 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFP: Speculative Decoding with FIT-Pruned Models for Training-Free and Plug-and-Play LLM Acceleration
Feb 05, 2026Large language models (LLMs) underpin interactive multimedia applications such as captioning, retrieval, recommendation, and creative content generation, yet their autoregressive decoding incurs substantial latency. Speculative decoding reduces latency using a lightweight draft model, but deployment is often limited by the cost and complexity of acquiring, tuning, and maintaining an effective draft model. Recent approaches usually require auxiliary training or specialization, and even training-free methods incur costly search or optimization. We propose SDFP, a fully training-free and plug-and-play framework that builds the draft model via Fisher Information Trace (FIT)-based layer pruning of a given LLM. Using layer sensitivity as a proxy for output perturbation, SDFP removes low-impact layers to obtain a compact draft while preserving compatibility with the original model for standard speculative verification. SDFP needs no additional training, hyperparameter tuning, or separately maintained drafts, enabling rapid, deployment-friendly draft construction. Across benchmarks, SDFP delivers 1.32x-1.5x decoding speedup without altering the target model's output distribution, supporting low-latency multimedia applications.
AKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit Quantization for Vision-Language Models
Jan 25, 2025



Vision-language models (VLMs) show remarkable performance in multimodal tasks. However, excessively long multimodal inputs lead to oversized Key-Value (KV) caches, resulting in significant memory consumption and I/O bottlenecks. Previous KV quantization methods for Large Language Models (LLMs) may alleviate these issues but overlook the attention saliency differences of multimodal tokens, resulting in suboptimal performance. In this paper, we investigate the attention-aware token saliency patterns in VLM and propose AKVQ-VL. AKVQ-VL leverages the proposed Text-Salient Attention (TSA) and Pivot-Token-Salient Attention (PSA) patterns to adaptively allocate bit budgets. Moreover, achieving extremely low-bit quantization requires effectively addressing outliers in KV tensors. AKVQ-VL utilizes the Walsh-Hadamard transform (WHT) to construct outlier-free KV caches, thereby reducing quantization difficulty. Evaluations of 2-bit quantization on 12 long-context and multimodal tasks demonstrate that AKVQ-VL maintains or even improves accuracy, outperforming LLM-oriented methods. AKVQ-VL can reduce peak memory usage by 2.13x, support up to 3.25x larger batch sizes and 2.46x throughput.
Swinv2-Imagen: Hierarchical Vision Transformer Diffusion Models for Text-to-Image Generation
Oct 18, 2022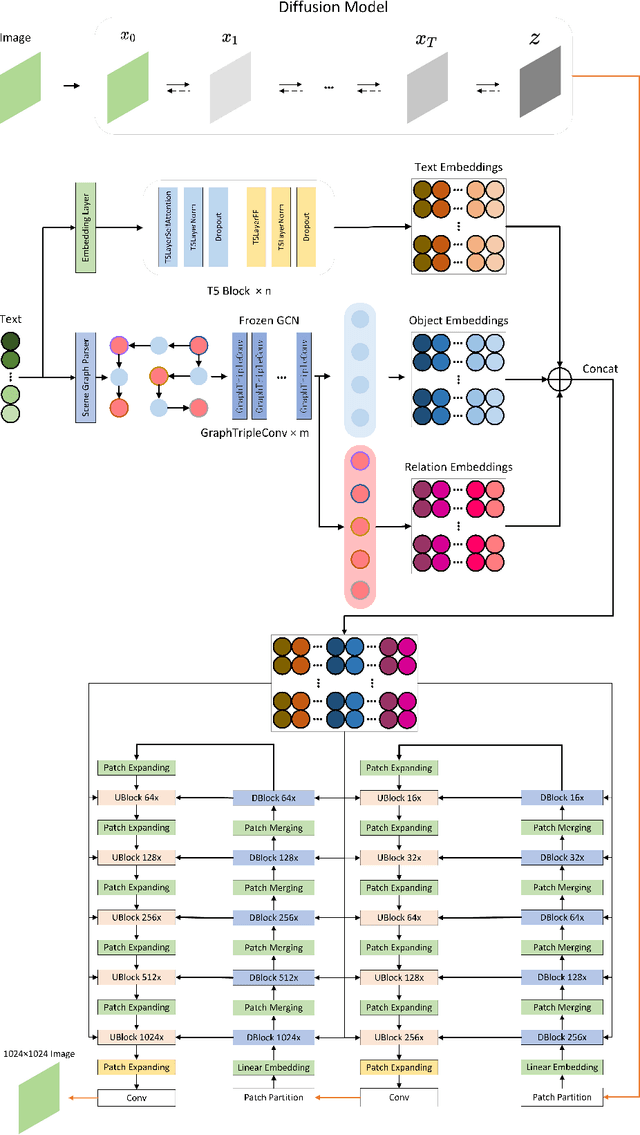
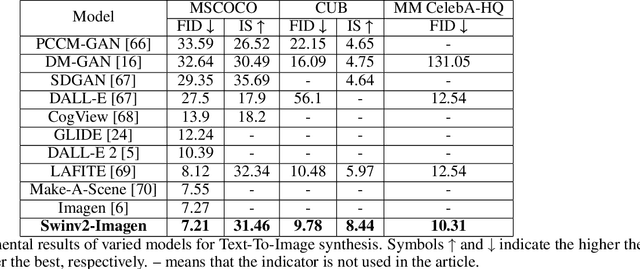
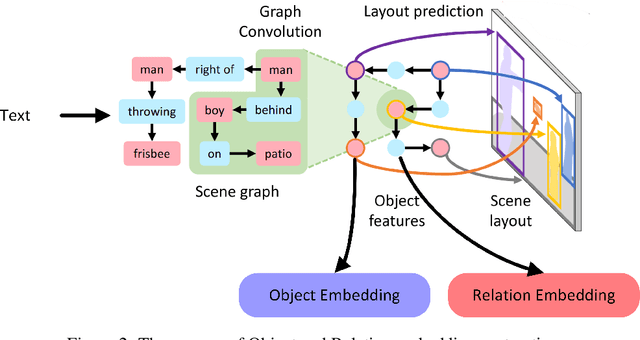

Recently, diffusion models have been proven to perform remarkably well in text-to-image synthesis tasks in a number of studies, immediately presenting new study opportunities for image generation. Google's Imagen follows this research trend and outperforms DALLE2 as the best model for text-to-image generation. However, Imagen merely uses a T5 language model for text processing, which cannot ensure learning the semantic information of the text. Furthermore, the Efficient UNet leveraged by Imagen is not the best choice in image processing. To address these issues, we propose the Swinv2-Imagen, a novel text-to-image diffusion model based on a Hierarchical Visual Transformer and a Scene Graph incorporating a semantic layout. In the proposed model, the feature vectors of entities and relationships are extracted and involved in the diffusion model, effectively improving the quality of generated images. On top of that, we also introduce a Swin-Transformer-based UNet architecture, called Swinv2-Unet, which can address the problems stemming from the CNN convolution operations. Extensive experiments are conducted to evaluate the performance of the proposed model by using three real-world datasets, i.e., MSCOCO, CUB and MM-CelebA-HQ. The experimental results show that the proposed Swinv2-Imagen model outperforms several popular state-of-the-art methods.