 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLMs for Predictive Applications in the Intensive Care Units
Dec 23, 2025



With the advent of LLMs, various tasks across the natural language processing domain have been transformed. However, their application in predictive tasks remains less researched. This study compares large language models, including GatorTron-Base (trained on clinical data), Llama 8B, and Mistral 7B, against models like BioBERT, DocBERT, BioClinicalBERT, Word2Vec, and Doc2Vec, setting benchmarks for predicting Shock in critically ill patients. Timely prediction of shock can enable early interventions, thus improving patient outcomes. Text data from 17,294 ICU stays of patients in the MIMIC III database were scored for length of stay > 24 hours and shock index (SI) > 0.7 to yield 355 and 87 patients with normal and abnormal SI-index, respectively. Both focal and cross-entropy losses were used during finetuning to address class imbalances. Our findings indicate that while GatorTron Base achieved the highest weighted recall of 80.5%, the overall performance metrics were comparable between SLMs and LLMs. This suggests that LLMs are not inherently superior to SLMs in predicting future clinical events despite their strong performance on text-based tasks. To achieve meaningful clinical outcomes, future efforts in training LLMs should prioritize developing models capable of predicting clinical trajectories rather than focusing on simpler tasks such as named entity recognition or phenotyping.
Characterizing the Emotion Carriers of COVID-19 Misinformation and Their Impact on Vaccination Outcomes in India and the United States
Jun 24, 2023



The COVID-19 Infodemic had an unprecedented impact on health behaviors and outcomes at a global scale. While many studies have focused on a qualitative and quantitative understanding of misinformation, including sentiment analysis, there is a gap in understanding the emotion-carriers of misinformation and their differences across geographies. In this study, we characterized emotion carriers and their impact on vaccination rates in India and the United States. A manually labelled dataset was created from 2.3 million tweets and collated with three publicly available datasets (CoAID, AntiVax, CMU) to train deep learning models for misinformation classification. Misinformation labelled tweets were further analyzed for behavioral aspects by leveraging Plutchik Transformers to determine the emotion for each tweet. Time series analysis was conducted to study the impact of misinformation on spatial and temporal characteristics. Further, categorical classification was performed using transformer models to assign categories for the misinformation tweets. Word2Vec+BiLSTM was the best model for misinformation classification, with an F1-score of 0.92. The US had the highest proportion of misinformation tweets (58.02%), followed by the UK (10.38%) and India (7.33%). Disgust, anticipation, and anger were associated with an increased prevalence of misinformation tweets. Disgust was the predominant emotion associated with misinformation tweets in the US, while anticipation was the predominant emotion in India. For India, the misinformation rate exhibited a lead relationship with vaccination, while in the US it lagged behind vaccination. Our study deciphered that emotions acted as differential carriers of misinformation across geography and time. These carriers can be monitored to develop strategic interventions for countering misinformation, leading to improved public health.
Variance of Twitter Embeddings and Temporal Trends of COVID-19 cases
Sep 30, 2021

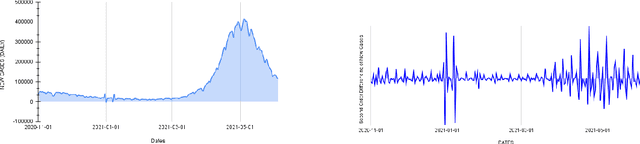

The severity of the coronavirus pandemic necessitates the need of effective administrative decisions. Over 4 lakh people in India succumbed to COVID-19, with over 3 crore confirmed cases, and still counting. The threat of a plausible third wave continues to haunt millions. In this ever changing dynamic of the virus, predictive modeling methods can serve as an integral tool. The pandemic has further triggered an unprecedented usage of social media. This paper aims to propose a method for harnessing social media, specifically Twitter, to predict the upcoming scenarios related to COVID-19 cases. In this study, we seek to understand how the surges in COVID-19 related tweets can indicate rise in the cases. This prospective analysis can be utilised to aid administrators about timely resource allocation to lessen the severity of the damage. Using word embeddings to capture the semantic meaning of tweets, we identify Significant Dimensions (SDs).Our methodology predicts the rise in cases with a lead time of 15 days and 30 days with R2 scores of 0.80 and 0.62 respectively. Finally, we explain the thematic utility of the SDs.
WiseR: An end-to-end structure learning and deployment framework for causal graphical models
Aug 19, 2021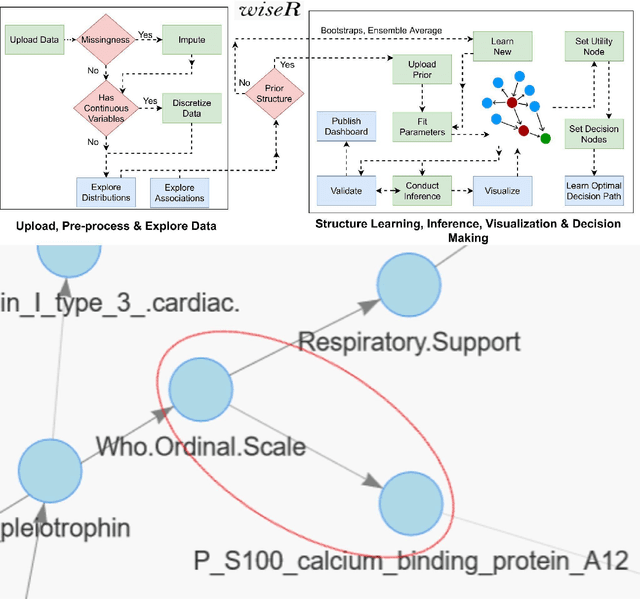
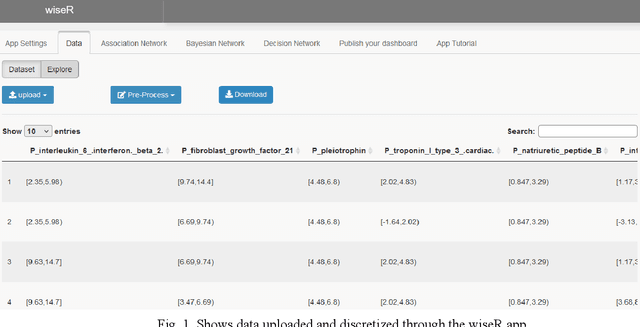
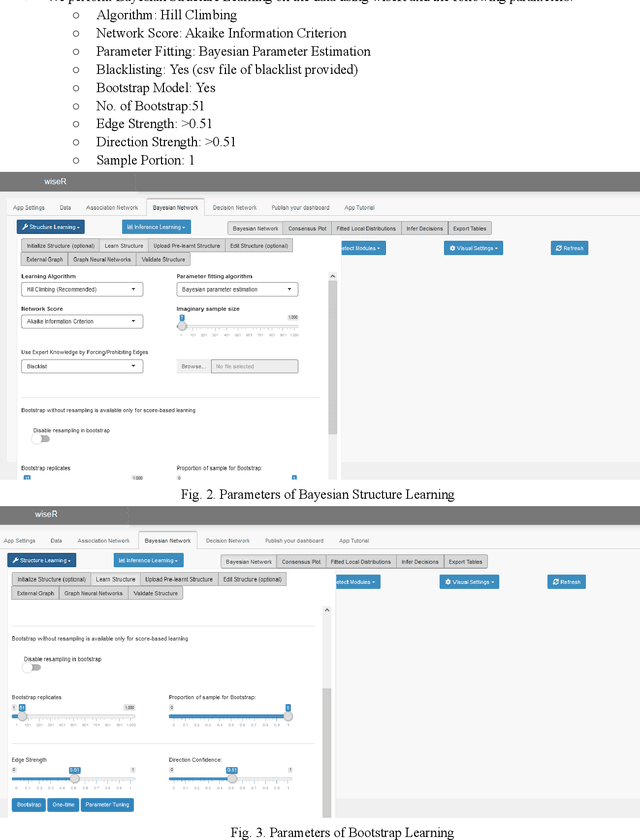
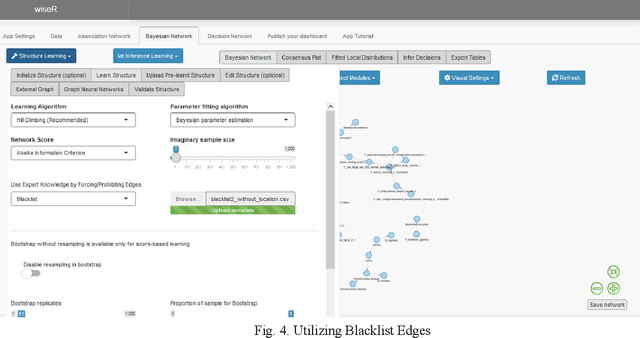
Structure learning offers an expressive, versatile and explainable approach to causal and mechanistic modeling of complex biological data. We present wiseR, an open source application for learning, evaluating and deploying robust causal graphical models using graph neural networks and Bayesian networks. We demonstrate the utility of this application through application on for biomarker discovery in a COVID-19 clinical dataset.
Statistical Learning to Operationalize a Domain Agnostic Data Quality Scoring
Aug 16, 2021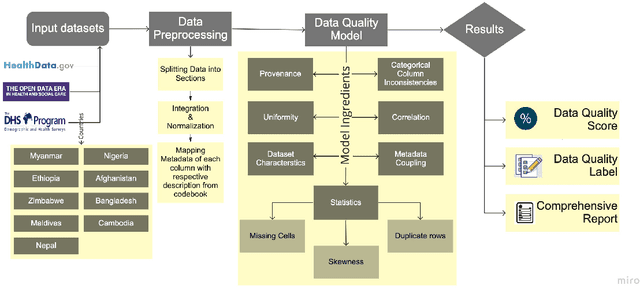

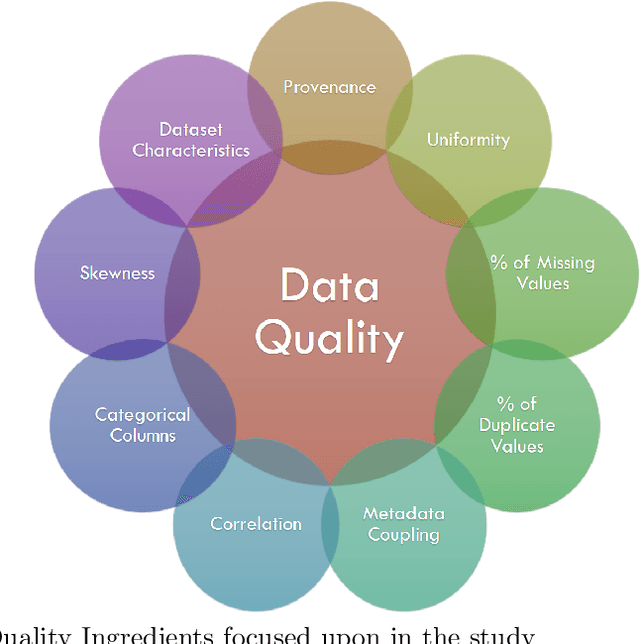
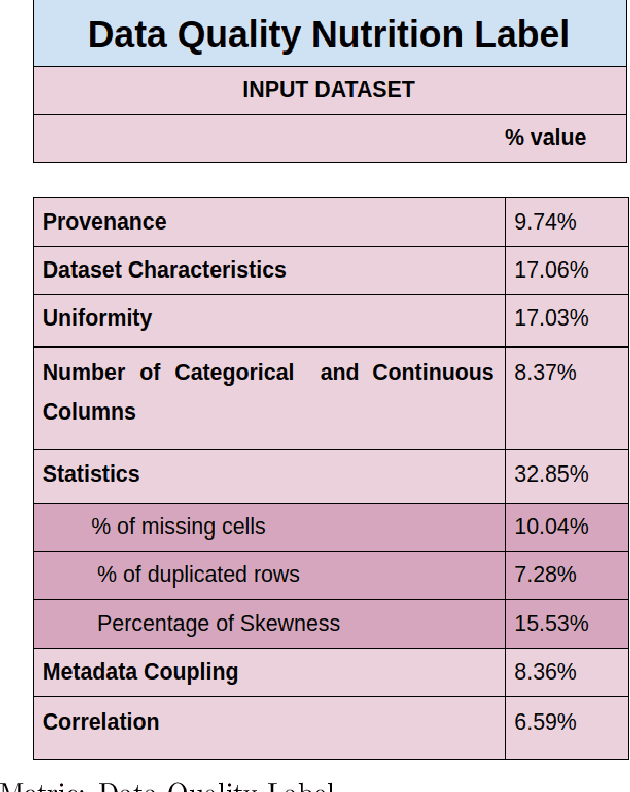
Data is expanding at an unimaginable rate, and with this development comes the responsibility of the quality of data. Data Quality refers to the relevance of the information present and helps in various operations like decision making and planning in a particular organization. Mostly data quality is measured on an ad-hoc basis, and hence none of the developed concepts provide any practical application. The current empirical study was undertaken to formulate a concrete automated data quality platform to assess the quality of incoming dataset and generate a quality label, score and comprehensive report. We utilize various datasets from healthdata.gov, opendata.nhs and Demographics and Health Surveys (DHS) Program to observe the variations in the quality score and formulate a label using Principal Component Analysis(PCA). The results of the current empirical study revealed a metric that encompasses nine quality ingredients, namely provenance, dataset characteristics, uniformity, metadata coupling, percentage of missing cells and duplicate rows, skewness of data, the ratio of inconsistencies of categorical columns, and correlation between these attributes. The study also provides an illustrative case study and validation of the metric following Mutation Testing approaches. This research study provides an automated platform which takes an incoming dataset and metadata to provide the DQ score, report and label. The results of this study would be useful to data scientists as the value of this quality label would instill confidence before deploying the data for his/her respective practical application.
The State of Infodemic on Twitter
May 17, 2021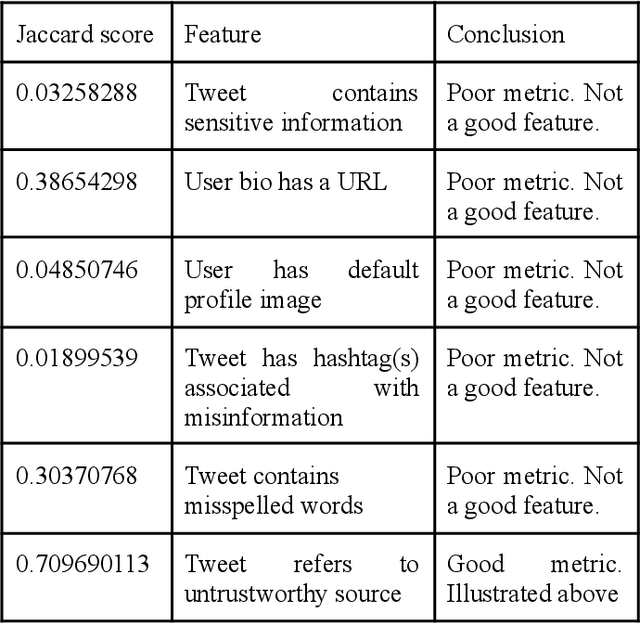
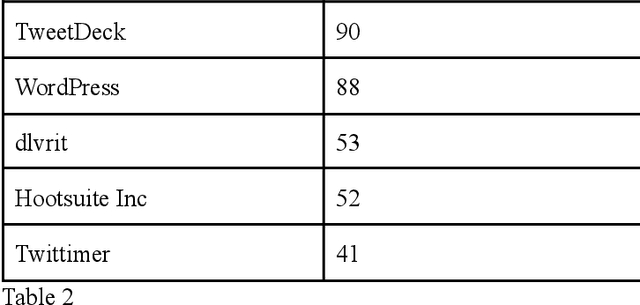
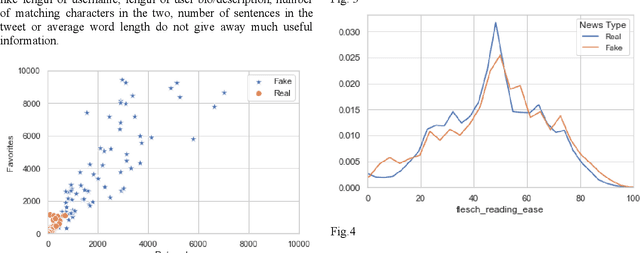
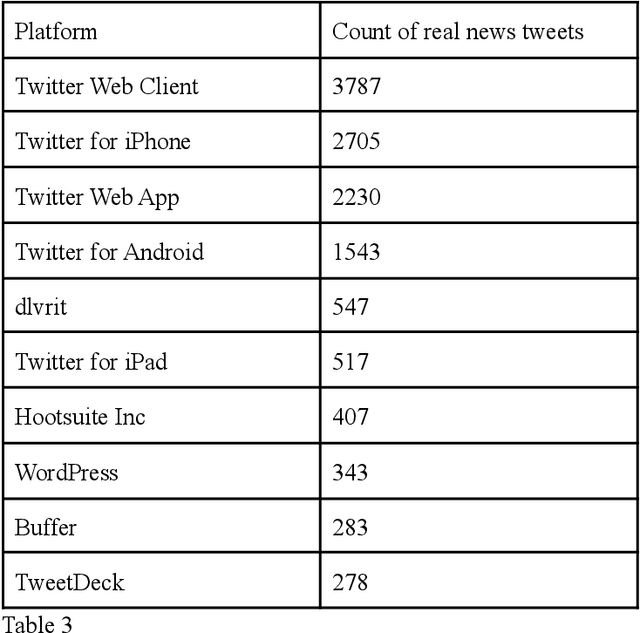
Following the wave of misinterpreted, manipulated and malicious information growing on the Internet, the misinformation surrounding COVID-19 has become a paramount issue. In the context of the current COVID-19 pandemic, social media posts and platforms are at risk of rumors and misinformation in the face of the serious uncertainty surrounding the virus itself. At the same time, the uncertainty and new nature of COVID-19 means that other unconfirmed information that may appear "rumored" may be an important indicator of the behavior and impact of this new virus. Twitter, in particular, has taken a center stage in this storm where Covid-19 has been a much talked about subject. We have presented an exploratory analysis of the tweets and the users who are involved in spreading misinformation and then delved into machine learning models and natural language processing techniques to identify if a tweet contains misinformation.
Mining Trends of COVID-19 Vaccine Beliefs on Twitter with Lexical Embeddings
Apr 02, 2021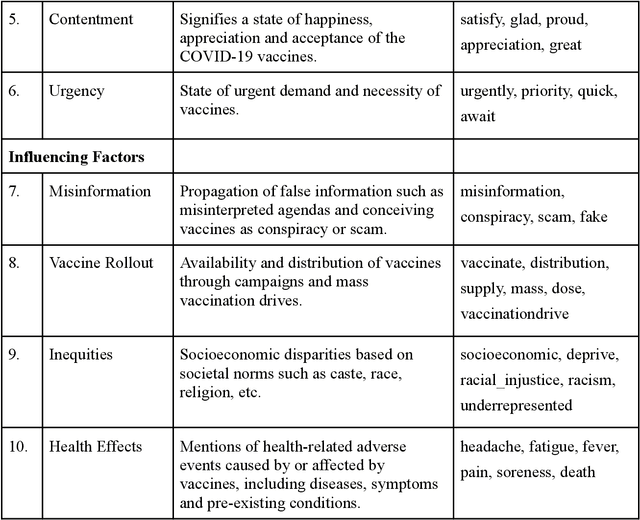


Social media plays a pivotal role in disseminating news across the globe and acts as a platform for people to express their opinions on a variety of topics. COVID-19 vaccination drives across the globe are accompanied by a wide variety of expressed opinions, often colored by emotions. We extracted a corpus of Twitter posts related to COVID-19 vaccination and created two classes of lexical categories - Emotions and Influencing factors. Using unsupervised word embeddings, we tracked the longitudinal change in the latent space of the lexical categories in five countries with strong vaccine roll-out programs, i.e. India, USA, Brazil, UK, and Australia. Nearly 600 thousand vaccine-related tweets from the United States and India were analyzed for an overall understanding of the situation around the world for the time period of 8 months from June 2020 to January 2021. Cosine distance between lexical categories was used to create similarity networks and modules using community detection algorithms. We demonstrate that negative emotions like hesitancy towards vaccines have a high correlation with health-related effects and misinformation. These associations formed a major module with the highest importance in the network formed for January 2021, when millions of vaccines were administered. The relationship between emotions and influencing factors were found to be variable across the countries. By extracting and visualizing these, we propose that such a framework may be helpful in guiding the design of effective vaccine campaigns and can be used by policymakers for modeling vaccine uptake.
Learning Explainable Interventions to Mitigate HIV Transmission in Sex Workers Across Five States in India
Nov 30, 2020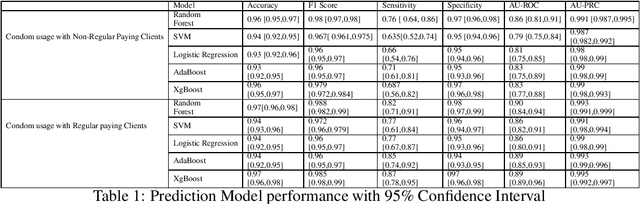
Female sex workers(FSWs) are one of the most vulnerable and stigmatized groups in society. As a result, they often suffer from a lack of quality access to care. Grassroot organizations engaged in improving health services are often faced with the challenge of improving the effectiveness of interventions due to complex influences. This work combines structure learning, discriminative modeling, and grass-root level expertise of designing interventions across five different Indian states to discover the influence of non-obvious factors for improving safe-sex practices in FSWs. A bootstrapped, ensemble-averaged Bayesian Network structure was learned to quantify the factors that could maximize condom usage as revealed from the model. A discriminative model was then constructed using XgBoost and random forest in order to predict condom use behavior The best model achieved 83% sensitivity, 99% specificity, and 99% area under the precision-recall curve for the prediction. Both generative and discriminative modeling approaches revealed that financial literacy training was the primary influence and predictor of condom use in FSWs. These insights have led to a currently ongoing field trial for assessing the real-world utility of this approach. Our work highlights the potential of explainable models for transparent discovery and prioritization of anti-HIV interventions in female sex workers in a resource-limited setting.
Masked COVID-19 Trends from Social Media
Oct 30, 2020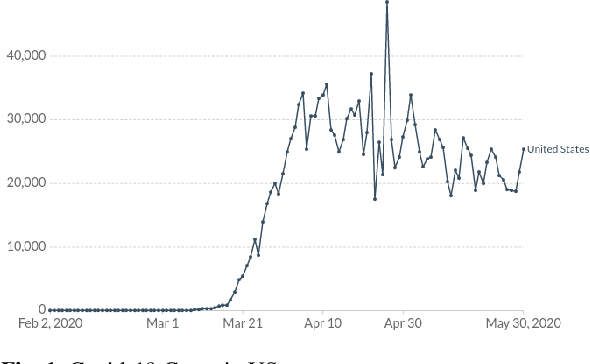

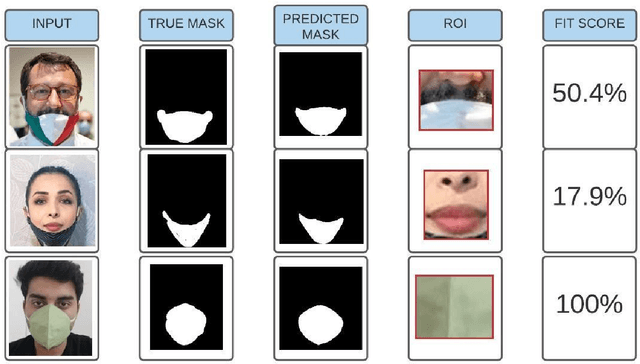
COVID-19 has affected the entire world. One useful protection method for people against COVID-19 is to wear masks in public areas. Across the globe, many public service providers have mandated correctly wearing masks to use their services. This paper proposes two new datasets VAriety MAsks - Classification VAMA-C) and VAriety MAsks - Segmentation (VAMA-S), for mask detection and mask fit analysis tasks, respectively. We propose a framework for classifying masked and unmasked faces and a segmentation based model to calculate the mask-fit score. Both the models trained in this study achieved an accuracy of 98%. Using the two trained deep learning models, 2.04 million social media images for six major US cities were analyzed. By comparing the regulations, an increase in masks worn in images as the COVID-19 cases rose in these cities was observed, particularly when their respective states imposed strict regulations. Furthermore, mask compliance in the Black Lives Matter protest was analyzed, eliciting that 40% of the people in group photos wore masks, and 45% of them wore the masks with a fit score of greater than 80%.
A Cross-lingual Natural Language Processing Framework for Infodemic Management
Oct 30, 2020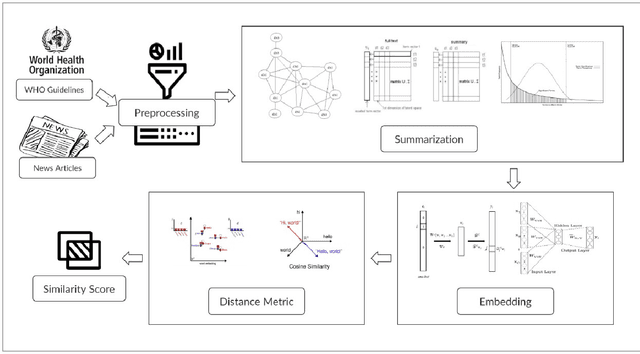

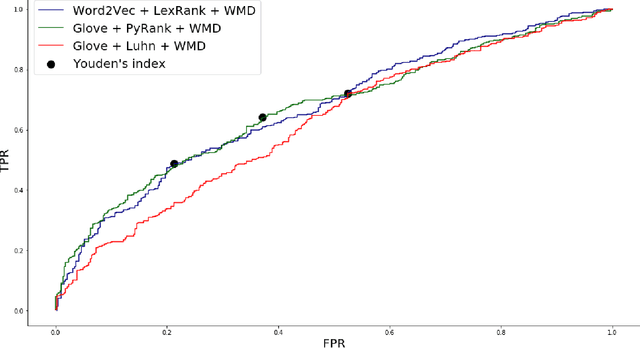
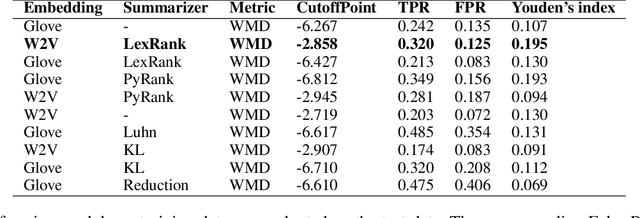
The COVID-19 pandemic has put immense pressure on health systems which are further strained due to the misinformation surrounding it. Under such a situation, providing the right information at the right time is crucial. There is a growing demand for the management of information spread using Artificial Intelligence. Hence, we have exploited the potential of Natural Language Processing for identifying relevant information that needs to be disseminated amongst the masses. In this work, we present a novel Cross-lingual Natural Language Processing framework to provide relevant information by matching daily news with trusted guidelines from the World Health Organization. The proposed pipeline deploys various techniques of NLP such as summarizers, word embeddings, and similarity metrics to provide users with news articles along with a corresponding healthcare guideline. A total of 36 models were evaluated and a combination of LexRank based summarizer on Word2Vec embedding with Word Mover distance metric outperformed all other models. This novel open-source approach can be used as a template for proactive dissemination of relevant healthcare information in the midst of misinformation spread associated with epidemics.