 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMS: Hierarchical Modality Selection for Efficient Video Recognition
Apr 21, 2021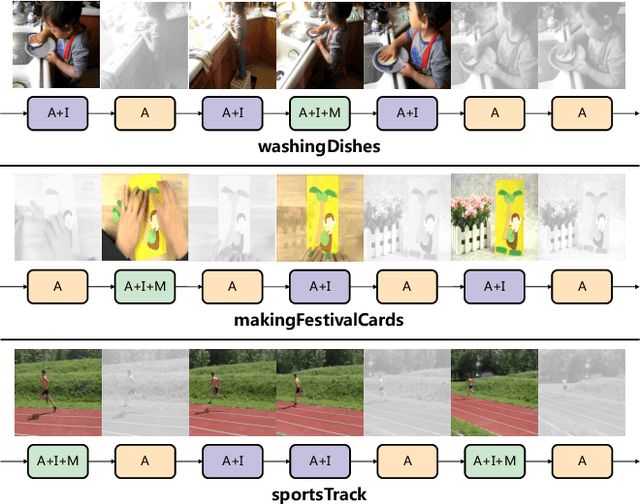
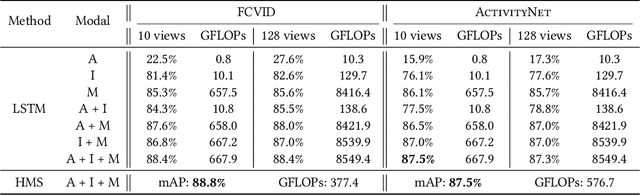
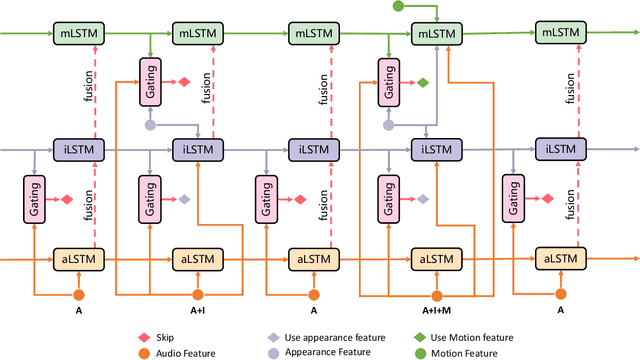
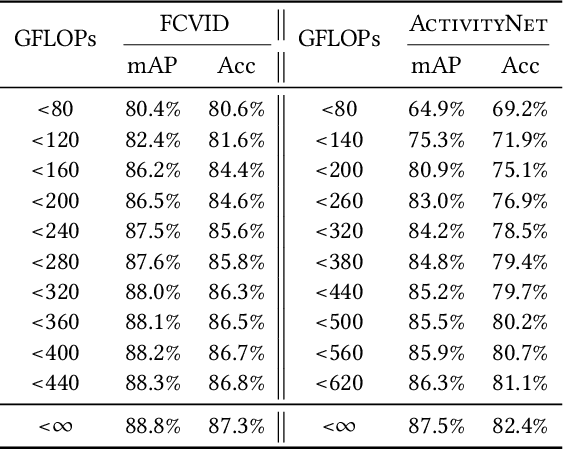
Videos are multimodal in nature. Conventional video recognition pipelines typically fuse multimodal features for improved performance. However, this is not only computationally expensive but also neglects the fact that different videos rely on different modalities for predictions. This paper introduces Hierarchical Modality Selection (HMS), a simple yet efficient multimodal learning framework for efficient video recognition. HMS operates on a low-cost modality, i.e., audio clues, by default, and dynamically decides on-the-fly whether to use computationally-expensive modalities, including appearance and motion clues, on a per-input basis. This is achieved by the collaboration of three LSTMs that are organized in a hierarchical manner. In particular, LSTMs that operate on high-cost modalities contain a gating module, which takes as inputs lower-level features and historical information to adaptively determine whether to activate its corresponding modality; otherwise it simply reuses historical information. We conduct extensive experiments on two large-scale video benchmarks, FCVID and ActivityNet, and the results demonstrate the proposed approach can effectively explore multimodal information for improved classification performance while requiring much less computation.
2D or not 2D? Adaptive 3D Convolution Selection for Efficient Video Recognition
Dec 29, 2020
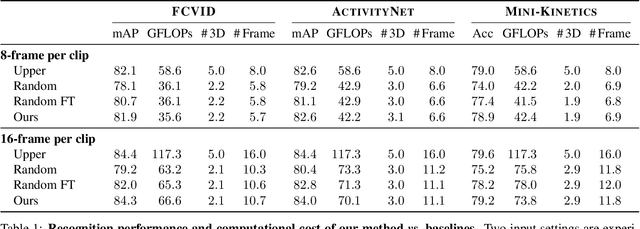
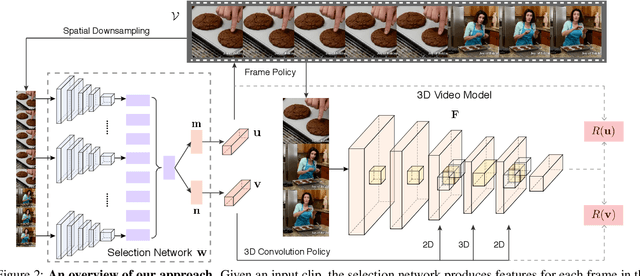

3D convolutional networks are prevalent for video recognition. While achieving excellent recognition performance on standard benchmarks, they operate on a sequence of frames with 3D convolutions and thus are computationally demanding. Exploiting large variations among different videos, we introduce Ada3D, a conditional computation framework that learns instance-specific 3D usage policies to determine frames and convolution layers to be used in a 3D network. These policies are derived with a two-head lightweight selection network conditioned on each input video clip. Then, only frames and convolutions that are selected by the selection network are used in the 3D model to generate predictions. The selection network is optimized with policy gradient methods to maximize a reward that encourages making correct predictions with limited computation. We conduct experiments on three video recognition benchmarks and demonstrate that our method achieves similar accuracies to state-of-the-art 3D models while requiring 20%-50% less computation across different datasets. We also show that learned policies are transferable and Ada3D is compatible to different backbones and modern clip selection approaches. Our qualitative analysis indicates that our method allocates fewer 3D convolutions and frames for "static" inputs, yet uses more for motion-intensive clips.
Improving the Tightness of Convex Relaxation Bounds for Training Certifiably Robust Classifiers
Feb 22, 2020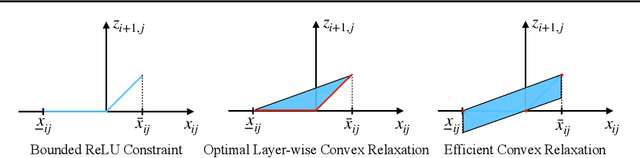
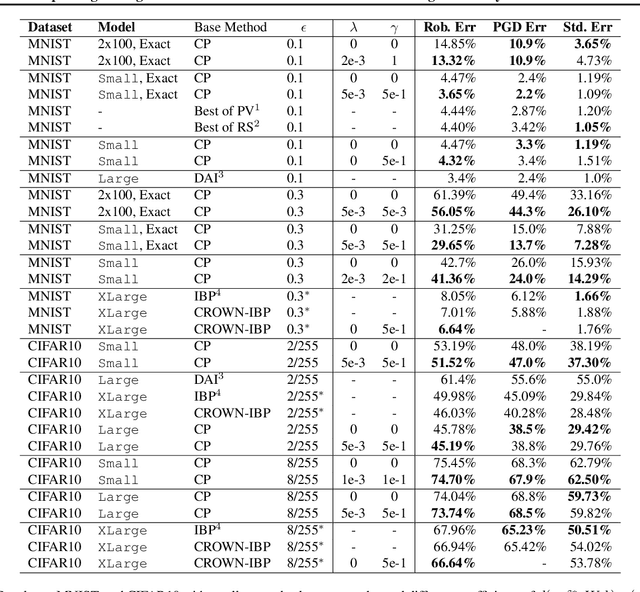
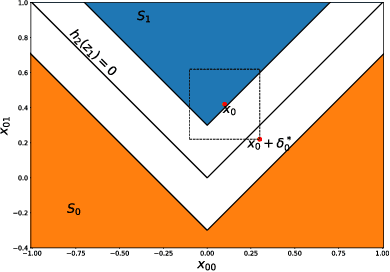

Convex relaxations are effective for training and certifying neural networks against norm-bounded adversarial attacks, but they leave a large gap between certifiable and empirical robustness. In principle, convex relaxation can provide tight bounds if the solution to the relaxed problem is feasible for the original non-convex problem. We propose two regularizers that can be used to train neural networks that yield tighter convex relaxation bounds for robustness. In all of our experiments, the proposed regularizers result in higher certified accuracy than non-regularized baselines.
Learning from Noisy Anchors for One-stage Object Detection
Dec 11, 2019
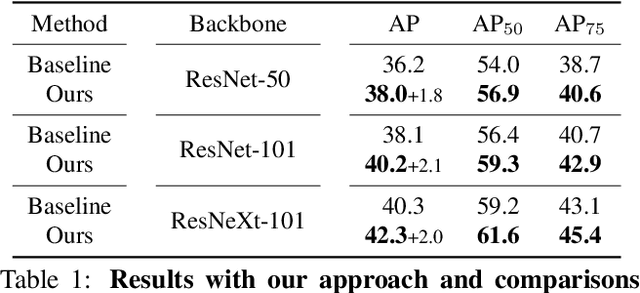
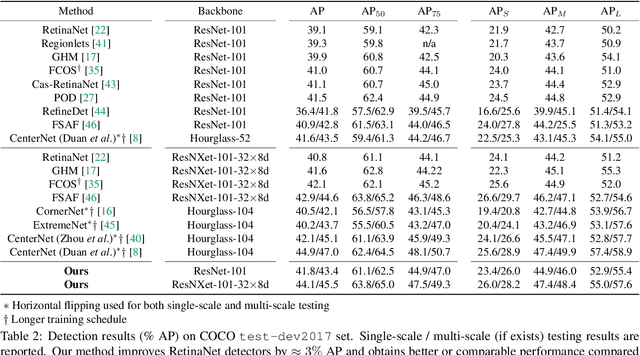
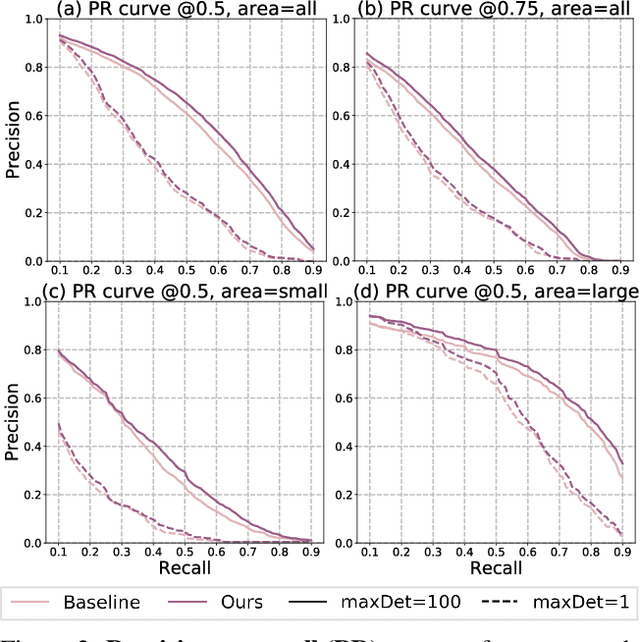
State-of-the-art object detectors rely on regressing and classifying an extensive list of possible anchors, which are divided into positive and negative samples based on their intersection-over-union (IoU) with corresponding groundtruth objects. Such a harsh split conditioned on IoU results in binary labels that are potentially noisy and challenging for training. In this paper, we propose to mitigate noise incurred by imperfect label assignment such that the contributions of anchors are dynamically determined by a carefully constructed cleanliness score associated with each anchor. Exploring outputs from both regression and classification branches, the cleanliness scores, estimated without incurring any additional computational overhead, are used not only as soft labels to supervise the training of the classification branch but also sample re-weighting factors for improved localization and classification accuracy. We conduct extensive experiments on COCO, and demonstrate, among other things, the proposed approach steadily improves RetinaNet by ~2% with various backbones.
Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
May 16, 2019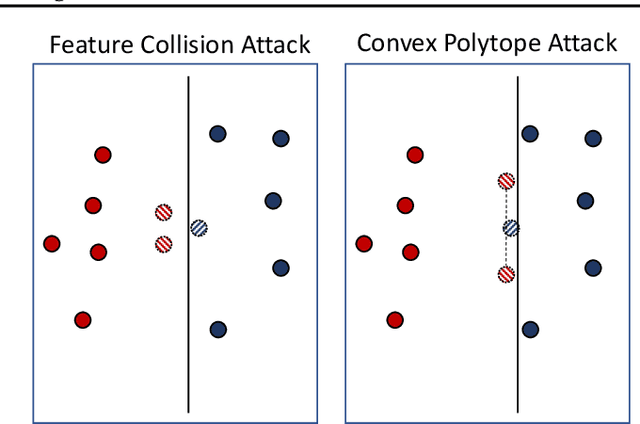

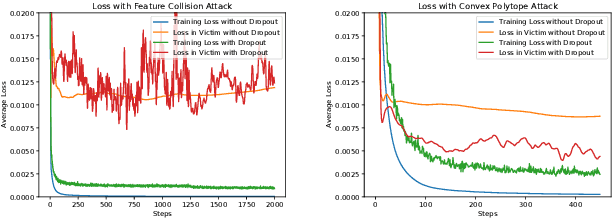

Clean-label poisoning attacks inject innocuous looking (and "correctly" labeled) poison images into training data, causing a model to misclassify a targeted image after being trained on this data. We consider transferable poisoning attacks that succeed without access to the victim network's outputs, architecture, or (in some cases) training data. To achieve this, we propose a new "polytope attack" in which poison images are designed to surround the targeted image in feature space. We also demonstrate that using Dropout during poison creation helps to enhance transferability of this attack. We achieve transferable attack success rates of over 50% while poisoning only 1% of the training set.
An Analysis of Pre-Training on Object Detection
Apr 11, 2019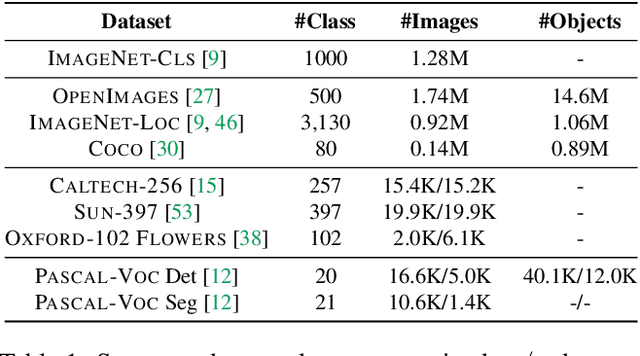
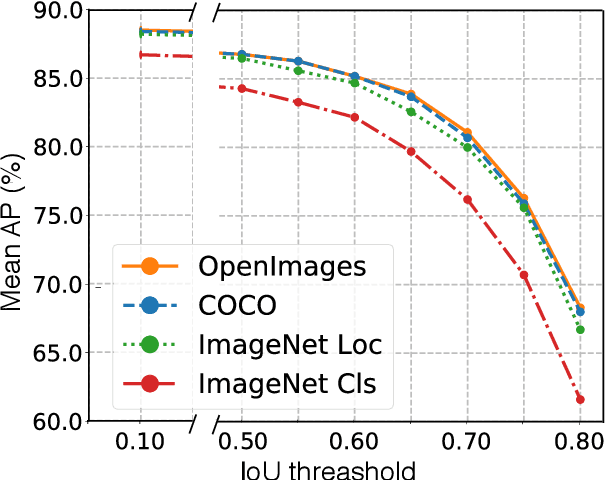
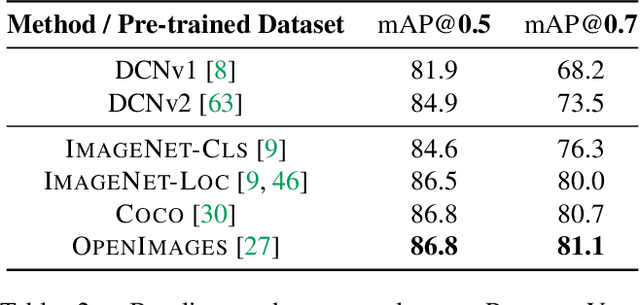

We provide a detailed analysis of convolutional neural networks which are pre-trained on the task of object detection. To this end, we train detectors on large datasets like OpenImagesV4, ImageNet Localization and COCO. We analyze how well their features generalize to tasks like image classification, semantic segmentation and object detection on small datasets like PASCAL-VOC, Caltech-256, SUN-397, Flowers-102 etc. Some important conclusions from our analysis are --- 1) Pre-training on large detection datasets is crucial for fine-tuning on small detection datasets, especially when precise localization is needed. For example, we obtain 81.1% mAP on the PASCAL-VOC dataset at 0.7 IoU after pre-training on OpenImagesV4, which is 7.6% better than the recently proposed DeformableConvNetsV2 which uses ImageNet pre-training. 2) Detection pre-training also benefits other localization tasks like semantic segmentation but adversely affects image classification. 3) Features for images (like avg. pooled Conv5) which are similar in the object detection feature space are likely to be similar in the image classification feature space but the converse is not true. 4) Visualization of features reveals that detection neurons have activations over an entire object, while activations for classification networks typically focus on parts. Therefore, detection networks are poor at classification when multiple instances are present in an image or when an instance only covers a small fraction of an image.
R-FCN-3000 at 30fps: Decoupling Detection and Classification
Dec 05, 2017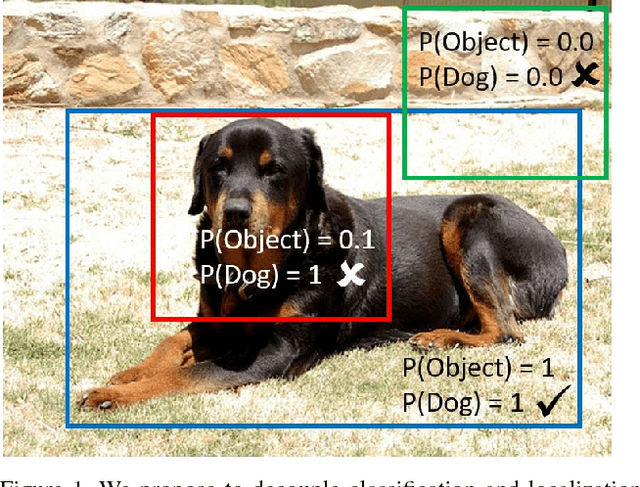
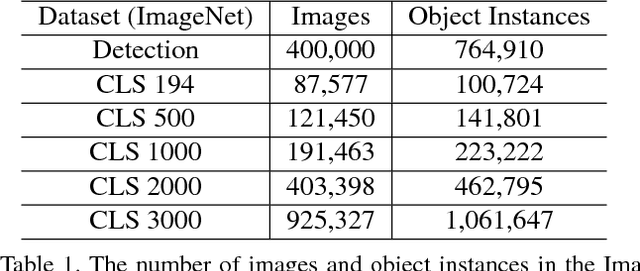
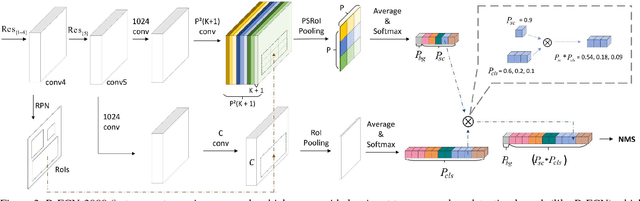

We present R-FCN-3000, a large-scale real-time object detector in which objectness detection and classification are decoupled. To obtain the detection score for an RoI, we multiply the objectness score with the fine-grained classification score. Our approach is a modification of the R-FCN architecture in which position-sensitive filters are shared across different object classes for performing localization. For fine-grained classification, these position-sensitive filters are not needed. R-FCN-3000 obtains an mAP of 34.9% on the ImageNet detection dataset and outperforms YOLO-9000 by 18% while processing 30 images per second. We also show that the objectness learned by R-FCN-3000 generalizes to novel classes and the performance increases with the number of training object classes - supporting the hypothesis that it is possible to learn a universal objectness detector. Code will be made available.
Multi-Glimpse LSTM with Color-Depth Feature Fusion for Human Detection
Nov 03, 2017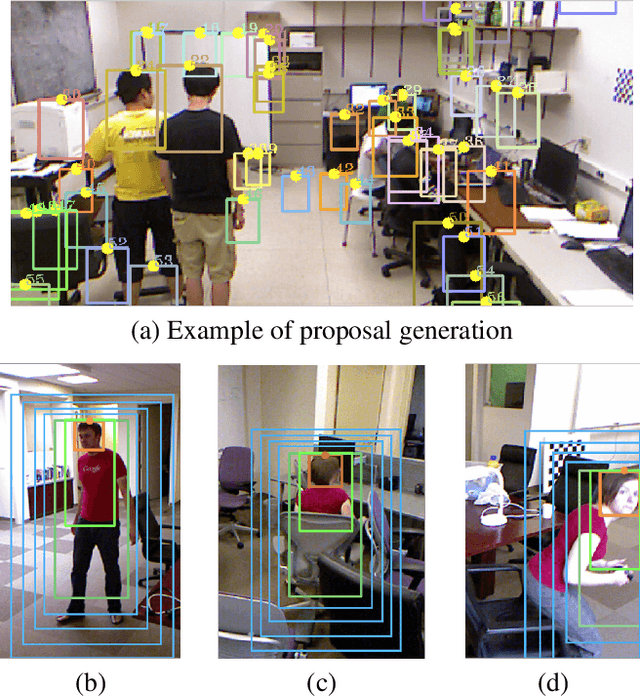
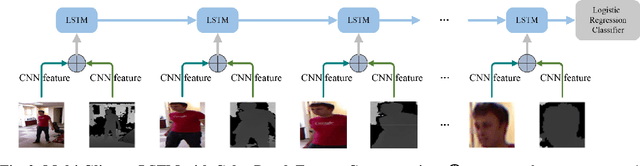

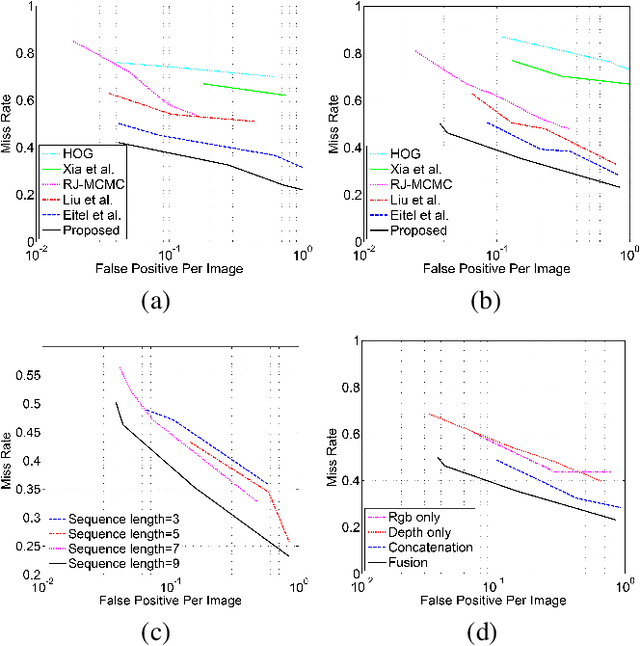
With the development of depth cameras such as Kinect and Intel Realsense, RGB-D based human detection receives continuous research attention due to its usage in a variety of applications. In this paper, we propose a new Multi-Glimpse LSTM (MG-LSTM) network, in which multi-scale contextual information is sequentially integrated to promote the human detection performance. Furthermore, we propose a feature fusion strategy based on our MG-LSTM network to better incorporate the RGB and depth information. To the best of our knowledge, this is the first attempt to utilize LSTM structure for RGB-D based human detection. Our method achieves superior performance on two publicly available datasets.