 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval
Aug 19, 2020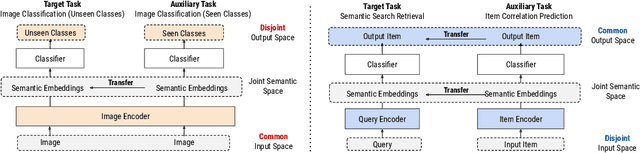

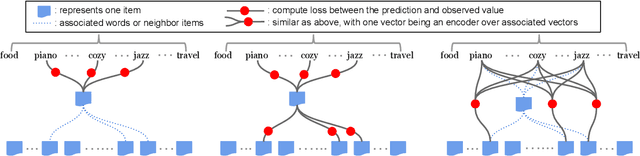
Many recent advances in neural information retrieval models, which predict top-K items given a query, learn directly from a large training set of (query, item) pairs. However, they are often insufficient when there are many previously unseen (query, item) combinations, often referred to as the cold start problem. Furthermore, the search system can be biased towards items that are frequently shown to a query previously, also known as the 'rich get richer' (a.k.a. feedback loop) problem. In light of these problems, we observed that most online content platforms have both a search and a recommender system that, while having heterogeneous input spaces, can be connected through their common output item space and a shared semantic representation. In this paper, we propose a new Zero-Shot Heterogeneous Transfer Learning framework that transfers learned knowledge from the recommender system component to improve the search component of a content platform. First, it learns representations of items and their natural-language features by predicting (item, item) correlation graphs derived from the recommender system as an auxiliary task. Then, the learned representations are transferred to solve the target search retrieval task, performing query-to-item prediction without having seen any (query, item) pairs in training. We conduct online and offline experiments on one of the world's largest search and recommender systems from Google, and present the results and lessons learned. We demonstrate that the proposed approach can achieve high performance on offline search retrieval tasks, and more importantly, achieved significant improvements on relevance and user interactions over the highly-optimized production system in online experiments.
Data Efficient Training for Reinforcement Learning with Adaptive Behavior Policy Sharing
Feb 12, 2020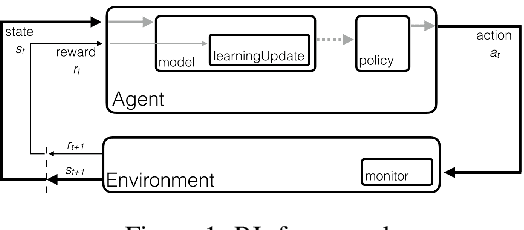
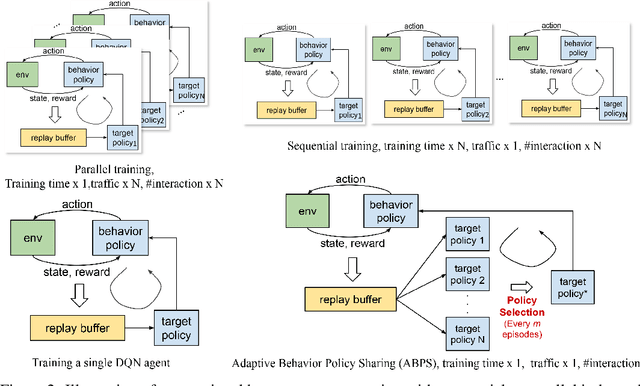
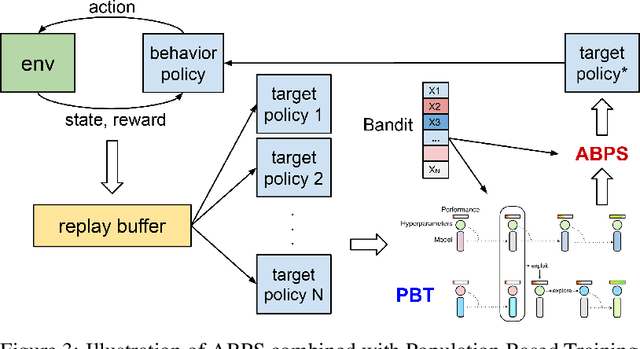
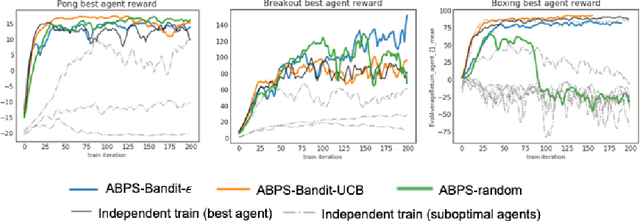
Deep Reinforcement Learning (RL) is proven powerful for decision making in simulated environments. However, training deep RL model is challenging in real world applications such as production-scale health-care or recommender systems because of the expensiveness of interaction and limitation of budget at deployment. One aspect of the data inefficiency comes from the expensive hyper-parameter tuning when optimizing deep neural networks. We propose Adaptive Behavior Policy Sharing (ABPS), a data-efficient training algorithm that allows sharing of experience collected by behavior policy that is adaptively selected from a pool of agents trained with an ensemble of hyper-parameters. We further extend ABPS to evolve hyper-parameters during training by hybridizing ABPS with an adapted version of Population Based Training (ABPS-PBT). We conduct experiments with multiple Atari games with up to 16 hyper-parameter/architecture setups. ABPS achieves superior overall performance, reduced variance on top 25% agents, and equivalent performance on the best agent compared to conventional hyper-parameter tuning with independent training, even though ABPS only requires the same number of environmental interactions as training a single agent. We also show that ABPS-PBT further improves the convergence speed and reduces the variance.
Modeling Information Need of Users in Search Sessions
Jan 03, 2020


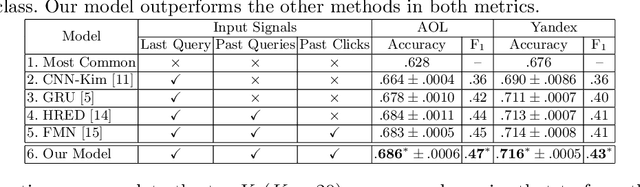
Users issue queries to Search Engines, and try to find the desired information in the results produced. They repeat this process if their information need is not met at the first place. It is crucial to identify the important words in a query that depict the actual information need of the user and will determine the course of a search session. To this end, we propose a sequence-to-sequence based neural architecture that leverages the set of past queries issued by users, and results that were explored by them. Firstly, we employ our model for predicting the words in the current query that are important and would be retained in the next query. Additionally, as a downstream application of our model, we evaluate it on the widely popular task of next query suggestion. We show that our intuitive strategy of capturing information need can yield superior performance at these tasks on two large real-world search log datasets.
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
May 31, 2019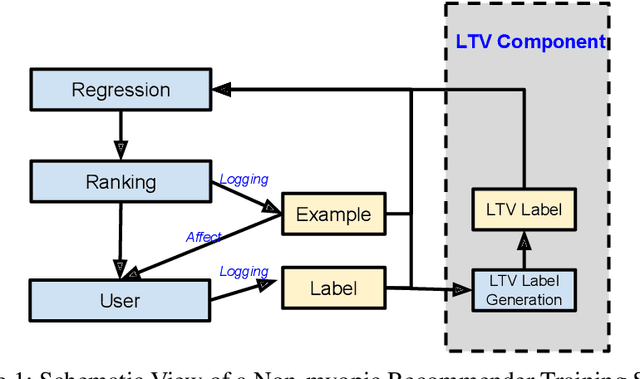
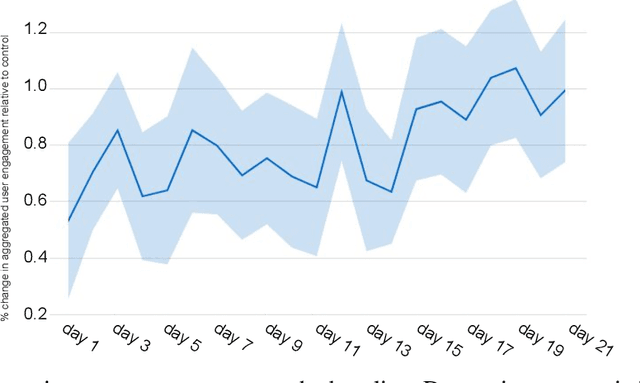
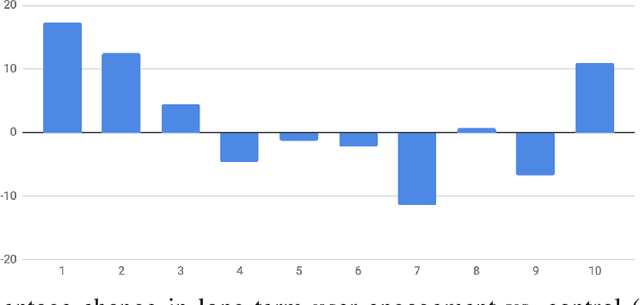
Most practical recommender systems focus on estimating immediate user engagement without considering the long-term effects of recommendations on user behavior. Reinforcement learning (RL) methods offer the potential to optimize recommendations for long-term user engagement. However, since users are often presented with slates of multiple items - which may have interacting effects on user choice - methods are required to deal with the combinatorics of the RL action space. In this work, we address the challenge of making slate-based recommendations to optimize long-term value using RL. Our contributions are three-fold. (i) We develop SLATEQ, a decomposition of value-based temporal-difference and Q-learning that renders RL tractable with slates. Under mild assumptions on user choice behavior, we show that the long-term value (LTV) of a slate can be decomposed into a tractable function of its component item-wise LTVs. (ii) We outline a methodology that leverages existing myopic learning-based recommenders to quickly develop a recommender that handles LTV. (iii) We demonstrate our methods in simulation, and validate the scalability of decomposed TD-learning using SLATEQ in live experiments on YouTube.
TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks
Aug 08, 2017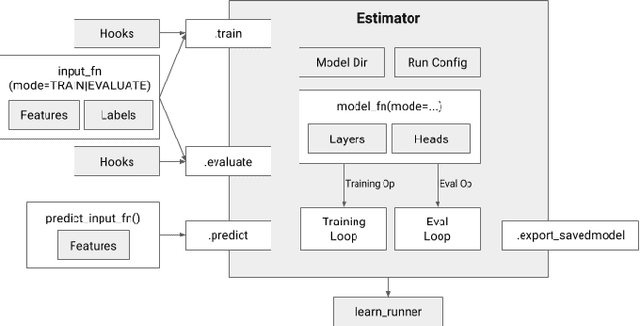
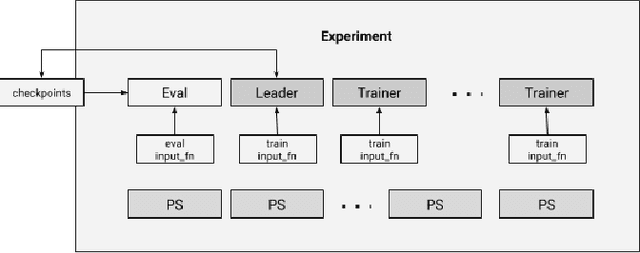
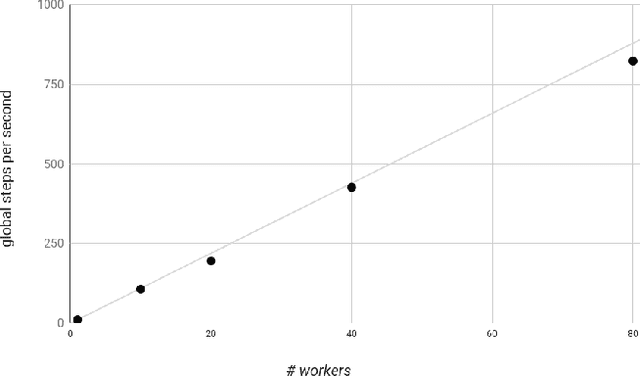
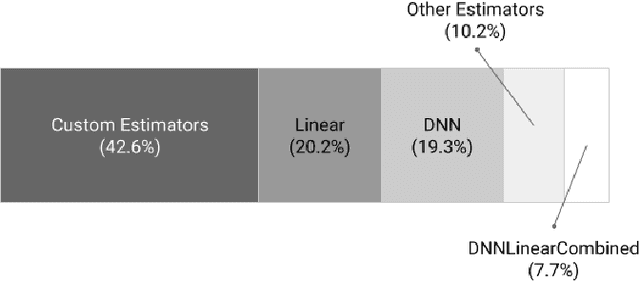
We present a framework for specifying, training, evaluating, and deploying machine learning models. Our focus is on simplifying cutting edge machine learning for practitioners in order to bring such technologies into production. Recognizing the fast evolution of the field of deep learning, we make no attempt to capture the design space of all possible model architectures in a domain- specific language (DSL) or similar configuration language. We allow users to write code to define their models, but provide abstractions that guide develop- ers to write models in ways conducive to productionization. We also provide a unifying Estimator interface, making it possible to write downstream infrastructure (e.g. distributed training, hyperparameter tuning) independent of the model implementation. We balance the competing demands for flexibility and simplicity by offering APIs at different levels of abstraction, making common model architectures available out of the box, while providing a library of utilities designed to speed up experimentation with model architectures. To make out of the box models flexible and usable across a wide range of problems, these canned Estimators are parameterized not only over traditional hyperparameters, but also using feature columns, a declarative specification describing how to interpret input data. We discuss our experience in using this framework in re- search and production environments, and show the impact on code health, maintainability, and development speed.
Wide & Deep Learning for Recommender Systems
Jun 24, 2016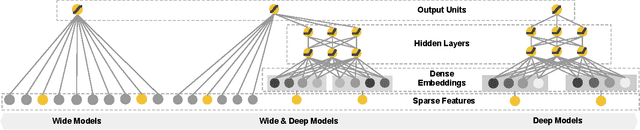
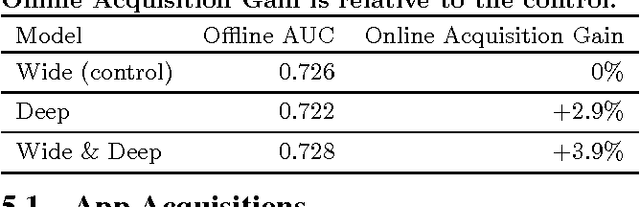

Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformations are effective and interpretable, while generalization requires more feature engineering effort. With less feature engineering, deep neural networks can generalize better to unseen feature combinations through low-dimensional dense embeddings learned for the sparse features. However, deep neural networks with embeddings can over-generalize and recommend less relevant items when the user-item interactions are sparse and high-rank. In this paper, we present Wide & Deep learning---jointly trained wide linear models and deep neural networks---to combine the benefits of memorization and generalization for recommender systems. We productionized and evaluated the system on Google Play, a commercial mobile app store with over one billion active users and over one million apps. Online experiment results show that Wide & Deep significantly increased app acquisitions compared with wide-only and deep-only models. We have also open-sourced our implementation in TensorFlow.