 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Ahead: Prospection-Guided Retrieval of Memory with Language Models
May 13, 2026Long-horizon personalization requires dialogue assistants to retrieve user-specific facts from extended interaction histories. In practice, many relevant facts often have low semanticsimilarity to the query under dense retrieval. Standard Retrieval-Augmented Generation (RAG) and GraphRAG systems are still largely retrospective: they rely on embedding similarity to the query or on fixed graph traversals, so they often miss facts that matter for the user's needs but lie far from the query in embedding space. Inspired by prospection, the human ability to use imagined futures as cues for recall, we introduce Prospection-Guided Retrieval (PGR), which decouples retrieval from how memories are stored. Given a user query, PGR first expands the goal into a short Tree-of-Thought (ToT) or linear chain of plausible next steps, and uses these steps as retrieval probes rather than relying on the original query alone. The facts retrieved by these probes are then used to personalize the next round of prospection, enabling PGR to uncover additional memories that become relevant only after the simulation is grounded in the user's history. We also introduce MemoryQuest, a challenging multi-session benchmark in which each query is annotated with 3--5 dated reference facts subject to a low query-reference similarity constraint. Across 1,625 queries spanning 185 user profiles from 3 publicly available datasets, PGR-TOT substantially improves retrieval, including nearly 3x recall on MemoryQuest over the strongest baseline. In pairwise LLM-as-judge comparisons against baselines, PGR-generated responses are preferred on 89--98% of queries, with blinded human annotations on held-out subsets showing the same trend. Overall, the results demonstrate that explicit prospection yields large gains in long-horizon retrieval and response quality relative to similarity-only baselines.
WebXSkill: Skill Learning for Autonomous Web Agents
Apr 14, 2026Autonomous web agents powered by large language models (LLMs) have shown promise in completing complex browser tasks, yet they still struggle with long-horizon workflows. A key bottleneck is the grounding gap in existing skill formulations: textual workflow skills provide natural language guidance but cannot be directly executed, while code-based skills are executable but opaque to the agent, offering no step-level understanding for error recovery or adaptation. We introduce WebXSkill, a framework that bridges this gap with executable skills, each pairing a parameterized action program with step-level natural language guidance, enabling both direct execution and agent-driven adaptation. WebXSkill operates in three stages: skill extraction mines reusable action subsequences from readily available synthetic agent trajectories and abstracts them into parameterized skills, skill organization indexes skills into a URL-based graph for context-aware retrieval, and skill deployment exposes two complementary modes, grounded mode for fully automated multi-step execution and guided mode where skills serve as step-by-step instructions that the agent follows with its native planning. On WebArena and WebVoyager, WebXSkill improves task success rate by up to 9.8 and 12.9 points over the baseline, respectively, demonstrating the effectiveness of executable skills for web agents. The code is publicly available at https://github.com/aiming-lab/WebXSkill.
The Tool Illusion: Rethinking Tool Use in Web Agents
Apr 03, 2026As web agents rapidly evolve, an increasing body of work has moved beyond conventional atomic browser interactions and explored tool use as a higher-level action paradigm. Although prior studies have shown the promise of tools, their conclusions are often drawn from limited experimental scales and sometimes non-comparable settings. As a result, several fundamental questions remain unclear: i) whether tools provide consistent gains for web agents, ii) what practical design principles characterize effective tools, and iii) what side effects tool use may introduce. To establish a stronger empirical foundation for future research, we revisit tool use in web agents through an extensive and carefully controlled study across diverse tool sources, backbone models, tool-use frameworks, and evaluation benchmarks. Our findings both revise some prior conclusions and complement others with broader evidence. We hope this study provides a more reliable empirical basis and inspires future research on tool-use web agents.
ActionEngine: From Reactive to Programmatic GUI Agents via State Machine Memory
Feb 24, 2026Existing Graphical User Interface (GUI) agents operate through step-by-step calls to vision language models--taking a screenshot, reasoning about the next action, executing it, then repeating on the new page--resulting in high costs and latency that scale with the number of reasoning steps, and limited accuracy due to no persistent memory of previously visited pages. We propose ActionEngine, a training-free framework that transitions from reactive execution to programmatic planning through a novel two-agent architecture: a Crawling Agent that constructs an updatable state-machine memory of the GUIs through offline exploration, and an Execution Agent that leverages this memory to synthesize complete, executable Python programs for online task execution. To ensure robustness against evolving interfaces, execution failures trigger a vision-based re-grounding fallback that repairs the failed action and updates the memory. This design drastically improves both efficiency and accuracy: on Reddit tasks from the WebArena benchmark, our agent achieves 95% task success with on average a single LLM call, compared to 66% for the strongest vision-only baseline, while reducing cost by 11.8x and end-to-end latency by 2x. Together, these components yield scalable and reliable GUI interaction by combining global programmatic planning, crawler-validated action templates, and node-level execution with localized validation and repair.
Web Verbs: Typed Abstractions for Reliable Task Composition on the Agentic Web
Feb 19, 2026The Web is evolving from a medium that humans browse to an environment where software agents act on behalf of users. Advances in large language models (LLMs) make natural language a practical interface for goal-directed tasks, yet most current web agents operate on low-level primitives such as clicks and keystrokes. These operations are brittle, inefficient, and difficult to verify. Complementing content-oriented efforts such as NLWeb's semantic layer for retrieval, we argue that the agentic web also requires a semantic layer for web actions. We propose \textbf{Web Verbs}, a web-scale set of typed, semantically documented functions that expose site capabilities through a uniform interface, whether implemented through APIs or robust client-side workflows. These verbs serve as stable and composable units that agents can discover, select, and synthesize into concise programs. This abstraction unifies API-based and browser-based paradigms, enabling LLMs to synthesize reliable and auditable workflows with explicit control and data flow. Verbs can carry preconditions, postconditions, policy tags, and logging support, which improves \textbf{reliability} by providing stable interfaces, \textbf{efficiency} by reducing dozens of steps into a few function calls, and \textbf{verifiability} through typed contracts and checkable traces. We present our vision, a proof-of-concept implementation, and representative case studies that demonstrate concise and robust execution compared to existing agents. Finally, we outline a roadmap for standardization to make verbs deployable and trustworthy at web scale.
Reinforcement World Model Learning for LLM-based Agents
Feb 05, 2026Large language models (LLMs) have achieved strong performance in language-centric tasks. However, in agentic settings, LLMs often struggle to anticipate action consequences and adapt to environment dynamics, highlighting the need for world-modeling capabilities in LLM-based agents. We propose Reinforcement World Model Learning (RWML), a self-supervised method that learns action-conditioned world models for LLM-based agents on textual states using sim-to-real gap rewards. Our method aligns simulated next states produced by the model with realized next states observed from the environment, encouraging consistency between internal world simulations and actual environment dynamics in a pre-trained embedding space. Unlike next-state token prediction, which prioritizes token-level fidelity (i.e., reproducing exact wording) over semantic equivalence and can lead to model collapse, our method provides a more robust training signal and is empirically less susceptible to reward hacking than LLM-as-a-judge. We evaluate our method on ALFWorld and $τ^2$ Bench and observe significant gains over the base model, despite being entirely self-supervised. When combined with task-success rewards, our method outperforms direct task-success reward RL by 6.9 and 5.7 points on ALFWorld and $τ^2$ Bench respectively, while matching the performance of expert-data training.
AgentRx: Diagnosing AI Agent Failures from Execution Trajectories
Feb 02, 2026AI agents often fail in ways that are difficult to localize because executions are probabilistic, long-horizon, multi-agent, and mediated by noisy tool outputs. We address this gap by manually annotating failed agent runs and release a novel benchmark of 115 failed trajectories spanning structured API workflows, incident management, and open-ended web/file tasks. Each trajectory is annotated with a critical failure step and a category from a grounded-theory derived, cross-domain failure taxonomy. To mitigate the human cost of failure attribution, we present AGENTRX, an automated domain-agnostic diagnostic framework that pinpoints the critical failure step in a failed agent trajectory. It synthesizes constraints, evaluates them step-by-step, and produces an auditable validation log of constraint violations with associated evidence; an LLM-based judge uses this log to localize the critical step and category. Our framework improves step localization and failure attribution over existing baselines across three domains.
Dyna-Mind: Learning to Simulate from Experience for Better AI Agents
Oct 10, 2025



Reasoning models have recently shown remarkable progress in domains such as math and coding. However, their expert-level abilities in math and coding contrast sharply with their performance in long-horizon, interactive tasks such as web navigation and computer/phone-use. Inspired by literature on human cognition, we argue that current AI agents need ''vicarious trial and error'' - the capacity to mentally simulate alternative futures before acting - in order to enhance their understanding and performance in complex interactive environments. We introduce Dyna-Mind, a two-stage training framework that explicitly teaches (V)LM agents to integrate such simulation into their reasoning. In stage 1, we introduce Reasoning with Simulations (ReSim), which trains the agent to generate structured reasoning traces from expanded search trees built from real experience gathered through environment interactions. ReSim thus grounds the agent's reasoning in faithful world dynamics and equips it with the ability to anticipate future states in its reasoning. In stage 2, we propose Dyna-GRPO, an online reinforcement learning method to further strengthen the agent's simulation and decision-making ability by using both outcome rewards and intermediate states as feedback from real rollouts. Experiments on two synthetic benchmarks (Sokoban and ALFWorld) and one realistic benchmark (AndroidWorld) demonstrate that (1) ReSim effectively infuses simulation ability into AI agents, and (2) Dyna-GRPO leverages outcome and interaction-level signals to learn better policies for long-horizon, planning-intensive tasks. Together, these results highlight the central role of simulation in enabling AI agents to reason, plan, and act more effectively in the ever more challenging environments.
Building AI Agents for Autonomous Clouds: Challenges and Design Principles
Jul 16, 2024


The rapid growth in the use of Large Language Models (LLMs) and AI Agents as part of software development and deployment is revolutionizing the information technology landscape. While code generation receives significant attention, a higher-impact application lies in using AI agents for operational resilience of cloud services, which currently require significant human effort and domain knowledge. There is a growing interest in AI for IT Operations (AIOps) which aims to automate complex operational tasks, like fault localization and root cause analysis, thereby reducing human intervention and customer impact. However, achieving the vision of autonomous and self-healing clouds though AIOps is hampered by the lack of standardized frameworks for building, evaluating, and improving AIOps agents. This vision paper lays the groundwork for such a framework by first framing the requirements and then discussing design decisions that satisfy them. We also propose AIOpsLab, a prototype implementation leveraging agent-cloud-interface that orchestrates an application, injects real-time faults using chaos engineering, and interfaces with an agent to localize and resolve the faults. We report promising results and lay the groundwork to build a modular and robust framework for building, evaluating, and improving agents for autonomous clouds.
Large-scale Crash Localization using Multi-Task Learning
Sep 29, 2021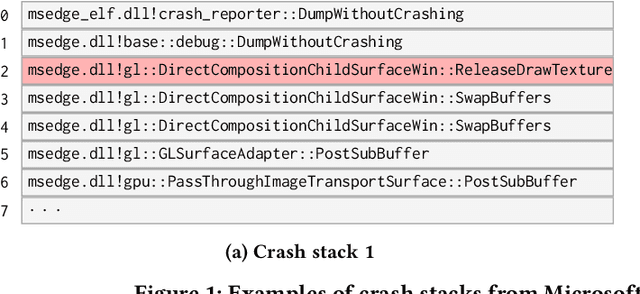
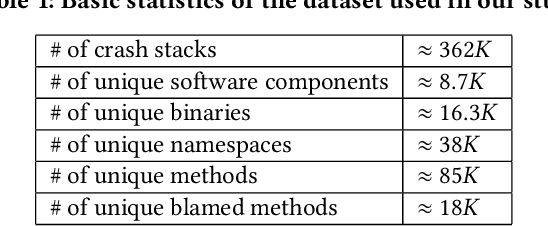
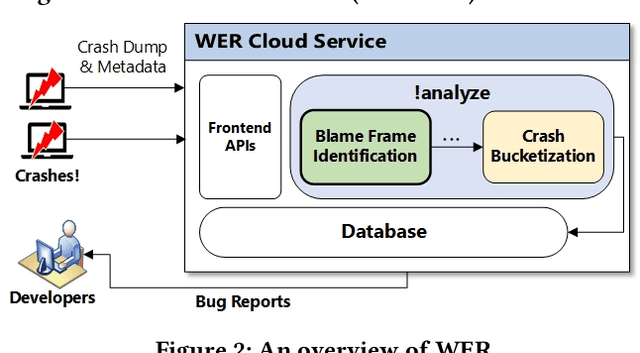
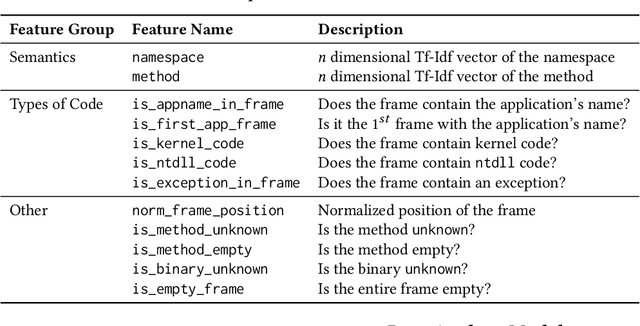
Crash localization, an important step in debugging crashes, is challenging when dealing with an extremely large number of diverse applications and platforms and underlying root causes. Large-scale error reporting systems, e.g., Windows Error Reporting (WER), commonly rely on manually developed rules and heuristics to localize blamed frames causing the crashes. As new applications and features are routinely introduced and existing applications are run under new environments, developing new rules and maintaining existing ones become extremely challenging. We propose a data-driven solution to address the problem. We start with the first large-scale empirical study of 362K crashes and their blamed methods reported to WER by tens of thousands of applications running in the field. The analysis provides valuable insights on where and how the crashes happen and what methods to blame for the crashes. These insights enable us to develop DeepAnalyze, a novel multi-task sequence labeling approach for identifying blamed frames in stack traces. We evaluate our model with over a million real-world crashes from four popular Microsoft applications and show that DeepAnalyze, trained with crashes from one set of applications, not only accurately localizes crashes of the same applications, but also bootstraps crash localization for other applications with zero to very little additional training data.