 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
Mar 19, 2026Reconstructing articulated 3D objects from a single image requires jointly inferring object geometry, part structure, and motion parameters from limited visual evidence. A key difficulty lies in the entanglement between motion cues and object structure, which makes direct articulation regression unstable. Existing methods address this challenge through multi-view supervision, retrieval-based assembly, or auxiliary video generation, often sacrificing scalability or efficiency. We present MonoArt, a unified framework grounded in progressive structural reasoning. Rather than predicting articulation directly from image features, MonoArt progressively transforms visual observations into canonical geometry, structured part representations, and motion-aware embeddings within a single architecture. This structured reasoning process enables stable and interpretable articulation inference without external motion templates or multi-stage pipelines. Extensive experiments on PartNet-Mobility demonstrate that OM achieves state-of-the-art performance in both reconstruction accuracy and inference speed. The framework further generalizes to robotic manipulation and articulated scene reconstruction.
DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation
Jan 29, 2026Manipulating dynamic objects remains an open challenge for Vision-Language-Action (VLA) models, which, despite strong generalization in static manipulation, struggle in dynamic scenarios requiring rapid perception, temporal anticipation, and continuous control. We present DynamicVLA, a framework for dynamic object manipulation that integrates temporal reasoning and closed-loop adaptation through three key designs: 1) a compact 0.4B VLA using a convolutional vision encoder for spatially efficient, structurally faithful encoding, enabling fast multimodal inference; 2) Continuous Inference, enabling overlapping reasoning and execution for lower latency and timely adaptation to object motion; and 3) Latent-aware Action Streaming, which bridges the perception-execution gap by enforcing temporally aligned action execution. To fill the missing foundation of dynamic manipulation data, we introduce the Dynamic Object Manipulation (DOM) benchmark, built from scratch with an auto data collection pipeline that efficiently gathers 200K synthetic episodes across 2.8K scenes and 206 objects, and enables fast collection of 2K real-world episodes without teleoperation. Extensive evaluations demonstrate remarkable improvements in response speed, perception, and generalization, positioning DynamicVLA as a unified framework for general dynamic object manipulation across embodiments.
3D Scene Generation: A Survey
May 08, 2025

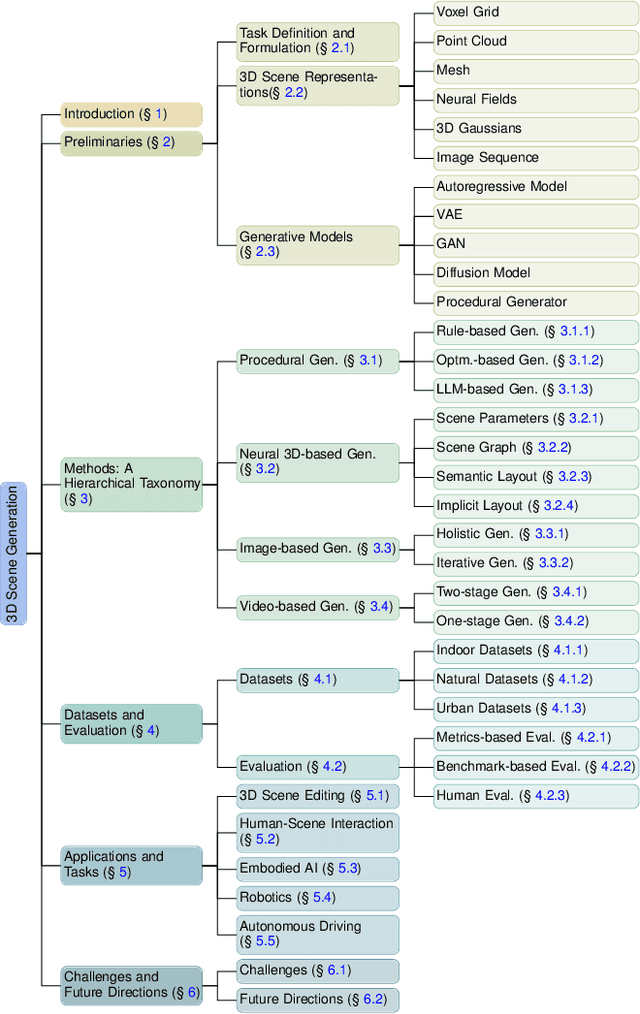
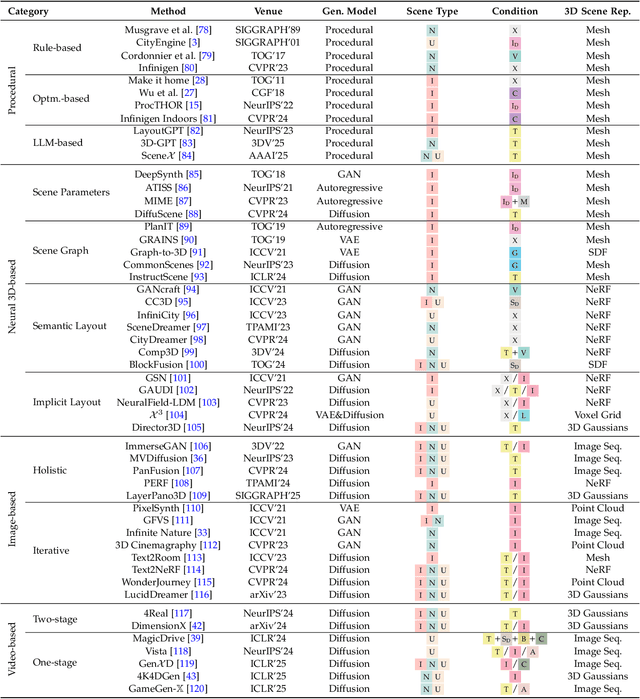
3D scene generation seeks to synthesize spatially structured, semantically meaningful, and photorealistic environments for applications such as immersive media, robotics, autonomous driving, and embodied AI. Early methods based on procedural rules offered scalability but limited diversity. Recent advances in deep generative models (e.g., GANs, diffusion models) and 3D representations (e.g., NeRF, 3D Gaussians) have enabled the learning of real-world scene distributions, improving fidelity, diversity, and view consistency. Recent advances like diffusion models bridge 3D scene synthesis and photorealism by reframing generation as image or video synthesis problems. This survey provides a systematic overview of state-of-the-art approaches, organizing them into four paradigms: procedural generation, neural 3D-based generation, image-based generation, and video-based generation. We analyze their technical foundations, trade-offs, and representative results, and review commonly used datasets, evaluation protocols, and downstream applications. We conclude by discussing key challenges in generation capacity, 3D representation, data and annotations, and evaluation, and outline promising directions including higher fidelity, physics-aware and interactive generation, and unified perception-generation models. This review organizes recent advances in 3D scene generation and highlights promising directions at the intersection of generative AI, 3D vision, and embodied intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/hzxie/Awesome-3D-Scene-Generation.