 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Physically Based Rendering and Diffusion Models with Stochastic Differential Equation
Feb 24, 2026Diffusion-based image generators excel at producing realistic content from text or image conditions, but they offer only limited explicit control over low-level, physically grounded shading and material properties. In contrast, physically based rendering (PBR) offers fine-grained physical control but lacks prompt-driven flexibility. Although these two paradigms originate from distinct communities, both share a common evolution -- from noisy observations to clean images. In this paper, we propose a unified stochastic formulation that bridges Monte Carlo rendering and diffusion-based generative modeling. First, a general stochastic differential equation (SDE) formulation for Monte Carlo integration under the Central Limit Theorem is modeled. Through instantiation via physically based path tracing, we convert it into a physically grounded SDE representation. Moreover, we provide a systematic analysis of how the physical characteristics of path tracing can be extended to existing diffusion models from the perspective of noise variance. Extensive experiments across multiple tasks show that our method can exert physically grounded control over diffusion-generated results, covering tasks such as rendering and material editing.
ROSE: Remove Objects with Side Effects in Videos
Aug 26, 2025Video object removal has achieved advanced performance due to the recent success of video generative models. However, when addressing the side effects of objects, e.g., their shadows and reflections, existing works struggle to eliminate these effects for the scarcity of paired video data as supervision. This paper presents ROSE, termed Remove Objects with Side Effects, a framework that systematically studies the object's effects on environment, which can be categorized into five common cases: shadows, reflections, light, translucency and mirror. Given the challenges of curating paired videos exhibiting the aforementioned effects, we leverage a 3D rendering engine for synthetic data generation. We carefully construct a fully-automatic pipeline for data preparation, which simulates a large-scale paired dataset with diverse scenes, objects, shooting angles, and camera trajectories. ROSE is implemented as an video inpainting model built on diffusion transformer. To localize all object-correlated areas, the entire video is fed into the model for reference-based erasing. Moreover, additional supervision is introduced to explicitly predict the areas affected by side effects, which can be revealed through the differential mask between the paired videos. To fully investigate the model performance on various side effect removal, we presents a new benchmark, dubbed ROSE-Bench, incorporating both common scenarios and the five special side effects for comprehensive evaluation. Experimental results demonstrate that ROSE achieves superior performance compared to existing video object erasing models and generalizes well to real-world video scenarios. The project page is https://rose2025-inpaint.github.io/.
Translational Symmetry-Aware Facade Parsing for 3D Building Reconstruction
Jun 02, 2021
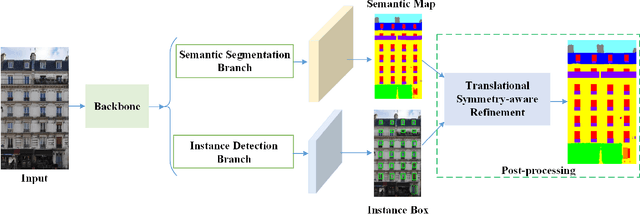
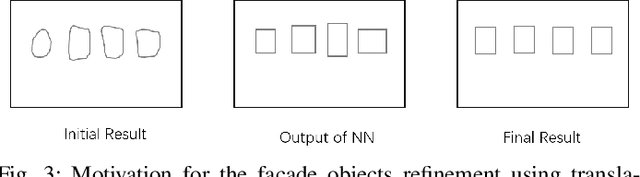

Effectively parsing the facade is essential to 3D building reconstruction, which is an important computer vision problem with a large amount of applications in high precision map for navigation, computer aided design, and city generation for digital entertainments. To this end, the key is how to obtain the shape grammars from 2D images accurately and efficiently. Although enjoying the merits of promising results on the semantic parsing, deep learning methods cannot directly make use of the architectural rules, which play an important role for man-made structures. In this paper, we present a novel translational symmetry-based approach to improving the deep neural networks. Our method employs deep learning models as the base parser, and a module taking advantage of translational symmetry is used to refine the initial parsing results. In contrast to conventional semantic segmentation or bounding box prediction, we propose a novel scheme to fuse segmentation with anchor-free detection in a single stage network, which enables the efficient training and better convergence. After parsing the facades into shape grammars, we employ an off-the-shelf rendering engine like Blender to reconstruct the realistic high-quality 3D models using procedural modeling. We conduct experiments on three public datasets, where our proposed approach outperforms the state-of-the-art methods. In addition, we have illustrated the 3D building models built from 2D facade images.
Robust Estimation of Similarity Transformation for Visual Object Tracking with Correlation Filters
Dec 14, 2017
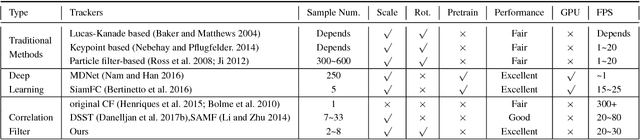
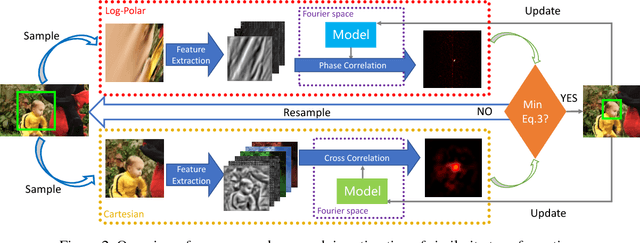

Most of existing correlation filter-based tracking approaches only estimate simple axis-aligned bounding boxes, and very few of them is capable of recovering the underlying similarity transformation. To a large extent, such limitation restricts the applications of such trackers for a wide range of scenarios. In this paper, we propose a novel correlation filter-based tracker with robust estimation of similarity transformation on the large displacements to tackle this challenging problem. In order to efficiently search in such a large 4-DoF space in real-time, we formulate the problem into two 2-DoF sub-problems and apply an efficient Block Coordinates Descent solver to optimize the estimation result. Specifically, we employ an efficient phase correlation scheme to deal with both scale and rotation changes simultaneously in log-polar coordinates. Moreover, a fast variant of correlation filter is used to predict the translational motion individually. Our experimental results demonstrate that the proposed tracker achieves very promising prediction performance compared with the state-of-the-art visual object tracking methods while still retaining the advantages of efficiency and simplicity in conventional correlation filter-based tracking methods.
LOGO-Net: Large-scale Deep Logo Detection and Brand Recognition with Deep Region-based Convolutional Networks
Nov 13, 2015
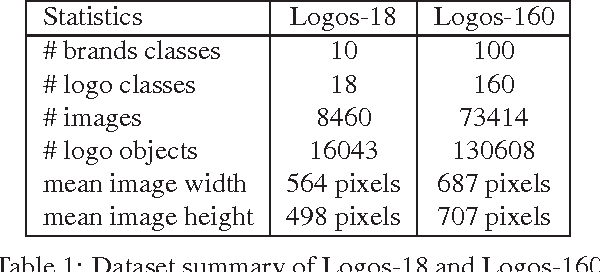
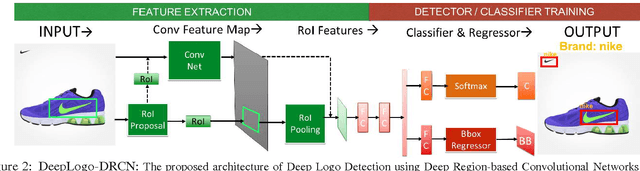
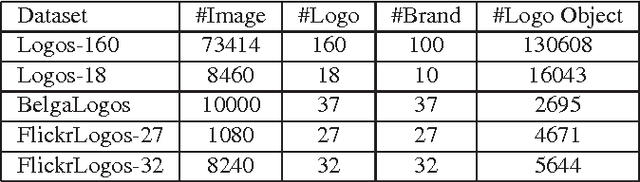
Logo detection from images has many applications, particularly for brand recognition and intellectual property protection. Most existing studies for logo recognition and detection are based on small-scale datasets which are not comprehensive enough when exploring emerging deep learning techniques. In this paper, we introduce "LOGO-Net", a large-scale logo image database for logo detection and brand recognition from real-world product images. To facilitate research, LOGO-Net has two datasets: (i)"logos-18" consists of 18 logo classes, 10 brands, and 16,043 logo objects, and (ii) "logos-160" consists of 160 logo classes, 100 brands, and 130,608 logo objects. We describe the ideas and challenges for constructing such a large-scale database. Another key contribution of this work is to apply emerging deep learning techniques for logo detection and brand recognition tasks, and conduct extensive experiments by exploring several state-of-the-art deep region-based convolutional networks techniques for object detection tasks. The LOGO-net will be released at http://logo-net.org/