 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Distribution Detection, Generalization, and Robustness Triangle with Maximum Probability Theorem
Mar 23, 2022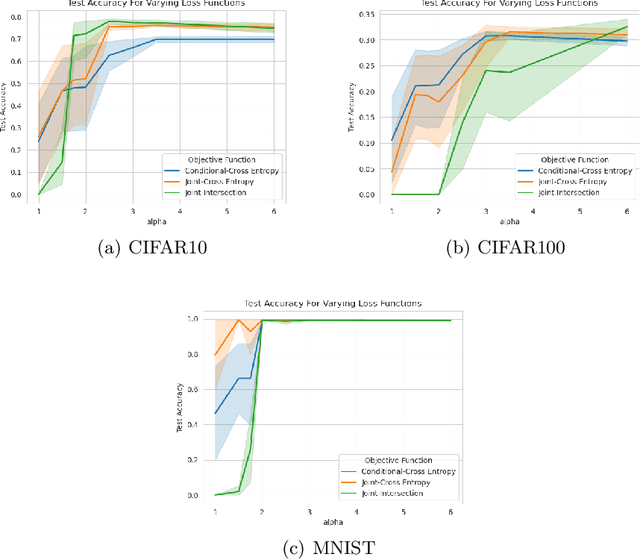
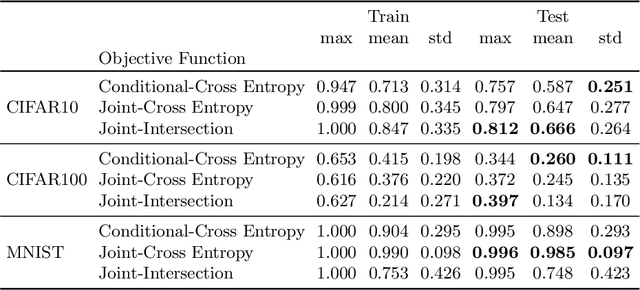

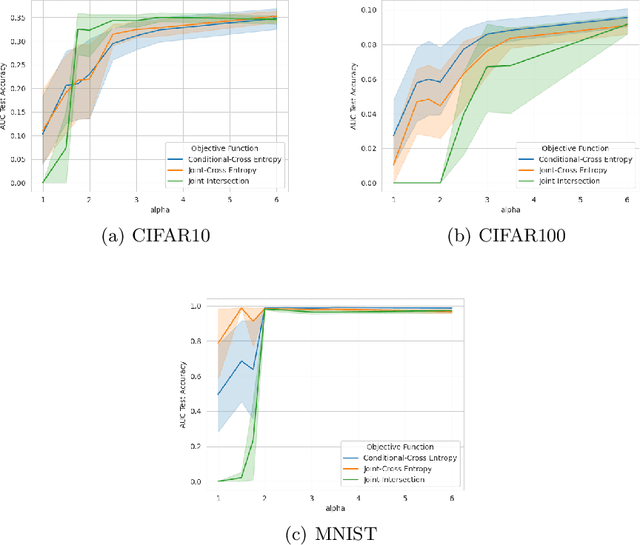
Maximum Probability Framework, powered by Maximum Probability Theorem, is a recent theoretical development, aiming to formally define probabilistic models, guiding development of objective functions, and regularization of probabilistic models. MPT uses the probability distribution that the models assume on random variables to provide an upper bound on probability of the model. We apply MPT to challenging out-of-distribution (OOD) detection problems in computer vision by incorporating MPT as a regularization scheme in training of CNNs and their energy based variants. We demonstrate the effectiveness of the proposed method on 1080 trained models, with varying hyperparameters, and conclude that MPT based regularization strategy both stabilizes and improves the generalization and robustness of base models in addition to improved OOD performance on CIFAR10, CIFAR100 and MNIST datasets.
Feature Sharing and Integration for Cooperative Cognition and Perception with Volumetric Sensors
Dec 04, 2020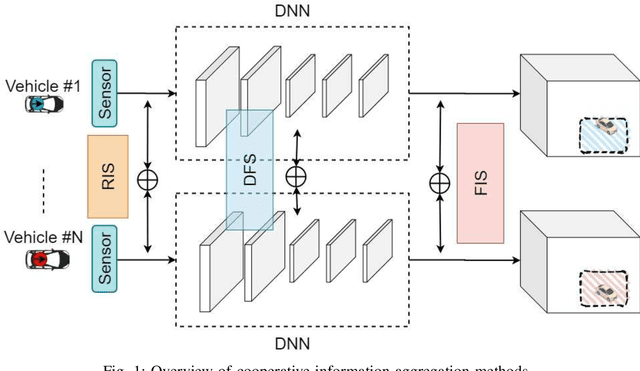
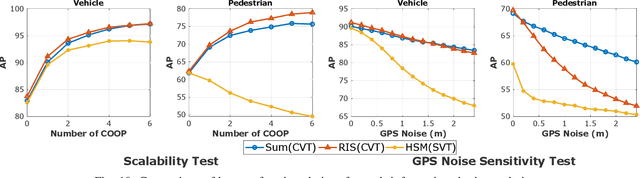
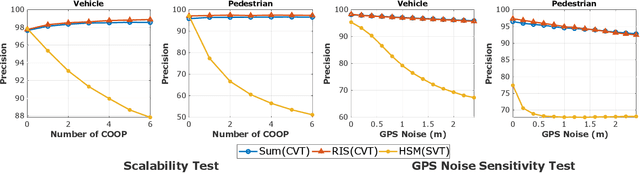
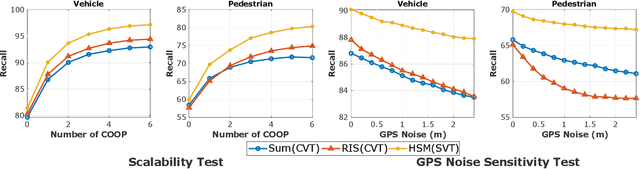
The recent advancement in computational and communication systems has led to the introduction of high-performing neural networks and high-speed wireless vehicular communication networks. As a result, new technologies such as cooperative perception and cognition have emerged, addressing the inherent limitations of sensory devices by providing solutions for the detection of partially occluded targets and expanding the sensing range. However, designing a reliable cooperative cognition or perception system requires addressing the challenges caused by limited network resources and discrepancies between the data shared by different sources. In this paper, we examine the requirements, limitations, and performance of different cooperative perception techniques, and present an in-depth analysis of the notion of Deep Feature Sharing (DFS). We explore different cooperative object detection designs and evaluate their performance in terms of average precision. We use the Volony dataset for our experimental study. The results confirm that the DFS methods are significantly less sensitive to the localization error caused by GPS noise. Furthermore, the results attest that detection gain of DFS methods caused by adding more cooperative participants in the scenes is comparable to raw information sharing technique while DFS enables flexibility in design toward satisfying communication requirements.
Bandwidth-Adaptive Feature Sharing for Cooperative LIDAR Object Detection
Oct 22, 2020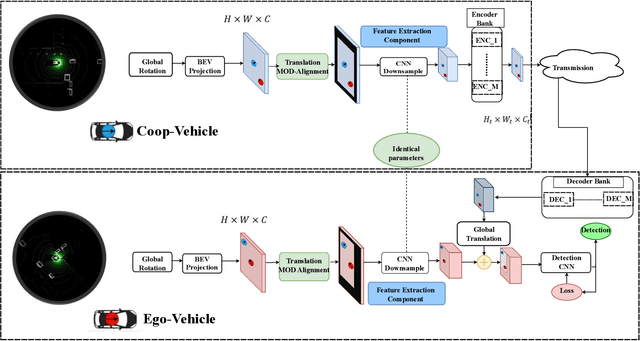
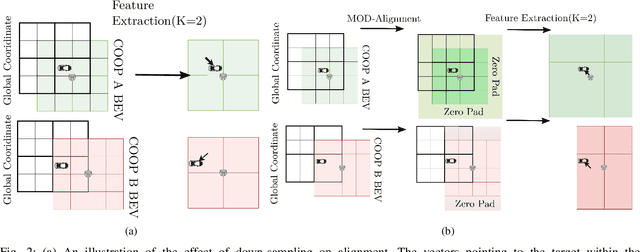
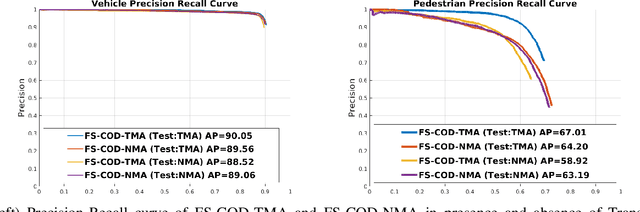
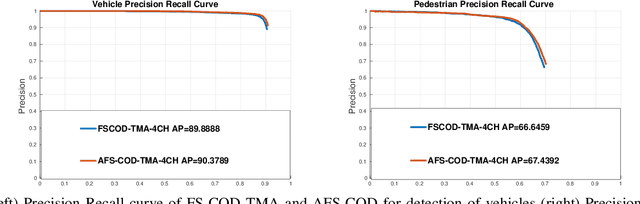
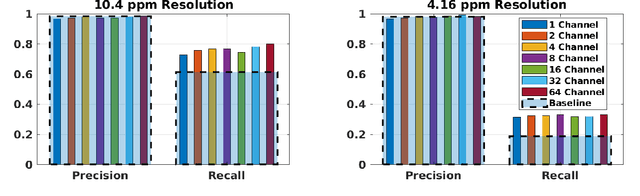
Situational awareness as a necessity in the connected and autonomous vehicles (CAV) domain is the subject of a significant number of researches in recent years. The driver's safety is directly dependent on the robustness, reliability, and scalability of such systems. Cooperative mechanisms have provided a solution to improve situational awareness by utilizing high speed wireless vehicular networks. These mechanisms mitigate problems such as occlusion and sensor range limitation. However, the network capacity is a factor determining the maximum amount of information being shared among cooperative entities. The notion of feature sharing, proposed in our previous work, aims to address these challenges by maintaining a balance between computation and communication load. In this work, we propose a mechanism to add flexibility in adapting to communication channel capacity and a novel decentralized shared data alignment method to further improve cooperative object detection performance. The performance of the proposed framework is verified through experiments on Volony dataset. The results confirm that our proposed framework outperforms our previous cooperative object detection method (FS-COD) in terms of average precision.
Cooperative LIDAR Object Detection via Feature Sharing in Deep Networks
Feb 19, 2020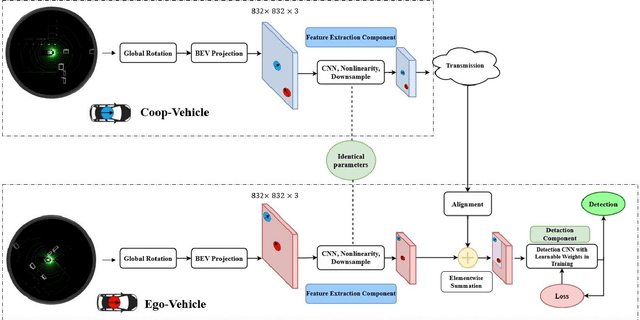

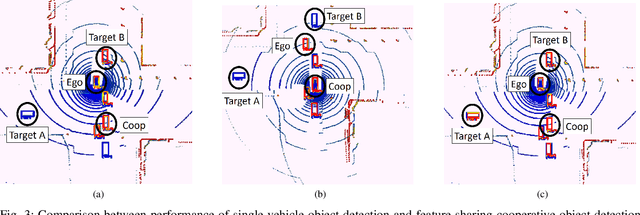
The recent advancements in communication and computational systems has led to significant improvement of situational awareness in connected and autonomous vehicles. Computationally efficient neural networks and high speed wireless vehicular networks have been some of the main contributors to this improvement. However, scalability and reliability issues caused by inherent limitations of sensory and communication systems are still challenging problems. In this paper, we aim to mitigate the effects of these limitations by introducing the concept of feature sharing for cooperative object detection (FS-COD). In our proposed approach, a better understanding of the environment is achieved by sharing partially processed data between cooperative vehicles while maintaining a balance between computation and communication load. This approach is different from current methods of map sharing, or sharing of raw data which are not scalable. The performance of the proposed approach is verified through experiments on Volony dataset. It is shown that the proposed approach has significant performance superiority over the conventional single-vehicle object detection approaches.
Maximum Probability Principle and Black-Box Priors
Nov 03, 2019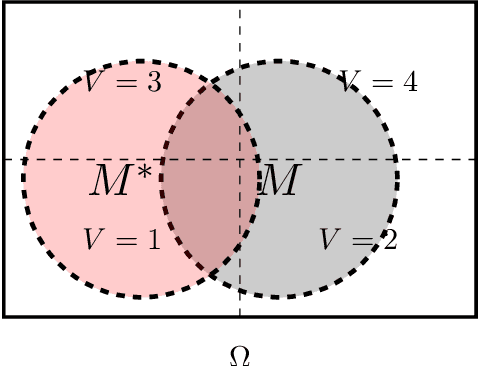
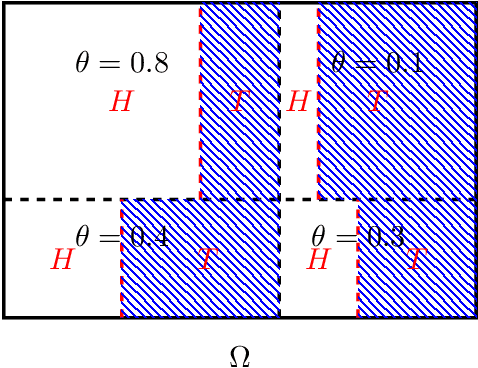
We present an axiomatic way of assigning probabilities to probabilistic models. In particular, we quantify an upper bound for probability of a model or in terms of information theory, a lower bound for amount of information that is assumed in a model. In our setup, maximizing probabilities of models is equivalent to removing assumptions or information stored in the model. Furthermore, we represent the problem of learning from an alternative view where the underlying probability space is considered directly. In this perspective both the true underlying model (Oracle) and the model at hand are events. subsequently, learning is presented in three perspectives: maximizing the likelihood of oracle given model, intersection of model and the oracle and symmetric difference complement of model and the oracle.
Rediscovering Deep Neural Networks in Finite-State Distributions
Sep 26, 2018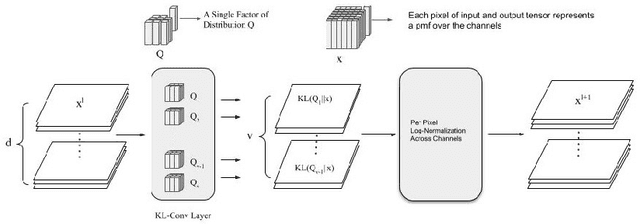
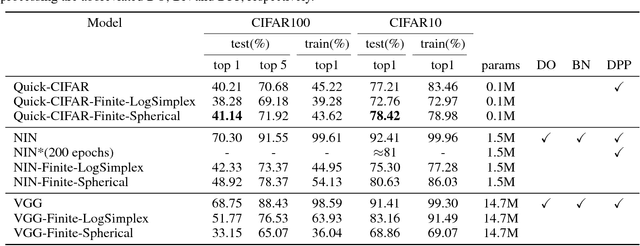
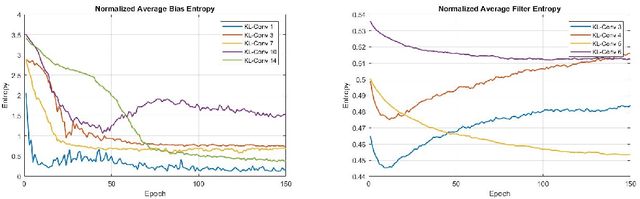
We propose a new way of thinking about deep neural networks, in which the linear and non-linear components of the network are naturally derived and justified in terms of principles in probability theory. In particular, the models constructed in our framework assign probabilities to uncertain realizations, leading to Kullback-Leibler Divergence (KLD) as the linear layer. In our model construction, we also arrive at a structure similar to ReLU activation supported with Bayes' theorem. The non-linearities in our framework are normalization layers with ReLU and Sigmoid as element-wise approximations. Additionally, the pooling function is derived as a marginalization of spatial random variables according to the mechanics of the framework. As such, Max Pooling is an approximation to the aforementioned marginalization process. Since our models are comprised of finite state distributions (FSD) as variables and parameters, exact computation of information-theoretic quantities such as entropy and KLD is possible, thereby providing more objective measures to analyze networks. Unlike existing designs that rely on heuristics, the proposed framework restricts subjective interpretations of CNNs and sheds light on the functionality of neural networks from a completely new perspective.