 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Ahead: Prospection-Guided Retrieval of Memory with Language Models
May 13, 2026Long-horizon personalization requires dialogue assistants to retrieve user-specific facts from extended interaction histories. In practice, many relevant facts often have low semanticsimilarity to the query under dense retrieval. Standard Retrieval-Augmented Generation (RAG) and GraphRAG systems are still largely retrospective: they rely on embedding similarity to the query or on fixed graph traversals, so they often miss facts that matter for the user's needs but lie far from the query in embedding space. Inspired by prospection, the human ability to use imagined futures as cues for recall, we introduce Prospection-Guided Retrieval (PGR), which decouples retrieval from how memories are stored. Given a user query, PGR first expands the goal into a short Tree-of-Thought (ToT) or linear chain of plausible next steps, and uses these steps as retrieval probes rather than relying on the original query alone. The facts retrieved by these probes are then used to personalize the next round of prospection, enabling PGR to uncover additional memories that become relevant only after the simulation is grounded in the user's history. We also introduce MemoryQuest, a challenging multi-session benchmark in which each query is annotated with 3--5 dated reference facts subject to a low query-reference similarity constraint. Across 1,625 queries spanning 185 user profiles from 3 publicly available datasets, PGR-TOT substantially improves retrieval, including nearly 3x recall on MemoryQuest over the strongest baseline. In pairwise LLM-as-judge comparisons against baselines, PGR-generated responses are preferred on 89--98% of queries, with blinded human annotations on held-out subsets showing the same trend. Overall, the results demonstrate that explicit prospection yields large gains in long-horizon retrieval and response quality relative to similarity-only baselines.
Beyond Cooperative Simulators: Generating Realistic User Personas for Robust Evaluation of LLM Agents
May 13, 2026Large Language Model (LLM) agents are increasingly deployed in settings where they interact with a wide variety of people, including users who are unclear, impatient, or reluctant to share information. However, collecting real interaction data at scale remains expensive. The field has turned to LLM-based user simulators as stand-ins, but these simulators inherit the behavior of their underlying models: cooperative and homogeneous. As a result, agents that appear strong in simulation often fail under the unseen, diverse communication patterns of real users. To narrow this gap, we introduce Persona Policies (PPol), a plug-and-play control layer that induces realistic behavioral variation in user simulators while preserving the original task goals. Rather than hand-crafting personas, we cast persona generation as an LLM-driven evolutionary program search that optimizes a Python generator to discover behaviors and translate them into task-preserving roleplay policies. Candidate generators are guided by a multi-objective fitness score combining human-likeness with broad coverage of human behavioral patterns. Once optimized, the generator produces a diverse population of human-like personas for any task in the domain. Across tau^2-bench retail and airline domains, evolved PPol programs yield 33-62% absolute gains in fitness score over the baseline simulator. In a blinded evaluation, annotators rated PPol-conditioned users as human 80.4% of the time, close to real human traces and nearly twice as frequently as baseline simulators. Agents trained with PPol are more robust to challenging, out-of-distribution behaviors, improving task success by +17% relative to training only on existing simulated interactions. This offers a novel approach to strengthen simulator-based evaluation and training without changing tasks or rewards.
Feedback-Aware Monte Carlo Tree Search for Efficient Information Seeking in Goal-Oriented Conversations
Jan 25, 2025



The ability to identify and acquire missing information is a critical component of effective decision making and problem solving. With the rise of conversational artificial intelligence (AI) systems, strategically formulating information-seeking questions becomes crucial and demands efficient methods to guide the search process. We introduce a novel approach to adaptive question-asking through a combination of Large Language Models (LLM) for generating questions that maximize information gain, Monte Carlo Tree Search (MCTS) for constructing and leveraging a decision tree across multiple samples, and a hierarchical feedback mechanism to learn from past interactions. We present two key innovations: (1) an adaptive MCTS algorithm that balances exploration and exploitation for efficient search over potential questions; and (2) a clustering-based feedback algorithm that leverages prior experience to guide future interactions. Each incoming sample is assigned to a cluster based on its semantic similarity with previously observed samples. Our UCT (Upper Confidence bound for Trees) formulation selects optimal questions by combining expected rewards, a function of information gain, with a cluster-specific bonus that decays with depth, to emphasize the importance of early-stage questions that have proven effective for narrowing the solution space in similar samples. Experiments across three domains, including medical diagnosis and troubleshooting, demonstrate that our method leads to an average of 12% improvement in success rates and a 10x reduction in the average number of LLM calls made per conversation for the search process, in comparison to the state of the art.
Delivery Optimized Discovery in Behavioral User Segmentation under Budget Constrain
Feb 04, 2024



Users' behavioral footprints online enable firms to discover behavior-based user segments (or, segments) and deliver segment specific messages to users. Following the discovery of segments, delivery of messages to users through preferred media channels like Facebook and Google can be challenging, as only a portion of users in a behavior segment find match in a medium, and only a fraction of those matched actually see the message (exposure). Even high quality discovery becomes futile when delivery fails. Many sophisticated algorithms exist for discovering behavioral segments; however, these ignore the delivery component. The problem is compounded because (i) the discovery is performed on the behavior data space in firms' data (e.g., user clicks), while the delivery is predicated on the static data space (e.g., geo, age) as defined by media; and (ii) firms work under budget constraint. We introduce a stochastic optimization based algorithm for delivery optimized discovery of behavioral user segmentation and offer new metrics to address the joint optimization. We leverage optimization under a budget constraint for delivery combined with a learning-based component for discovery. Extensive experiments on a public dataset from Google and a proprietary dataset show the effectiveness of our approach by simultaneously improving delivery metrics, reducing budget spend and achieving strong predictive performance in discovery.
Mining Trends of COVID-19 Vaccine Beliefs on Twitter with Lexical Embeddings
Apr 02, 2021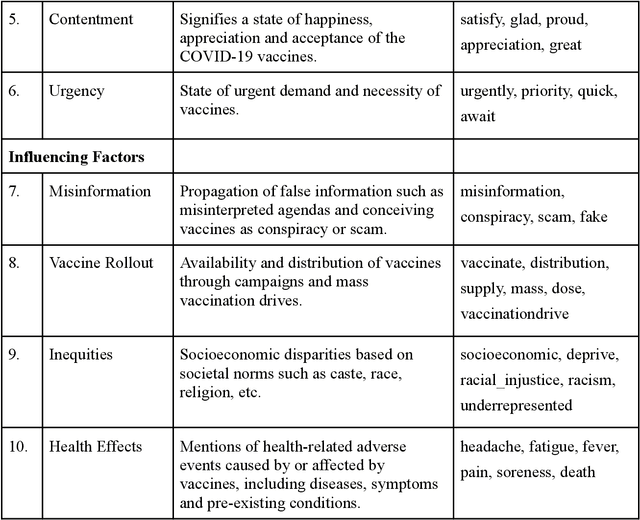

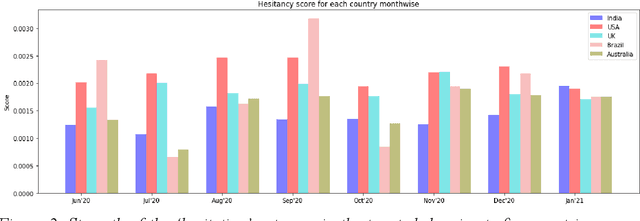

Social media plays a pivotal role in disseminating news across the globe and acts as a platform for people to express their opinions on a variety of topics. COVID-19 vaccination drives across the globe are accompanied by a wide variety of expressed opinions, often colored by emotions. We extracted a corpus of Twitter posts related to COVID-19 vaccination and created two classes of lexical categories - Emotions and Influencing factors. Using unsupervised word embeddings, we tracked the longitudinal change in the latent space of the lexical categories in five countries with strong vaccine roll-out programs, i.e. India, USA, Brazil, UK, and Australia. Nearly 600 thousand vaccine-related tweets from the United States and India were analyzed for an overall understanding of the situation around the world for the time period of 8 months from June 2020 to January 2021. Cosine distance between lexical categories was used to create similarity networks and modules using community detection algorithms. We demonstrate that negative emotions like hesitancy towards vaccines have a high correlation with health-related effects and misinformation. These associations formed a major module with the highest importance in the network formed for January 2021, when millions of vaccines were administered. The relationship between emotions and influencing factors were found to be variable across the countries. By extracting and visualizing these, we propose that such a framework may be helpful in guiding the design of effective vaccine campaigns and can be used by policymakers for modeling vaccine uptake.