 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSG: Target-Selective Gradient Backprop for Probing CNN Visual Saliency
Oct 11, 2021

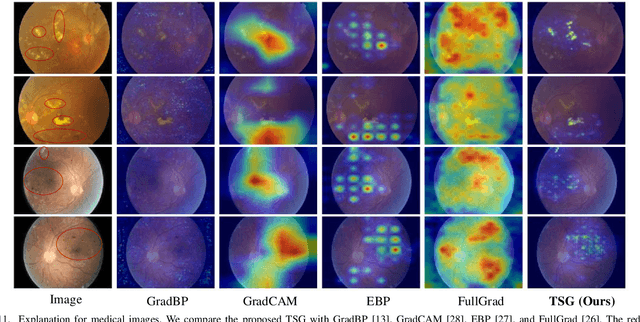
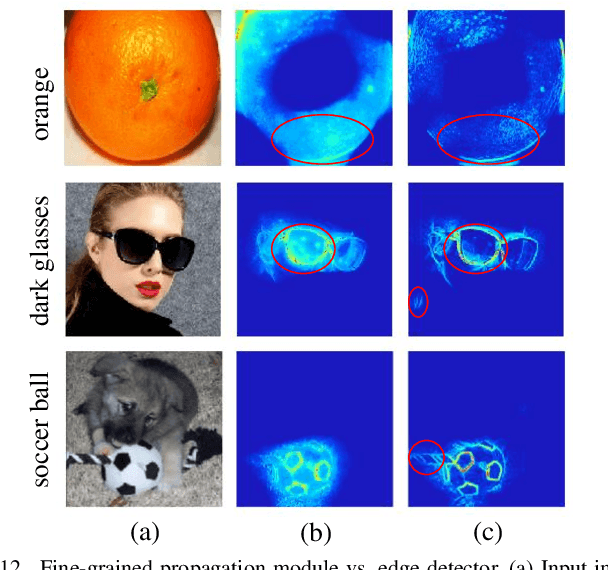
The explanation for deep neural networks has drawn extensive attention in the deep learning community over the past few years. In this work, we study the visual saliency, a.k.a. visual explanation, to interpret convolutional neural networks. Compared to iteration based saliency methods, single backward pass based saliency methods benefit from faster speed and are widely used in downstream visual tasks. Thus our work focuses on single backward pass approaches. However, existing methods in this category struggle to successfully produce fine-grained saliency maps concentrating on specific target classes. That said, producing faithful saliency maps satisfying both target-selectiveness and fine-grainedness using a single backward pass is a challenging problem in the field. To mitigate this problem, we revisit the gradient flow inside the network, and find that the entangled semantics and original weights may disturb the propagation of target-relevant saliency. Inspired by those observations, we propose a novel visual saliency framework, termed Target-Selective Gradient (TSG) backprop, which leverages rectification operations to effectively emphasize target classes and further efficiently propagate the saliency to the input space, thereby generating target-selective and fine-grained saliency maps. The proposed TSG consists of two components, namely, TSG-Conv and TSG-FC, which rectify the gradients for convolutional layers and fully-connected layers, respectively. Thorough qualitative and quantitative experiments on ImageNet and Pascal VOC show that the proposed framework achieves more accurate and reliable results than other competitive methods.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
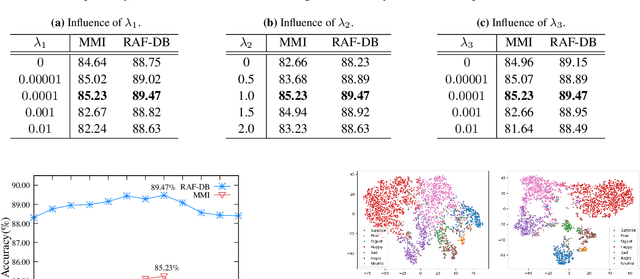
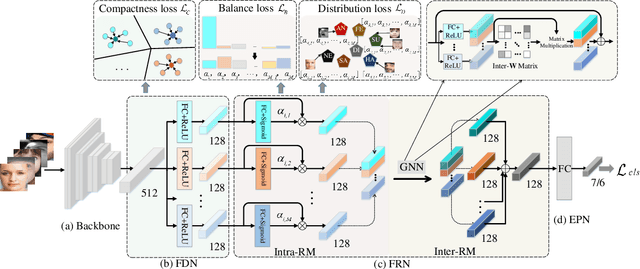
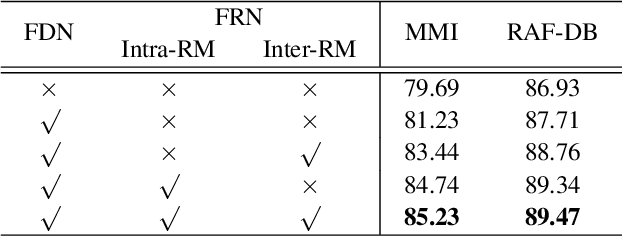
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.
Hierarchical Representation via Message Propagation for Robust Model Fitting
Dec 29, 2020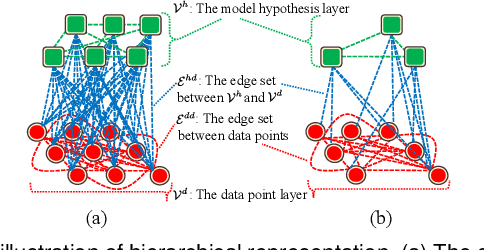


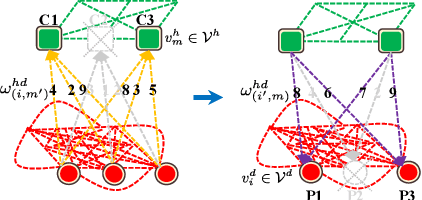
In this paper, we propose a novel hierarchical representation via message propagation (HRMP) method for robust model fitting, which simultaneously takes advantages of both the consensus analysis and the preference analysis to estimate the parameters of multiple model instances from data corrupted by outliers, for robust model fitting. Instead of analyzing the information of each data point or each model hypothesis independently, we formulate the consensus information and the preference information as a hierarchical representation to alleviate the sensitivity to gross outliers. Specifically, we firstly construct a hierarchical representation, which consists of a model hypothesis layer and a data point layer. The model hypothesis layer is used to remove insignificant model hypotheses and the data point layer is used to remove gross outliers. Then, based on the hierarchical representation, we propose an effective hierarchical message propagation (HMP) algorithm and an improved affinity propagation (IAP) algorithm to prune insignificant vertices and cluster the remaining data points, respectively. The proposed HRMP can not only accurately estimate the number and parameters of multiple model instances, but also handle multi-structural data contaminated with a large number of outliers. Experimental results on both synthetic data and real images show that the proposed HRMP significantly outperforms several state-of-the-art model fitting methods in terms of fitting accuracy and speed.
Robust Visual Tracking via Statistical Positive Sample Generation and Gradient Aware Learning
Nov 09, 2020
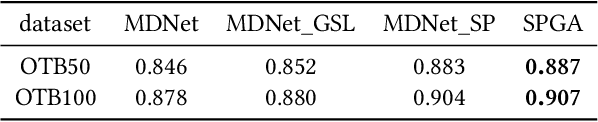
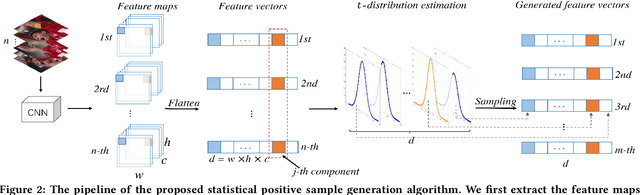
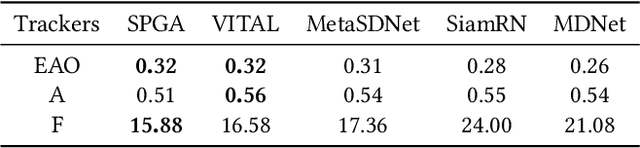
In recent years, Convolutional Neural Network (CNN) based trackers have achieved state-of-the-art performance on multiple benchmark datasets. Most of these trackers train a binary classifier to distinguish the target from its background. However, they suffer from two limitations. Firstly, these trackers cannot effectively handle significant appearance variations due to the limited number of positive samples. Secondly, there exists a significant imbalance of gradient contributions between easy and hard samples, where the easy samples usually dominate the computation of gradient. In this paper, we propose a robust tracking method via Statistical Positive sample generation and Gradient Aware learning (SPGA) to address the above two limitations. To enrich the diversity of positive samples, we present an effective and efficient statistical positive sample generation algorithm to generate positive samples in the feature space. Furthermore, to handle the issue of imbalance between easy and hard samples, we propose a gradient sensitive loss to harmonize the gradient contributions between easy and hard samples. Extensive experiments on three challenging benchmark datasets including OTB50, OTB100 and VOT2016 demonstrate that the proposed SPGA performs favorably against several state-of-the-art trackers.
* 6 pages
Dual Semantic Fusion Network for Video Object Detection
Sep 16, 2020
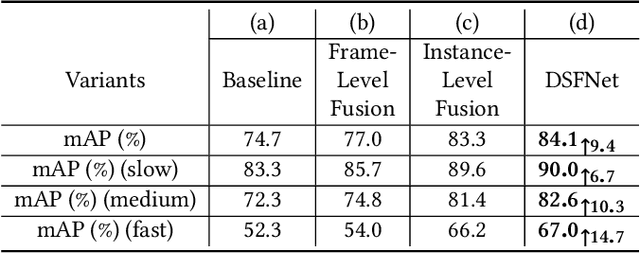
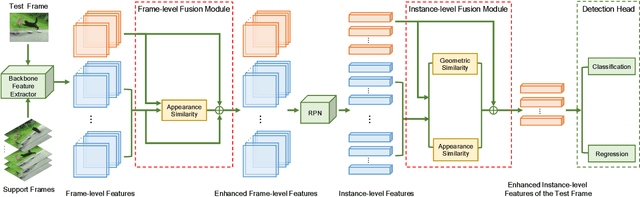
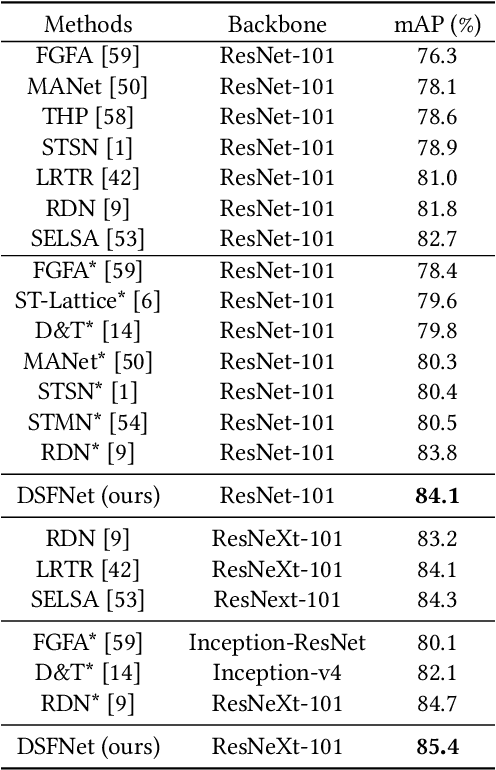
Video object detection is a tough task due to the deteriorated quality of video sequences captured under complex environments. Currently, this area is dominated by a series of feature enhancement based methods, which distill beneficial semantic information from multiple frames and generate enhanced features through fusing the distilled information. However, the distillation and fusion operations are usually performed at either frame level or instance level with external guidance using additional information, such as optical flow and feature memory. In this work, we propose a dual semantic fusion network (abbreviated as DSFNet) to fully exploit both frame-level and instance-level semantics in a unified fusion framework without external guidance. Moreover, we introduce a geometric similarity measure into the fusion process to alleviate the influence of information distortion caused by noise. As a result, the proposed DSFNet can generate more robust features through the multi-granularity fusion and avoid being affected by the instability of external guidance. To evaluate the proposed DSFNet, we conduct extensive experiments on the ImageNet VID dataset. Notably, the proposed dual semantic fusion network achieves, to the best of our knowledge, the best performance of 84.1\% mAP among the current state-of-the-art video object detectors with ResNet-101 and 85.4\% mAP with ResNeXt-101 without using any post-processing steps.
* 9 pages,6 figures
Correlation filter tracking with adaptive proposal selection for accurate scale estimation
Jul 14, 2020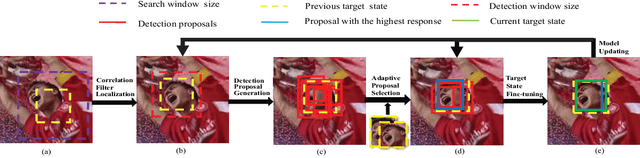
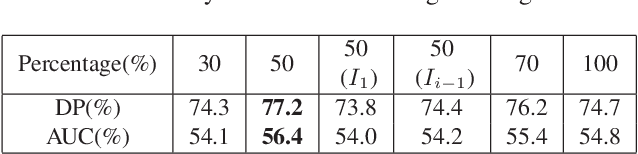
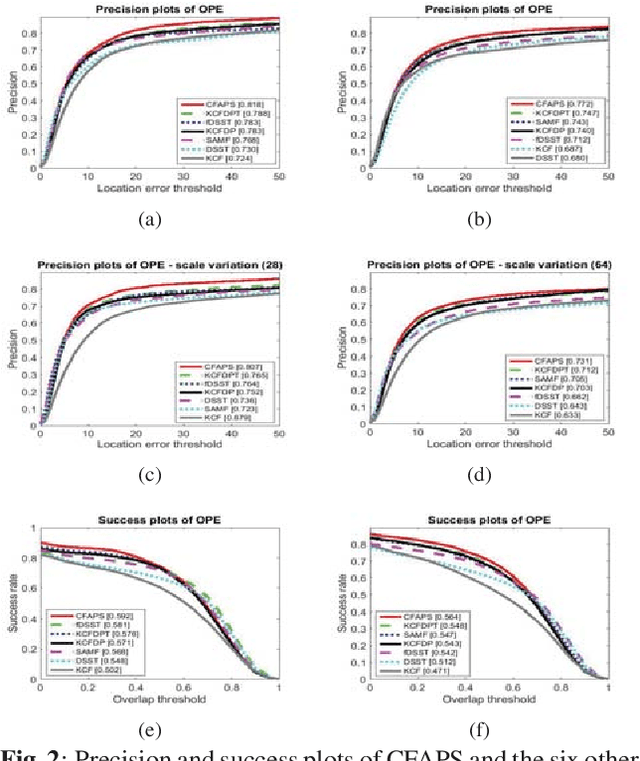
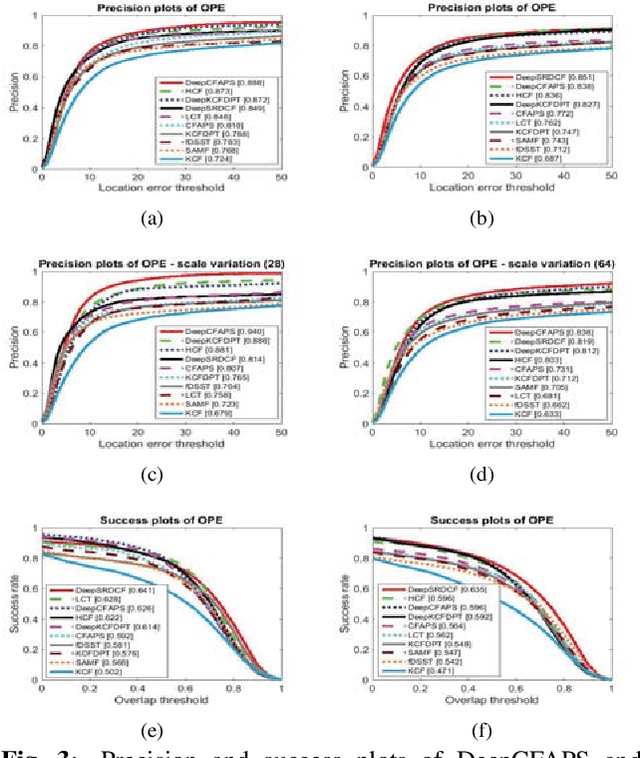
Recently, some correlation filter based trackers with detection proposals have achieved state-of-the-art tracking results. However, a large number of redundant proposals given by the proposal generator may degrade the performance and speed of these trackers. In this paper, we propose an adaptive proposal selection algorithm which can generate a small number of high-quality proposals to handle the problem of scale variations for visual object tracking. Specifically, we firstly utilize the color histograms in the HSV color space to represent the instances (i.e., the initial target in the first frame and the predicted target in the previous frame) and proposals. Then, an adaptive strategy based on the color similarity is formulated to select high-quality proposals. We further integrate the proposed adaptive proposal selection algorithm with coarse-to-fine deep features to validate the generalization and efficiency of the proposed tracker. Experiments on two benchmark datasets demonstrate that the proposed algorithm performs favorably against several state-of-the-art trackers.
Real-Time High-Performance Semantic Image Segmentation of Urban Street Scenes
Apr 03, 2020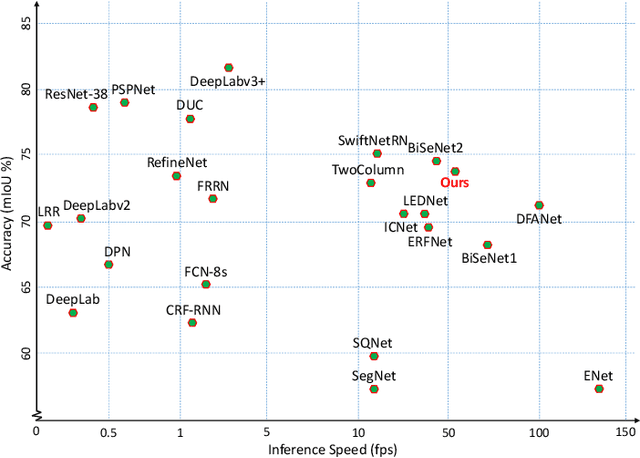


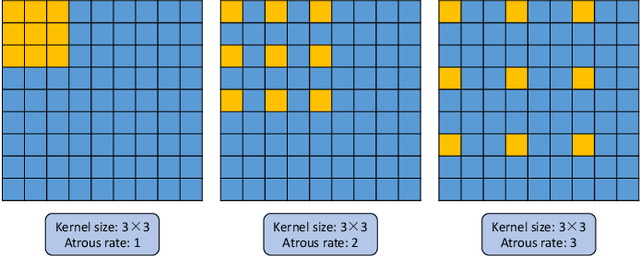
Deep Convolutional Neural Networks (DCNNs) have recently shown outstanding performance in semantic image segmentation. However, state-of-the-art DCNN-based semantic segmentation methods usually suffer from high computational complexity due to the use of complex network architectures. This greatly limits their applications in the real-world scenarios that require real-time processing. In this paper, we propose a real-time high-performance DCNN-based method for robust semantic segmentation of urban street scenes, which achieves a good trade-off between accuracy and speed. Specifically, a Lightweight Baseline Network with Atrous convolution and Attention (LBN-AA) is firstly used as our baseline network to efficiently obtain dense feature maps. Then, the Distinctive Atrous Spatial Pyramid Pooling (DASPP), which exploits the different sizes of pooling operations to encode the rich and distinctive semantic information, is developed to detect objects at multiple scales. Meanwhile, a Spatial detail-Preserving Network (SPN) with shallow convolutional layers is designed to generate high-resolution feature maps preserving the detailed spatial information. Finally, a simple but practical Feature Fusion Network (FFN) is used to effectively combine both shallow and deep features from the semantic branch (DASPP) and the spatial branch (SPN), respectively. Extensive experimental results show that the proposed method respectively achieves the accuracy of 73.6% and 68.0% mean Intersection over Union (mIoU) with the inference speed of 51.0 fps and 39.3 fps on the challenging Cityscapes and CamVid test datasets (by only using a single NVIDIA TITAN X card). This demonstrates that the proposed method offers excellent performance at the real-time speed for semantic segmentation of urban street scenes.
Learning Object Scale With Click Supervision for Object Detection
Feb 20, 2020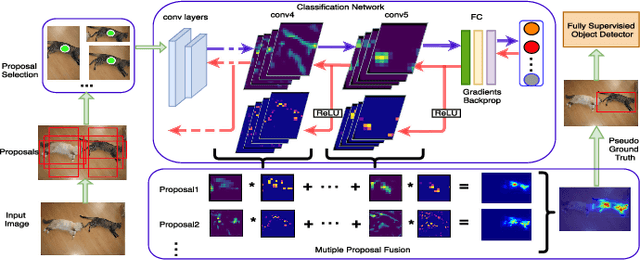

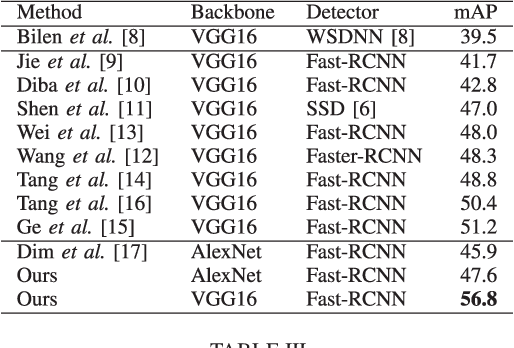
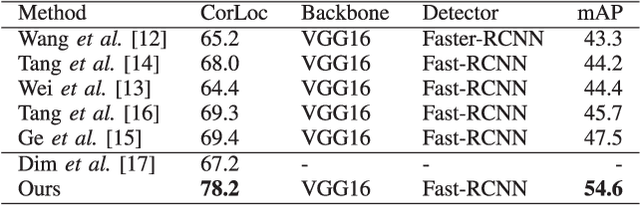
Weakly-supervised object detection has recently attracted increasing attention since it only requires image-levelannotations. However, the performance obtained by existingmethods is still far from being satisfactory compared with fully-supervised object detection methods. To achieve a good trade-off between annotation cost and object detection performance,we propose a simple yet effective method which incorporatesCNN visualization with click supervision to generate the pseudoground-truths (i.e., bounding boxes). These pseudo ground-truthscan be used to train a fully-supervised detector. To estimatethe object scale, we firstly adopt a proposal selection algorithmto preserve high-quality proposals, and then generate ClassActivation Maps (CAMs) for these preserved proposals by theproposed CNN visualization algorithm called Spatial AttentionCAM. Finally, we fuse these CAMs together to generate pseudoground-truths and train a fully-supervised object detector withthese ground-truths. Experimental results on the PASCAL VOC2007 and VOC 2012 datasets show that the proposed methodcan obtain much higher accuracy for estimating the object scale,compared with the state-of-the-art image-level based methodsand the center-click based method
End-to-end Learning of Object Motion Estimation from Retinal Events for Event-based Object Tracking
Feb 14, 2020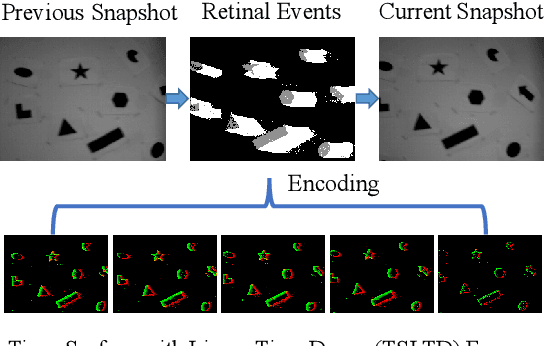

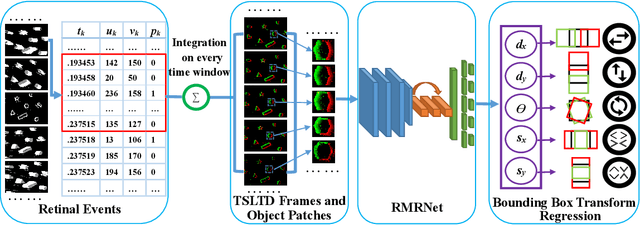
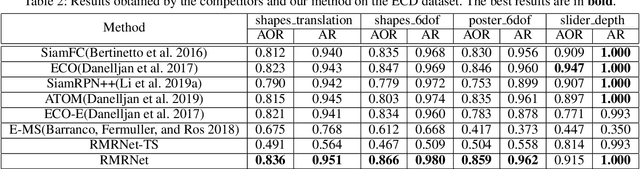
Event cameras, which are asynchronous bio-inspired vision sensors, have shown great potential in computer vision and artificial intelligence. However, the application of event cameras to object-level motion estimation or tracking is still in its infancy. The main idea behind this work is to propose a novel deep neural network to learn and regress a parametric object-level motion/transform model for event-based object tracking. To achieve this goal, we propose a synchronous Time-Surface with Linear Time Decay (TSLTD) representation, which effectively encodes the spatio-temporal information of asynchronous retinal events into TSLTD frames with clear motion patterns. We feed the sequence of TSLTD frames to a novel Retinal Motion Regression Network (RMRNet) to perform an end-to-end 5-DoF object motion regression. Our method is compared with state-of-the-art object tracking methods, that are based on conventional cameras or event cameras. The experimental results show the superiority of our method in handling various challenging environments such as fast motion and low illumination conditions.
Asynchronous Tracking-by-Detection on Adaptive Time Surfaces for Event-based Object Tracking
Feb 13, 2020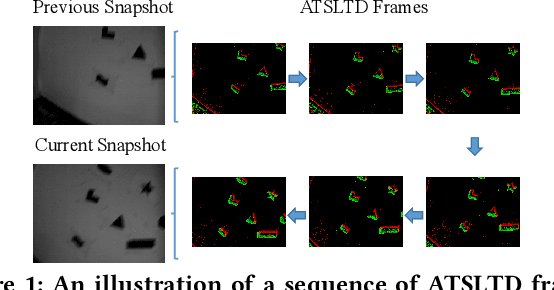


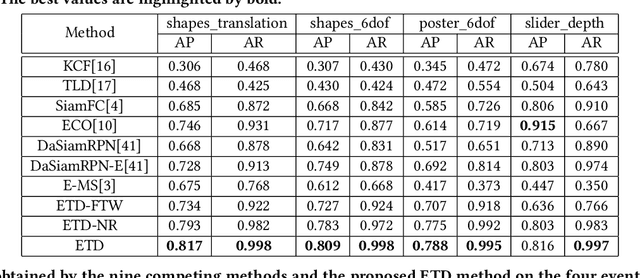
Event cameras, which are asynchronous bio-inspired vision sensors, have shown great potential in a variety of situations, such as fast motion and low illumination scenes. However, most of the event-based object tracking methods are designed for scenarios with untextured objects and uncluttered backgrounds. There are few event-based object tracking methods that support bounding box-based object tracking. The main idea behind this work is to propose an asynchronous Event-based Tracking-by-Detection (ETD) method for generic bounding box-based object tracking. To achieve this goal, we present an Adaptive Time-Surface with Linear Time Decay (ATSLTD) event-to-frame conversion algorithm, which asynchronously and effectively warps the spatio-temporal information of asynchronous retinal events to a sequence of ATSLTD frames with clear object contours. We feed the sequence of ATSLTD frames to the proposed ETD method to perform accurate and efficient object tracking, which leverages the high temporal resolution property of event cameras. We compare the proposed ETD method with seven popular object tracking methods, that are based on conventional cameras or event cameras, and two variants of ETD. The experimental results show the superiority of the proposed ETD method in handling various challenging environments.
* 9 pages, 5 figures