 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation
Mar 31, 2020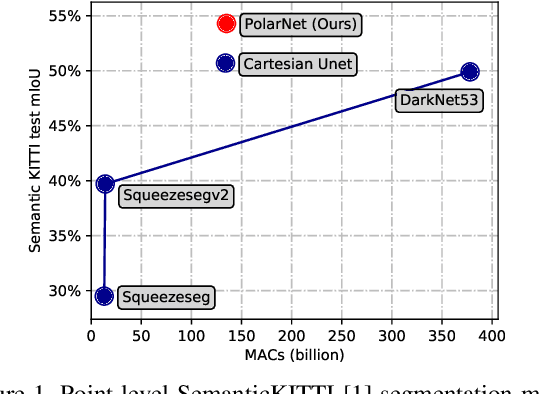

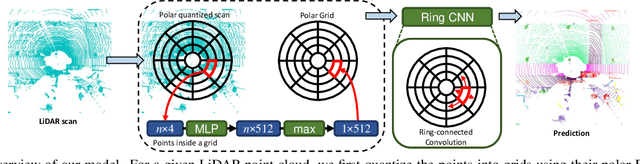
The requirement of fine-grained perception by autonomous driving systems has resulted in recently increased research in the online semantic segmentation of single-scan LiDAR. Emerging datasets and technological advancements have enabled researchers to benchmark this problem and improve the applicable semantic segmentation algorithms. Still, online semantic segmentation of LiDAR scans in autonomous driving applications remains challenging due to three reasons: (1) the need for near-real-time latency with limited hardware, (2) points are distributed unevenly across space, and (3) an increasing number of more fine-grained semantic classes. The combination of the aforementioned challenges motivates us to propose a new LiDAR-specific, KNN-free segmentation algorithm - PolarNet. Instead of using common spherical or bird's-eye-view projection, our polar bird's-eye-view representation balances the points per grid and thus indirectly redistributes the network's attention over the long-tailed points distribution over the radial axis in polar coordination. We find that our encoding scheme greatly increases the mIoU in three drastically different real urban LiDAR single-scan segmentation datasets while retaining ultra low latency and near real-time throughput.
Self-Attention Network for Skeleton-based Human Action Recognition
Dec 18, 2019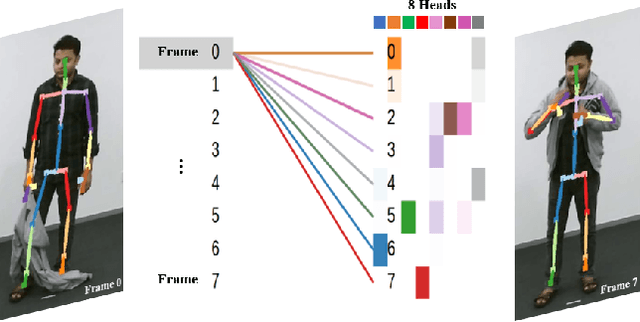
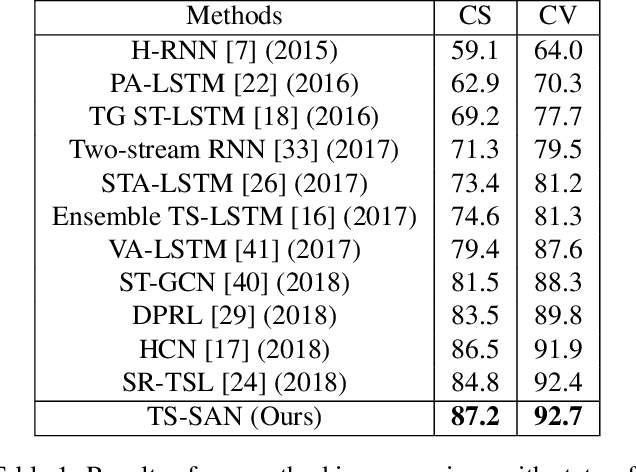
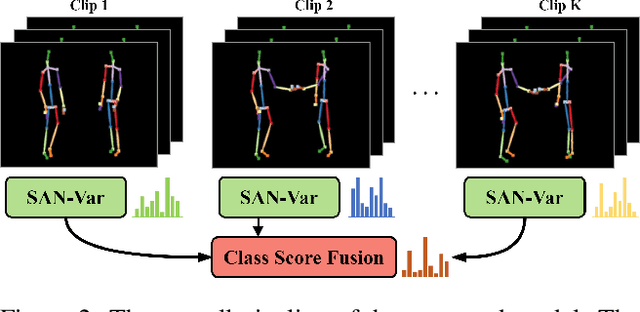
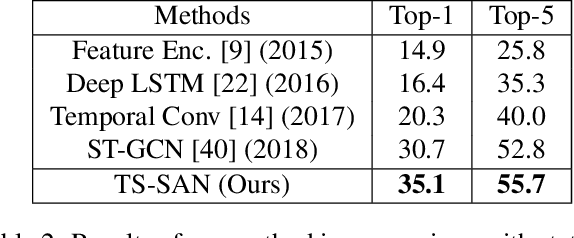
Skeleton-based action recognition has recently attracted a lot of attention. Researchers are coming up with new approaches for extracting spatio-temporal relations and making considerable progress on large-scale skeleton-based datasets. Most of the architectures being proposed are based upon recurrent neural networks (RNNs), convolutional neural networks (CNNs) and graph-based CNNs. When it comes to skeleton-based action recognition, the importance of long term contextual information is central which is not captured by the current architectures. In order to come up with a better representation and capturing of long term spatio-temporal relationships, we propose three variants of Self-Attention Network (SAN), namely, SAN-V1, SAN-V2 and SAN-V3. Our SAN variants has the impressive capability of extracting high-level semantics by capturing long-range correlations. We have also integrated the Temporal Segment Network (TSN) with our SAN variants which resulted in improved overall performance. Different configurations of Self-Attention Network (SAN) variants and Temporal Segment Network (TSN) are explored with extensive experiments. Our chosen configuration outperforms state-of-the-art Top-1 and Top-5 by 4.4% and 7.9% respectively on Kinetics and shows consistently better performance than state-of-the-art methods on NTU RGB+D.
Maximum Probability Principle and Black-Box Priors
Nov 03, 2019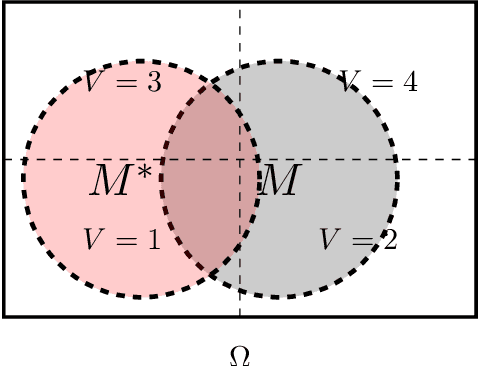
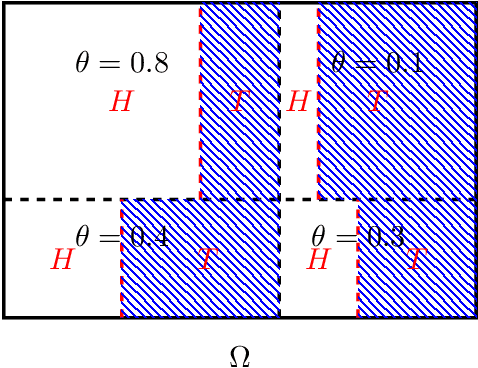
We present an axiomatic way of assigning probabilities to probabilistic models. In particular, we quantify an upper bound for probability of a model or in terms of information theory, a lower bound for amount of information that is assumed in a model. In our setup, maximizing probabilities of models is equivalent to removing assumptions or information stored in the model. Furthermore, we represent the problem of learning from an alternative view where the underlying probability space is considered directly. In this perspective both the true underlying model (Oracle) and the model at hand are events. subsequently, learning is presented in three perspectives: maximizing the likelihood of oracle given model, intersection of model and the oracle and symmetric difference complement of model and the oracle.
Multi-Document Summarization with Determinantal Point Processes and Contextualized Representations
Oct 24, 2019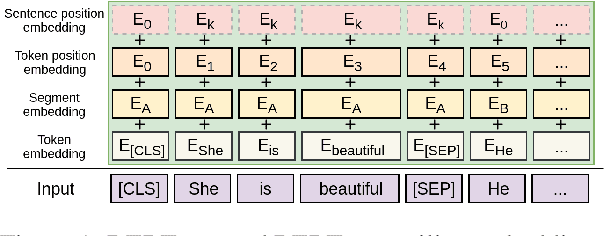
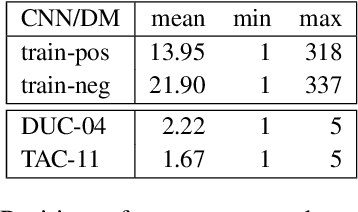
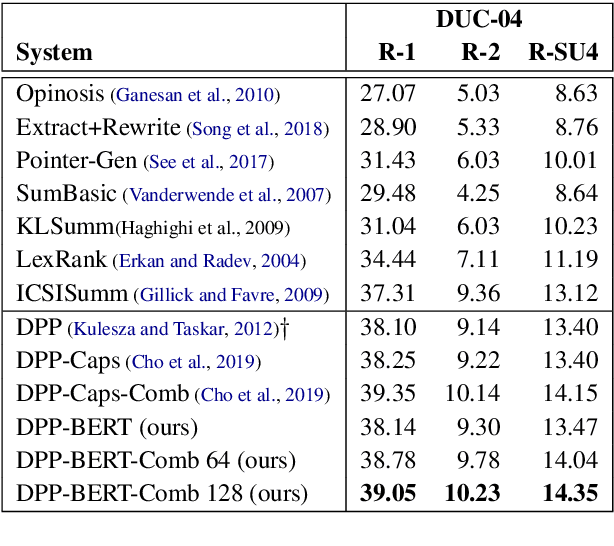
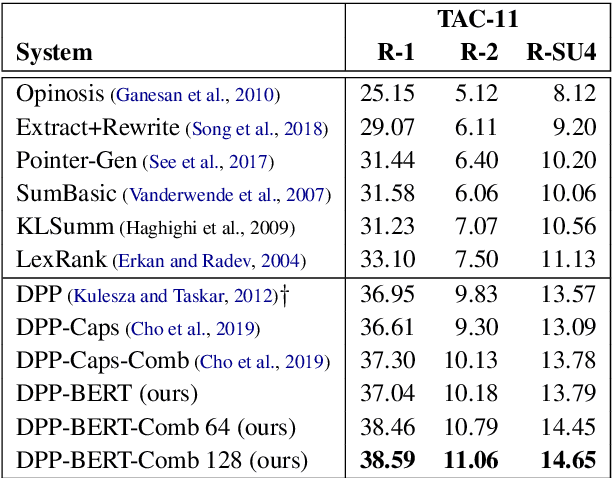
Emerged as one of the best performing techniques for extractive summarization, determinantal point processes select the most probable set of sentences to form a summary according to a probability measure defined by modeling sentence prominence and pairwise repulsion. Traditionally, these aspects are modelled using shallow and linguistically informed features, but the rise of deep contextualized representations raises an interesting question of whether, and to what extent, contextualized representations can be used to improve DPP modeling. Our findings suggest that, despite the success of deep representations, it remains necessary to combine them with surface indicators for effective identification of summary sentences.
Slim-CNN: A Light-Weight CNN for Face Attribute Prediction
Jul 03, 2019
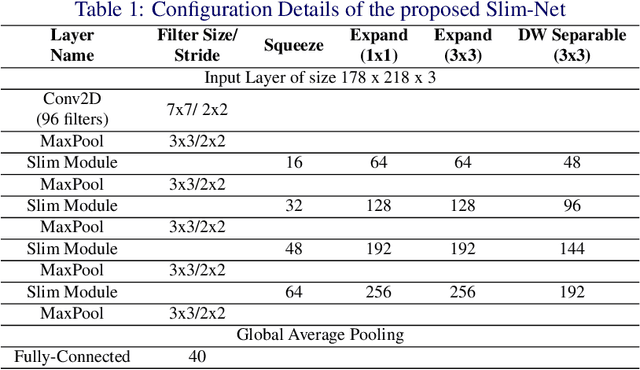
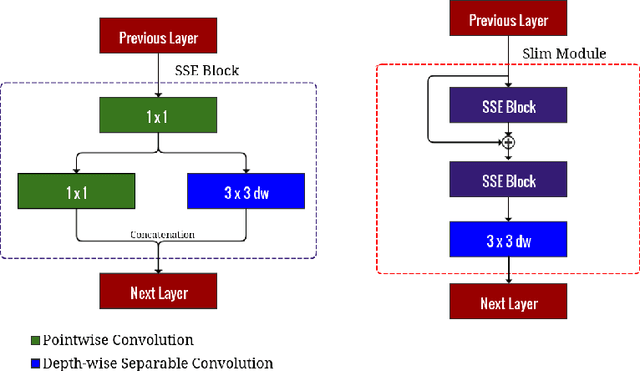
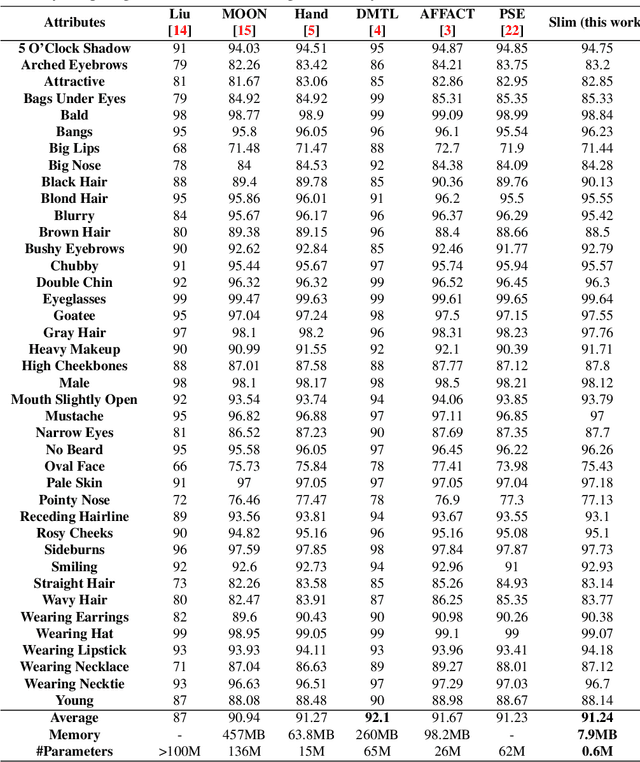
We introduce a computationally-efficient CNN micro-architecture Slim Module to design a lightweight deep neural network Slim-Net for face attribute prediction. Slim Modules are constructed by assembling depthwise separable convolutions with pointwise convolution to produce a computationally efficient module. The problem of facial attribute prediction is challenging because of the large variations in pose, background, illumination, and dataset imbalance. We stack these Slim Modules to devise a compact CNN which still maintains very high accuracy. Additionally, the neural network has a very low memory footprint which makes it suitable for mobile and embedded applications. Experiments on the CelebA dataset show that Slim-Net achieves an accuracy of 91.24% with at least 25 times fewer parameters than comparably performing methods, which reduces the memory storage requirement of Slim-net by at least 87%.
Spatio-Temporal Fusion Networks for Action Recognition
Jun 17, 2019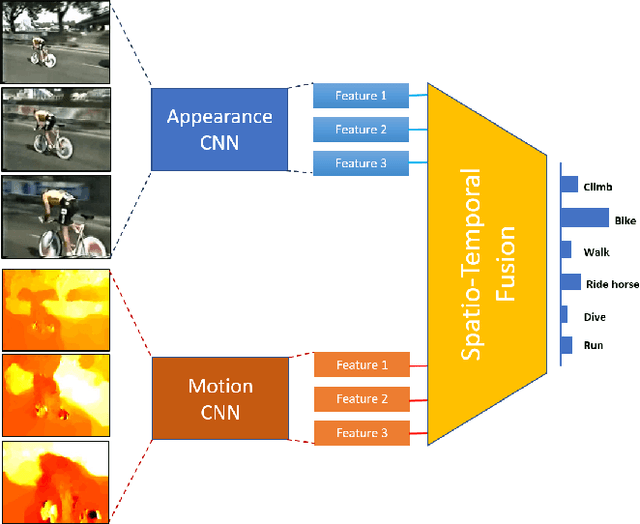

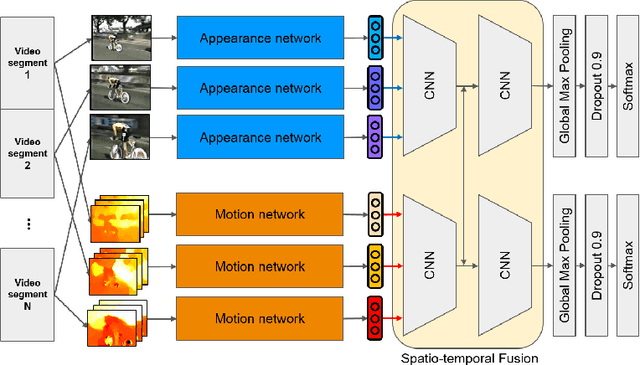

The video based CNN works have focused on effective ways to fuse appearance and motion networks, but they typically lack utilizing temporal information over video frames. In this work, we present a novel spatio-temporal fusion network (STFN) that integrates temporal dynamics of appearance and motion information from entire videos. The captured temporal dynamic information is then aggregated for a better video level representation and learned via end-to-end training. The spatio-temporal fusion network consists of two set of Residual Inception blocks that extract temporal dynamics and a fusion connection for appearance and motion features. The benefits of STFN are: (a) it captures local and global temporal dynamics of complementary data to learn video-wide information; and (b) it is applicable to any network for video classification to boost performance. We explore a variety of design choices for STFN and verify how the network performance is varied with the ablation studies. We perform experiments on two challenging human activity datasets, UCF101 and HMDB51, and achieve the state-of-the-art results with the best network.
A Temporal Sequence Learning for Action Recognition and Prediction
Jun 17, 2019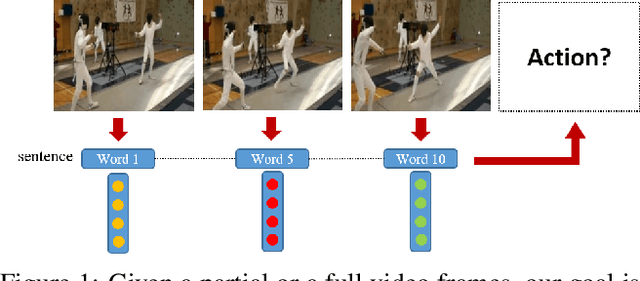
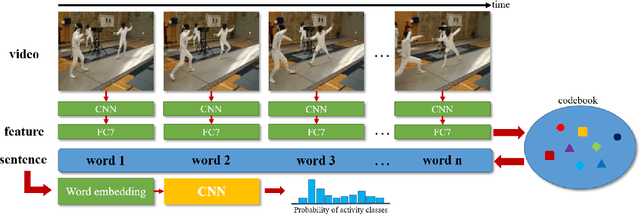
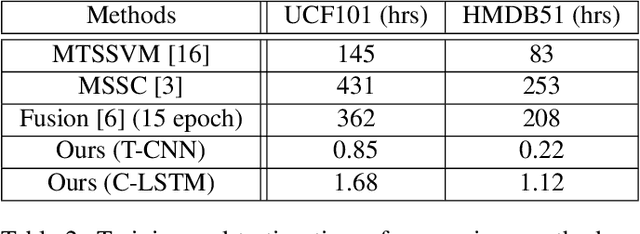
In this work\footnote {This work was supported in part by the National Science Foundation under grant IIS-1212948.}, we present a method to represent a video with a sequence of words, and learn the temporal sequencing of such words as the key information for predicting and recognizing human actions. We leverage core concepts from the Natural Language Processing (NLP) literature used in sentence classification to solve the problems of action prediction and action recognition. Each frame is converted into a word that is represented as a vector using the Bag of Visual Words (BoW) encoding method. The words are then combined into a sentence to represent the video, as a sentence. The sequence of words in different actions are learned with a simple but effective Temporal Convolutional Neural Network (T-CNN) that captures the temporal sequencing of information in a video sentence. We demonstrate that a key characteristic of the proposed method is its low-latency, i.e. its ability to predict an action accurately with a partial sequence (sentence). Experiments on two datasets, \textit{UCF101} and \textit{HMDB51} show that the method on average reaches 95\% of its accuracy within half the video frames. Results, also demonstrate that our method achieves compatible state-of-the-art performance in action recognition (i.e. at the completion of the sentence) in addition to action prediction.
* 10 pages, 8 figures, 2018 IEEE Winter Conference on Applications of Computer Vision (WACV)
Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization
May 31, 2019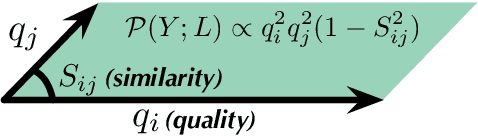
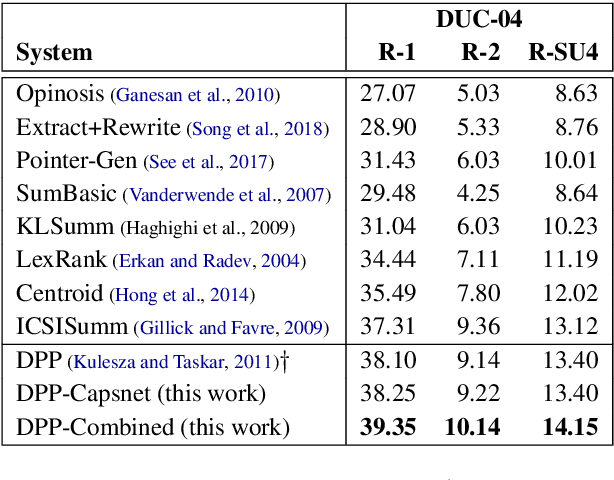
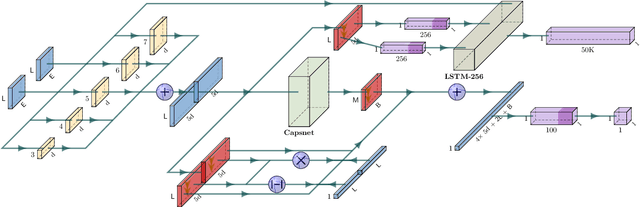
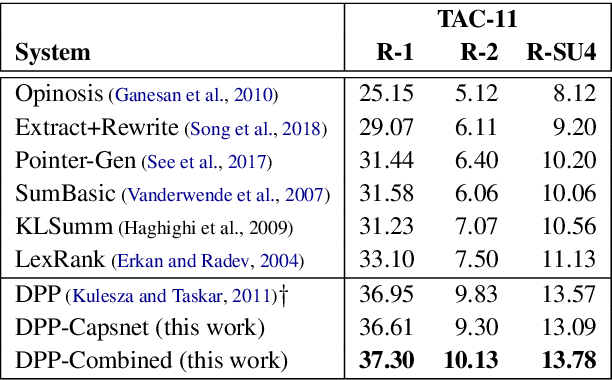
The most important obstacles facing multi-document summarization include excessive redundancy in source descriptions and the looming shortage of training data. These obstacles prevent encoder-decoder models from being used directly, but optimization-based methods such as determinantal point processes (DPPs) are known to handle them well. In this paper we seek to strengthen a DPP-based method for extractive multi-document summarization by presenting a novel similarity measure inspired by capsule networks. The approach measures redundancy between a pair of sentences based on surface form and semantic information. We show that our DPP system with improved similarity measure performs competitively, outperforming strong summarization baselines on benchmark datasets. Our findings are particularly meaningful for summarizing documents created by multiple authors containing redundant yet lexically diverse expressions.
A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
Jan 10, 2019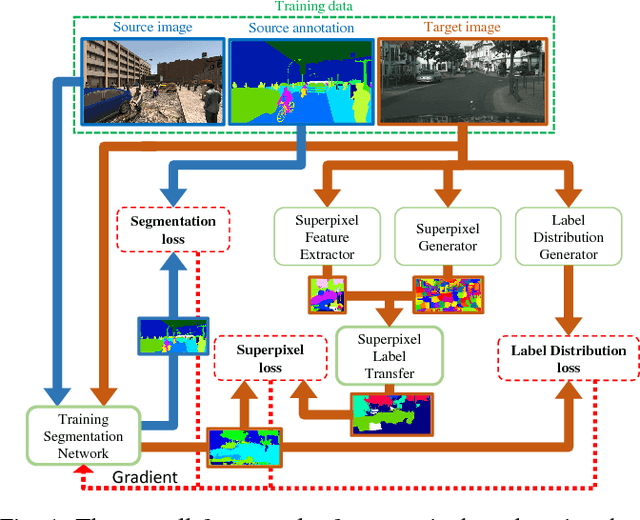


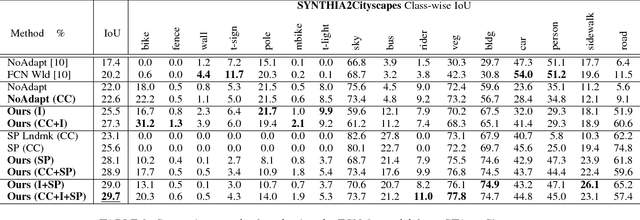
During the last half decade, convolutional neural networks (CNNs) have triumphed over semantic segmentation, which is one of the core tasks in many applications such as autonomous driving and augmented reality. However, to train CNNs requires a considerable amount of data, which is difficult to collect and laborious to annotate. Recent advances in computer graphics make it possible to train CNNs on photo-realistic synthetic imagery with computer-generated annotations. Despite this, the domain mismatch between the real images and the synthetic data hinders the models' performance. Hence, we propose a curriculum-style learning approach to minimizing the domain gap in urban scene semantic segmentation. The curriculum domain adaptation solves easy tasks first to infer necessary properties about the target domain; in particular, the first task is to learn global label distributions over images and local distributions over landmark superpixels. These are easy to estimate because images of urban scenes have strong idiosyncrasies (e.g., the size and spatial relations of buildings, streets, cars, etc.). We then train a segmentation network, while regularizing its predictions in the target domain to follow those inferred properties. In experiments, our method outperforms the baselines on two datasets and two backbone networks. We also report extensive ablation studies about our approach.
Sparse One-Time Grab Sampling of Inliers
Dec 21, 2018Estimating structures in "big data" and clustering them are among the most fundamental problems in computer vision, pattern recognition, data mining, and many other other research fields. Over the past few decades, many studies have been conducted focusing on different aspects of these problems. One of the main approaches that is explored in the literature to tackle the problems of size and dimensionality is sampling subsets of the data in order to estimate the characteristics of the whole population, e.g. estimating the underlying clusters or structures in the data. In this paper, we propose a `one-time-grab' sampling algorithm\cite{jaberi2015swift,jaberi2018sparse}. This method can be used as the front end to any supervised or unsupervised clustering method. Rather than focusing on the strategy of maximizing the probability of sampling inliers, our goal is to minimize the number of samples needed to instantiate all underlying model instances. More specifically, our goal is to answer the following question: {\em `Given a very large population of points with $C$ embedded structures and gross outliers, what is the minimum number of points $r$ to be selected randomly in one grab in order to make sure with probability $P$ that at least $\varepsilon$ points are selected on each structure, where $\varepsilon$ is the number of degrees of freedom of each structure.'}