 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurging the Gray Zone: Latent-Geometric Denoising for Precise Knowledge Boundary Awareness
Apr 15, 2026Large language models (LLMs) often exhibit hallucinations due to their inability to accurately perceive their own knowledge boundaries. Existing abstention fine-tuning methods typically partition datasets directly based on response accuracy, causing models to suffer from severe label noise near the decision boundaries and consequently exhibit high rates of abstentions or hallucinations. This paper adopts a latent space representation perspective, revealing a "gray zone" near the decision hyperplane where internal belief ambiguity constitutes the core performance bottleneck. Based on this insight, we propose the **GeoDe** (**Geo**metric **De**noising) framework for abstention fine-tuning. This method constructs a truth hyperplane using linear probes and performs "geometric denoising" by employing geometric distance as a confidence signal for abstention decisions. This approach filters out ambiguous boundary samples while retaining high-fidelity signals for fine-tuning. Experiments across multiple models (Llama3, Qwen3) and benchmark datasets (TriviaQA, NQ, SciQ, SimpleQA) demonstrate that GeoDe significantly enhances model truthfulness and demonstrates strong generalization in out-of-distribution (OOD) scenarios. Code is available at https://github.com/Notbesidemoon/GeoDe.
Fast and Accurate Probing of In-Training LLMs' Downstream Performances
Apr 01, 2026The paradigm of scaling Large Language Models (LLMs) in both parameter size and test time has pushed the boundaries of AI capabilities, but at the cost of making the traditional generative evaluation paradigm prohibitively expensive, therefore making the latency of LLM's in-training downstream performance evaluation unbearable. However, simple metrics like training loss (perplexity) are not always correlated with downstream performance, as sometimes their trends diverge from the actual task outcomes. This dilemma calls for a method that is computationally efficient and sufficiently accurate in measuring model capabilities. To address this challenge, we introduce a new in-training evaluation paradigm that uses a lightweight probe for monitoring downstream performance. The probes take the internal representations of LLM checkpoints (during training) as input and directly predict the checkpoint's performance on downstream tasks measured by success probability (i.e., pass@1). We design several probe architectures, validating their effectiveness using the OLMo3-7B's checkpoints across a diverse set of downstream tasks. The probes can accurately predict a checkpoint's performance (with avg. AUROC$>$0.75), have decent generalizability across checkpoints (earlier predicts later), and reduce the computation latency from $\sim$1 hr (using conventional generative evaluation method) to $\sim$3 min. In sum, this work presents a practical and scalable in-training downstream evaluation paradigm, enabling a more agile, informed, and efficient LLM development process.
Detecting Subtle Differences between Human and Model Languages Using Spectrum of Relative Likelihood
Jun 28, 2024



Human and model-generated texts can be distinguished by examining the magnitude of likelihood in language. However, it is becoming increasingly difficult as language model's capabilities of generating human-like texts keep evolving. This study provides a new perspective by using the relative likelihood values instead of absolute ones, and extracting useful features from the spectrum-view of likelihood for the human-model text detection task. We propose a detection procedure with two classification methods, supervised and heuristic-based, respectively, which results in competitive performances with previous zero-shot detection methods and a new state-of-the-art on short-text detection. Our method can also reveal subtle differences between human and model languages, which find theoretical roots in psycholinguistics studies. Our code is available at https://github.com/CLCS-SUSTech/FourierGPT
TLAG: An Informative Trigger and Label-Aware Knowledge Guided Model for Dialogue-based Relation Extraction
Mar 30, 2023Dialogue-based Relation Extraction (DRE) aims to predict the relation type of argument pairs that are mentioned in dialogue. The latest trigger-enhanced methods propose trigger prediction tasks to promote DRE. However, these methods are not able to fully leverage the trigger information and even bring noise to relation extraction. To solve these problems, we propose TLAG, which fully leverages the trigger and label-aware knowledge to guide the relation extraction. First, we design an adaptive trigger fusion module to fully leverage the trigger information. Then, we introduce label-aware knowledge to further promote our model's performance. Experimental results on the DialogRE dataset show that our TLAG outperforms the baseline models, and detailed analyses demonstrate the effectiveness of our approach.
Impact Mitigation for Dynamic Legged Robots with Steel Wire Transmission Using Nonlinear Active Compliance Control
Aug 03, 2021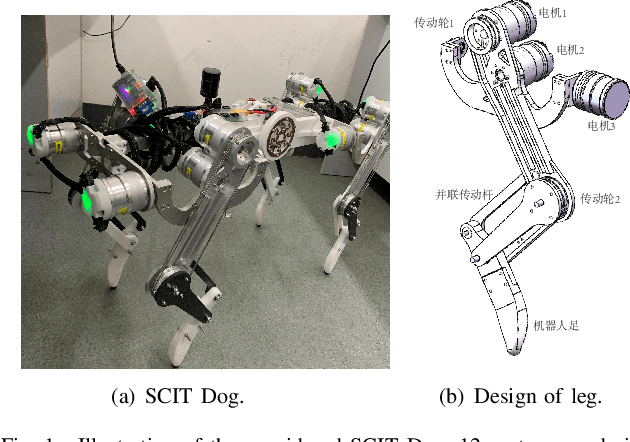
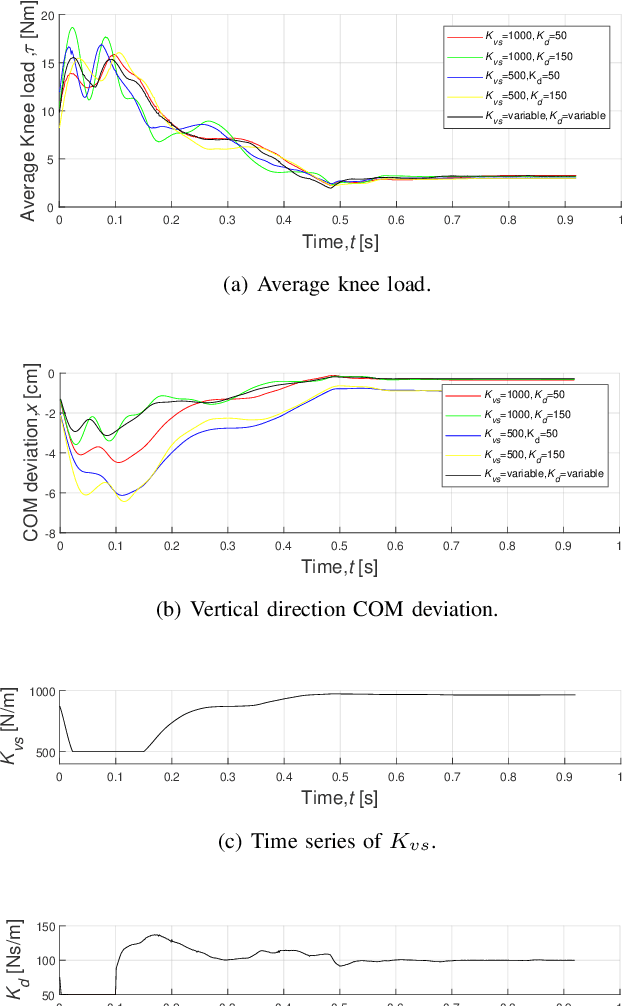
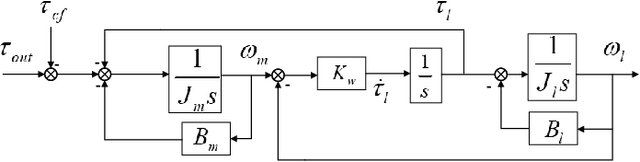
Impact mitigation is crucial to the stable locomotion of legged robots, especially in high-speed dynamic locomotion. This paper presents a leg locomotion system including the nonlinear active compliance control and the active impedance control for the steel wire transmission-based legged robot. The developed control system enables high-speed dynamic locomotion with excellent impact mitigation and leg position tracking performance, where three strategies are applied. a) The feed-forward controller is designed according to the linear motor-leg model with the information of Coulomb friction and viscous friction. b) Steel wire transmission model-based compensation guarantees ideal virtual spring compliance characteristics. c) Nonlinear active compliance control and active impedance control ensure better impact mitigation performance than linear scheme and guarantee position tracking performance. The proposed control system is verified on a real robot named SCIT Dog and the experiment demonstrates the ideal impact mitigation ability in high-speed dynamic locomotion without any passive spring mechanism.