 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation
Jan 29, 2026Manipulating dynamic objects remains an open challenge for Vision-Language-Action (VLA) models, which, despite strong generalization in static manipulation, struggle in dynamic scenarios requiring rapid perception, temporal anticipation, and continuous control. We present DynamicVLA, a framework for dynamic object manipulation that integrates temporal reasoning and closed-loop adaptation through three key designs: 1) a compact 0.4B VLA using a convolutional vision encoder for spatially efficient, structurally faithful encoding, enabling fast multimodal inference; 2) Continuous Inference, enabling overlapping reasoning and execution for lower latency and timely adaptation to object motion; and 3) Latent-aware Action Streaming, which bridges the perception-execution gap by enforcing temporally aligned action execution. To fill the missing foundation of dynamic manipulation data, we introduce the Dynamic Object Manipulation (DOM) benchmark, built from scratch with an auto data collection pipeline that efficiently gathers 200K synthetic episodes across 2.8K scenes and 206 objects, and enables fast collection of 2K real-world episodes without teleoperation. Extensive evaluations demonstrate remarkable improvements in response speed, perception, and generalization, positioning DynamicVLA as a unified framework for general dynamic object manipulation across embodiments.
3D Scene Generation: A Survey
May 08, 20253D scene generation seeks to synthesize spatially structured, semantically meaningful, and photorealistic environments for applications such as immersive media, robotics, autonomous driving, and embodied AI. Early methods based on procedural rules offered scalability but limited diversity. Recent advances in deep generative models (e.g., GANs, diffusion models) and 3D representations (e.g., NeRF, 3D Gaussians) have enabled the learning of real-world scene distributions, improving fidelity, diversity, and view consistency. Recent advances like diffusion models bridge 3D scene synthesis and photorealism by reframing generation as image or video synthesis problems. This survey provides a systematic overview of state-of-the-art approaches, organizing them into four paradigms: procedural generation, neural 3D-based generation, image-based generation, and video-based generation. We analyze their technical foundations, trade-offs, and representative results, and review commonly used datasets, evaluation protocols, and downstream applications. We conclude by discussing key challenges in generation capacity, 3D representation, data and annotations, and evaluation, and outline promising directions including higher fidelity, physics-aware and interactive generation, and unified perception-generation models. This review organizes recent advances in 3D scene generation and highlights promising directions at the intersection of generative AI, 3D vision, and embodied intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/hzxie/Awesome-3D-Scene-Generation.
CityDreamer4D: Compositional Generative Model of Unbounded 4D Cities
Jan 15, 2025



3D scene generation has garnered growing attention in recent years and has made significant progress. Generating 4D cities is more challenging than 3D scenes due to the presence of structurally complex, visually diverse objects like buildings and vehicles, and heightened human sensitivity to distortions in urban environments. To tackle these issues, we propose CityDreamer4D, a compositional generative model specifically tailored for generating unbounded 4D cities. Our main insights are 1) 4D city generation should separate dynamic objects (e.g., vehicles) from static scenes (e.g., buildings and roads), and 2) all objects in the 4D scene should be composed of different types of neural fields for buildings, vehicles, and background stuff. Specifically, we propose Traffic Scenario Generator and Unbounded Layout Generator to produce dynamic traffic scenarios and static city layouts using a highly compact BEV representation. Objects in 4D cities are generated by combining stuff-oriented and instance-oriented neural fields for background stuff, buildings, and vehicles. To suit the distinct characteristics of background stuff and instances, the neural fields employ customized generative hash grids and periodic positional embeddings as scene parameterizations. Furthermore, we offer a comprehensive suite of datasets for city generation, including OSM, GoogleEarth, and CityTopia. The OSM dataset provides a variety of real-world city layouts, while the Google Earth and CityTopia datasets deliver large-scale, high-quality city imagery complete with 3D instance annotations. Leveraging its compositional design, CityDreamer4D supports a range of downstream applications, such as instance editing, city stylization, and urban simulation, while delivering state-of-the-art performance in generating realistic 4D cities.
DynamicCity: Large-Scale LiDAR Generation from Dynamic Scenes
Oct 23, 2024



LiDAR scene generation has been developing rapidly recently. However, existing methods primarily focus on generating static and single-frame scenes, overlooking the inherently dynamic nature of real-world driving environments. In this work, we introduce DynamicCity, a novel 4D LiDAR generation framework capable of generating large-scale, high-quality LiDAR scenes that capture the temporal evolution of dynamic environments. DynamicCity mainly consists of two key models. 1) A VAE model for learning HexPlane as the compact 4D representation. Instead of using naive averaging operations, DynamicCity employs a novel Projection Module to effectively compress 4D LiDAR features into six 2D feature maps for HexPlane construction, which significantly enhances HexPlane fitting quality (up to 12.56 mIoU gain). Furthermore, we utilize an Expansion & Squeeze Strategy to reconstruct 3D feature volumes in parallel, which improves both network training efficiency and reconstruction accuracy than naively querying each 3D point (up to 7.05 mIoU gain, 2.06x training speedup, and 70.84% memory reduction). 2) A DiT-based diffusion model for HexPlane generation. To make HexPlane feasible for DiT generation, a Padded Rollout Operation is proposed to reorganize all six feature planes of the HexPlane as a squared 2D feature map. In particular, various conditions could be introduced in the diffusion or sampling process, supporting versatile 4D generation applications, such as trajectory- and command-driven generation, inpainting, and layout-conditioned generation. Extensive experiments on the CarlaSC and Waymo datasets demonstrate that DynamicCity significantly outperforms existing state-of-the-art 4D LiDAR generation methods across multiple metrics. The code will be released to facilitate future research.
CrowdMoGen: Zero-Shot Text-Driven Collective Motion Generation
Jul 08, 2024



Crowd Motion Generation is essential in entertainment industries such as animation and games as well as in strategic fields like urban simulation and planning. This new task requires an intricate integration of control and generation to realistically synthesize crowd dynamics under specific spatial and semantic constraints, whose challenges are yet to be fully explored. On the one hand, existing human motion generation models typically focus on individual behaviors, neglecting the complexities of collective behaviors. On the other hand, recent methods for multi-person motion generation depend heavily on pre-defined scenarios and are limited to a fixed, small number of inter-person interactions, thus hampering their practicality. To overcome these challenges, we introduce CrowdMoGen, a zero-shot text-driven framework that harnesses the power of Large Language Model (LLM) to incorporate the collective intelligence into the motion generation framework as guidance, thereby enabling generalizable planning and generation of crowd motions without paired training data. Our framework consists of two key components: 1) Crowd Scene Planner that learns to coordinate motions and dynamics according to specific scene contexts or introduced perturbations, and 2) Collective Motion Generator that efficiently synthesizes the required collective motions based on the holistic plans. Extensive quantitative and qualitative experiments have validated the effectiveness of our framework, which not only fills a critical gap by providing scalable and generalizable solutions for Crowd Motion Generation task but also achieves high levels of realism and flexibility.
Blur-aware Spatio-temporal Sparse Transformer for Video Deblurring
Jun 11, 2024



Video deblurring relies on leveraging information from other frames in the video sequence to restore the blurred regions in the current frame. Mainstream approaches employ bidirectional feature propagation, spatio-temporal transformers, or a combination of both to extract information from the video sequence. However, limitations in memory and computational resources constraints the temporal window length of the spatio-temporal transformer, preventing the extraction of longer temporal contextual information from the video sequence. Additionally, bidirectional feature propagation is highly sensitive to inaccurate optical flow in blurry frames, leading to error accumulation during the propagation process. To address these issues, we propose \textbf{BSSTNet}, \textbf{B}lur-aware \textbf{S}patio-temporal \textbf{S}parse \textbf{T}ransformer Network. It introduces the blur map, which converts the originally dense attention into a sparse form, enabling a more extensive utilization of information throughout the entire video sequence. Specifically, BSSTNet (1) uses a longer temporal window in the transformer, leveraging information from more distant frames to restore the blurry pixels in the current frame. (2) introduces bidirectional feature propagation guided by blur maps, which reduces error accumulation caused by the blur frame. The experimental results demonstrate the proposed BSSTNet outperforms the state-of-the-art methods on the GoPro and DVD datasets.
GaussianCity: Generative Gaussian Splatting for Unbounded 3D City Generation
Jun 10, 2024



3D city generation with NeRF-based methods shows promising generation results but is computationally inefficient. Recently 3D Gaussian Splatting (3D-GS) has emerged as a highly efficient alternative for object-level 3D generation. However, adapting 3D-GS from finite-scale 3D objects and humans to infinite-scale 3D cities is non-trivial. Unbounded 3D city generation entails significant storage overhead (out-of-memory issues), arising from the need to expand points to billions, often demanding hundreds of Gigabytes of VRAM for a city scene spanning 10km^2. In this paper, we propose GaussianCity, a generative Gaussian Splatting framework dedicated to efficiently synthesizing unbounded 3D cities with a single feed-forward pass. Our key insights are two-fold: 1) Compact 3D Scene Representation: We introduce BEV-Point as a highly compact intermediate representation, ensuring that the growth in VRAM usage for unbounded scenes remains constant, thus enabling unbounded city generation. 2) Spatial-aware Gaussian Attribute Decoder: We present spatial-aware BEV-Point decoder to produce 3D Gaussian attributes, which leverages Point Serializer to integrate the structural and contextual characteristics of BEV points. Extensive experiments demonstrate that GaussianCity achieves state-of-the-art results in both drone-view and street-view 3D city generation. Notably, compared to CityDreamer, GaussianCity exhibits superior performance with a speedup of 60 times (10.72 FPS v.s. 0.18 FPS).
CityDreamer: Compositional Generative Model of Unbounded 3D Cities
Sep 01, 2023



In recent years, extensive research has focused on 3D natural scene generation, but the domain of 3D city generation has not received as much exploration. This is due to the greater challenges posed by 3D city generation, mainly because humans are more sensitive to structural distortions in urban environments. Additionally, generating 3D cities is more complex than 3D natural scenes since buildings, as objects of the same class, exhibit a wider range of appearances compared to the relatively consistent appearance of objects like trees in natural scenes. To address these challenges, we propose CityDreamer, a compositional generative model designed specifically for unbounded 3D cities, which separates the generation of building instances from other background objects, such as roads, green lands, and water areas, into distinct modules. Furthermore, we construct two datasets, OSM and GoogleEarth, containing a vast amount of real-world city imagery to enhance the realism of the generated 3D cities both in their layouts and appearances. Through extensive experiments, CityDreamer has proven its superiority over state-of-the-art methods in generating a wide range of lifelike 3D cities.
Spatio-Temporal Deformable Attention Network for Video Deblurring
Jul 22, 2022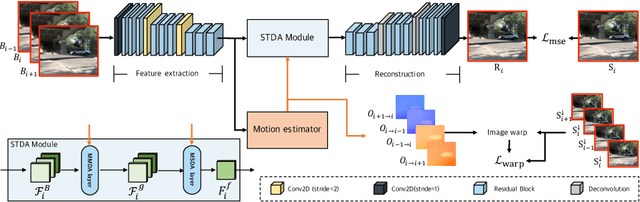

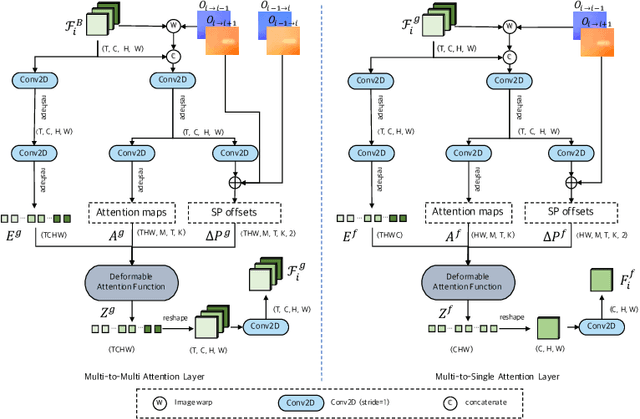

The key success factor of the video deblurring methods is to compensate for the blurry pixels of the mid-frame with the sharp pixels of the adjacent video frames. Therefore, mainstream methods align the adjacent frames based on the estimated optical flows and fuse the alignment frames for restoration. However, these methods sometimes generate unsatisfactory results because they rarely consider the blur levels of pixels, which may introduce blurry pixels from video frames. Actually, not all the pixels in the video frames are sharp and beneficial for deblurring. To address this problem, we propose the spatio-temporal deformable attention network (STDANet) for video delurring, which extracts the information of sharp pixels by considering the pixel-wise blur levels of the video frames. Specifically, STDANet is an encoder-decoder network combined with the motion estimator and spatio-temporal deformable attention (STDA) module, where motion estimator predicts coarse optical flows that are used as base offsets to find the corresponding sharp pixels in STDA module. Experimental results indicate that the proposed STDANet performs favorably against state-of-the-art methods on the GoPro, DVD, and BSD datasets.
Long-Range Feature Propagating for Natural Image Matting
Sep 25, 2021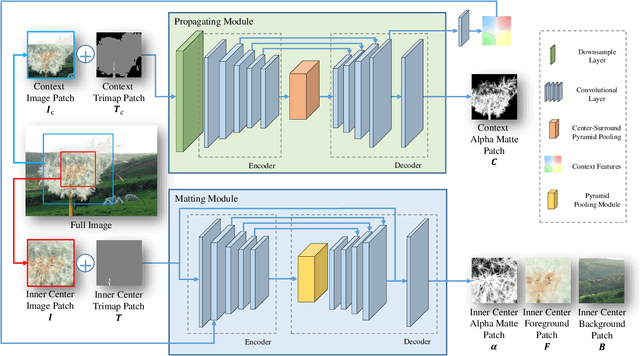
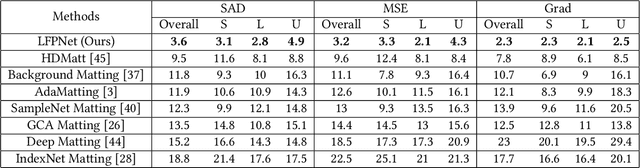
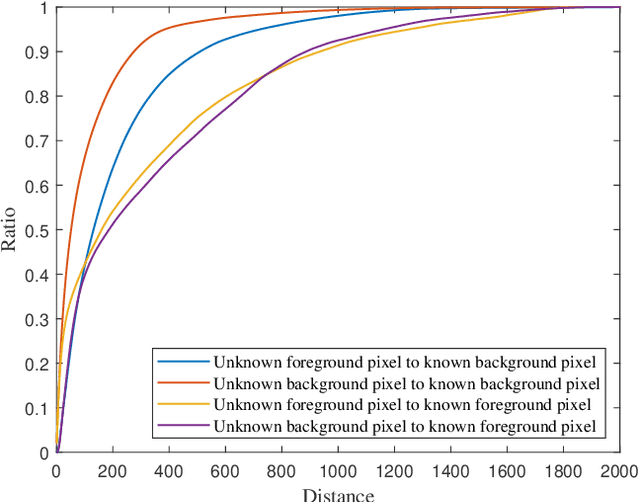
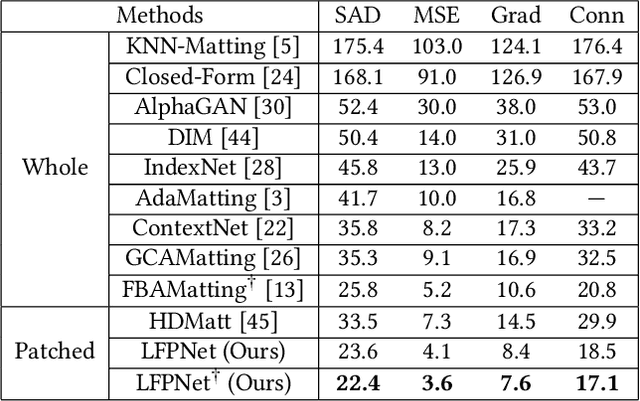
Natural image matting estimates the alpha values of unknown regions in the trimap. Recently, deep learning based methods propagate the alpha values from the known regions to unknown regions according to the similarity between them. However, we find that more than 50\% pixels in the unknown regions cannot be correlated to pixels in known regions due to the limitation of small effective reception fields of common convolutional neural networks, which leads to inaccurate estimation when the pixels in the unknown regions cannot be inferred only with pixels in the reception fields. To solve this problem, we propose Long-Range Feature Propagating Network (LFPNet), which learns the long-range context features outside the reception fields for alpha matte estimation. Specifically, we first design the propagating module which extracts the context features from the downsampled image. Then, we present Center-Surround Pyramid Pooling (CSPP) that explicitly propagates the context features from the surrounding context image patch to the inner center image patch. Finally, we use the matting module which takes the image, trimap and context features to estimate the alpha matte. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art methods on the AlphaMatting and Adobe Image Matting datasets.