities by probing checkpoints taken from throughout XLM-R pretraining, using a suite of linguistic tasks. Our analysis shows that the model achieves high in-language performance early on, with lower-level linguistic skills acquired before more complex ones. In contrast, when the model learns to transfer cross-lingually depends on the language pair. Interestingly, we also observe that, across many languages and tasks, the final, converged model checkpoint exhibits significant performance degradation and that no one checkpoint performs best on all languages. Taken together with our other findings, these insights highlight the complexity and interconnectedness of multilingual pretraining.
Analyzing Gender Representation in Multilingual Models
Apr 20, 2022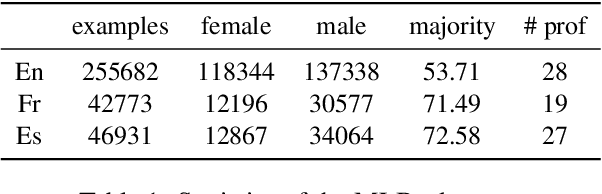
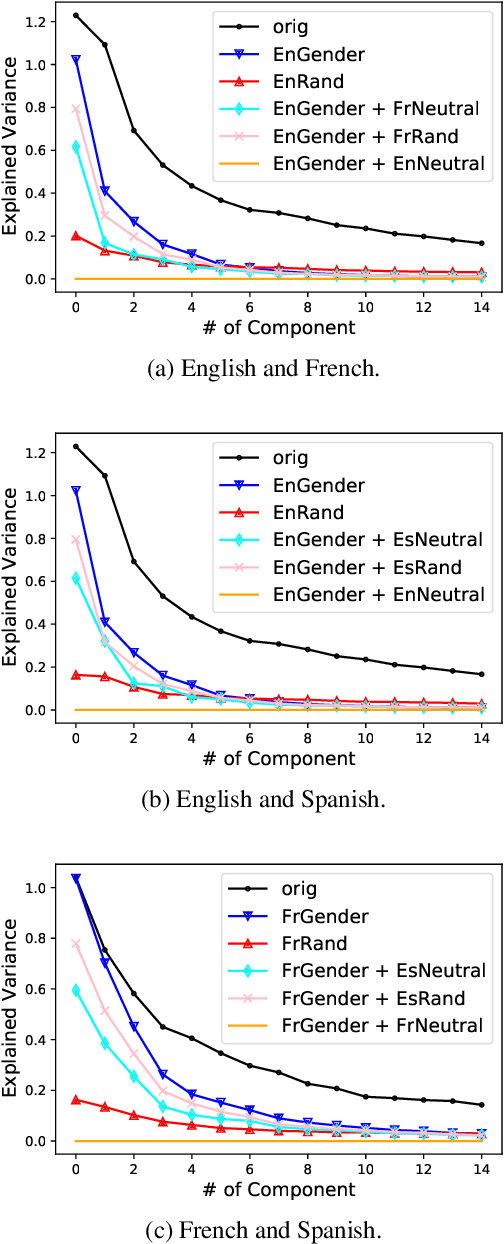
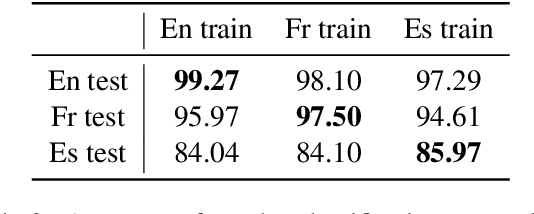
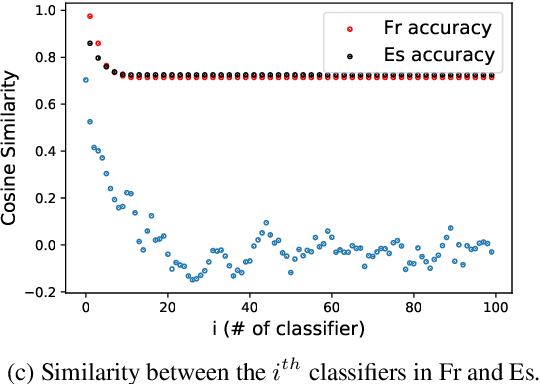
Multilingual language models were shown to allow for nontrivial transfer across scripts and languages. In this work, we study the structure of the internal representations that enable this transfer. We focus on the representation of gender distinctions as a practical case study, and examine the extent to which the gender concept is encoded in shared subspaces across different languages. Our analysis shows that gender representations consist of several prominent components that are shared across languages, alongside language-specific components. The existence of language-independent and language-specific components provides an explanation for an intriguing empirical observation we make: while gender classification transfers well across languages, interventions for gender removal, trained on a single language, do not transfer easily to others.