 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Value Iteration Networks
Nov 27, 2019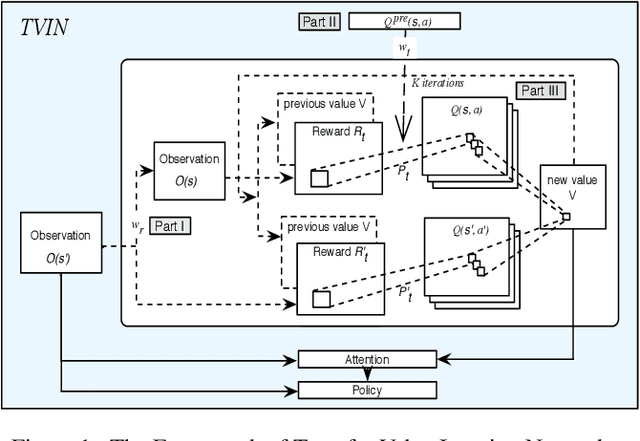
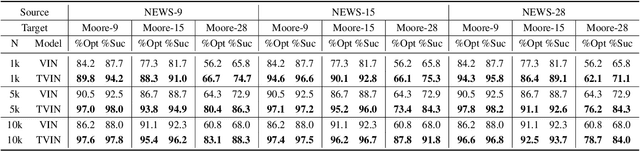
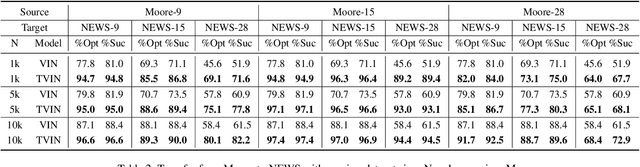
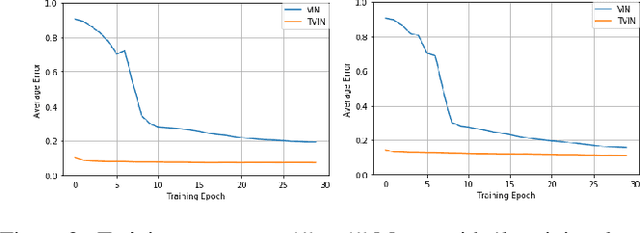
Value iteration networks (VINs) have been demonstrated to have a good generalization ability for reinforcement learning tasks across similar domains. However, based on our experiments, a policy learned by VINs still fail to generalize well on the domain whose action space and feature space are not identical to those in the domain where it is trained. In this paper, we propose a transfer learning approach on top of VINs, termed Transfer VINs (TVINs), such that a learned policy from a source domain can be generalized to a target domain with only limited training data, even if the source domain and the target domain have domain-specific actions and features. We empirically verify that our proposed TVINs outperform VINs when the source and the target domains have similar but not identical action and feature spaces. Furthermore, we show that the performance improvement is consistent across different environments, maze sizes, dataset sizes as well as different values of hyperparameters such as number of iteration and kernel size.
Repositioning Bikes with Carrier Vehicles and Bike Trailers in Bike Sharing Systems
Sep 20, 2019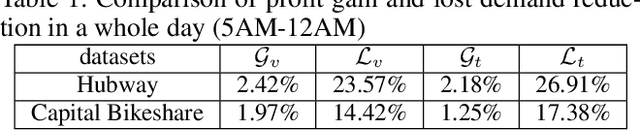
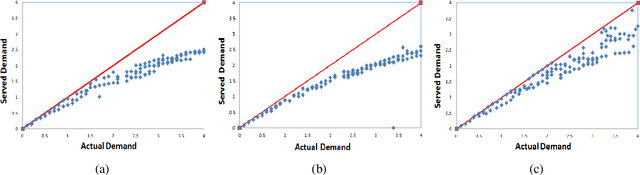
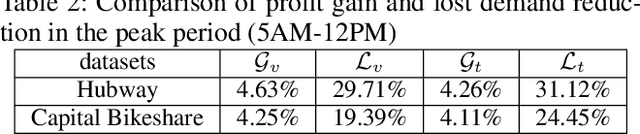
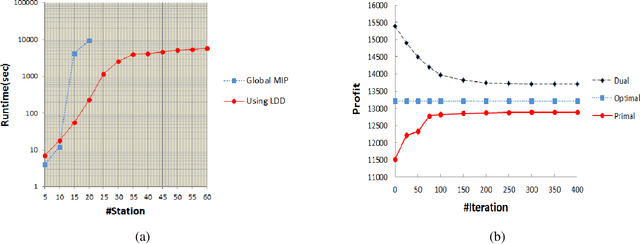
Bike Sharing Systems (BSSs) have been adopted in many major cities of the world due to traffic congestion and carbon emissions. Although there have been approaches to exploiting either bike trailers via crowdsourcing or carrier vehicles to reposition bikes in the ``right'' stations in the ``right'' time, they do not jointly consider the usage of both bike trailers and carrier vehicles. In this paper, we aim to take advantage of both bike trailers and carrier vehicles to reduce the loss of demand with regard to the crowdsourcing of bike trailers and the fuel cost of carrier vehicles. In the experiment, we exhibit that our approach outperforms baselines in several datasets from bike sharing companies.
Learning Action Models from Disordered and Noisy Plan Traces
Sep 09, 2019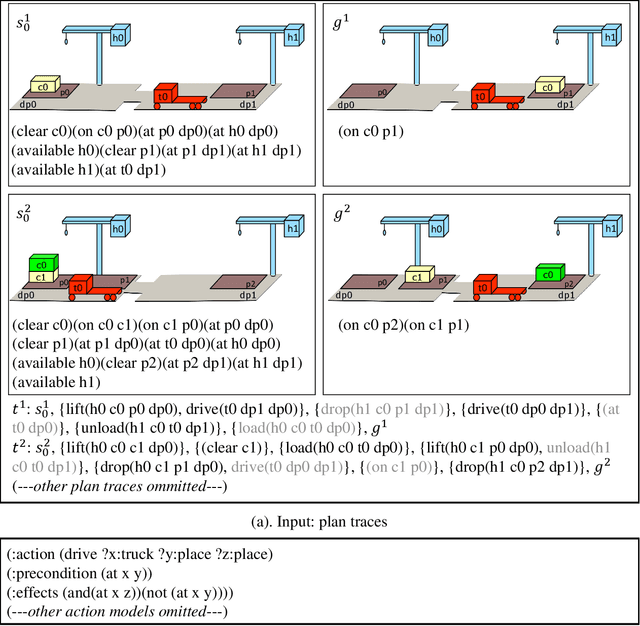
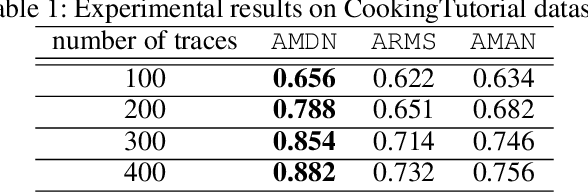
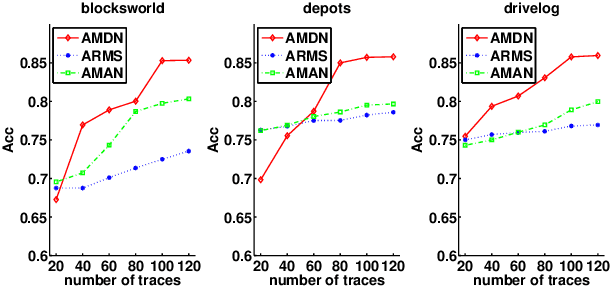
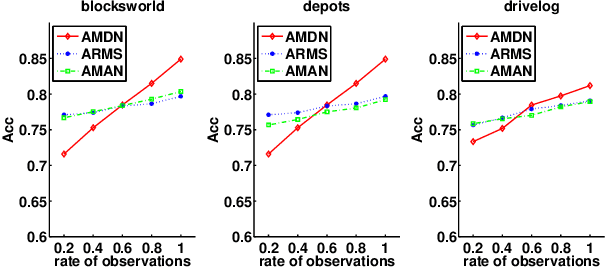
There is increasing awareness in the planning community that the burden of specifying complete domain models is too high, which impedes the applicability of planning technology in many real-world domains. Although there have many learning systems that help automatically learning domain models, most existing work assumes that the input traces are completely correct. A more realistic situation is that the plan traces are disordered and noisy, such as plan traces described by natural language. In this paper we propose and evaluate an approach for doing this. Our approach takes as input a set of plan traces with disordered actions and noise and outputs action models that can best explain the plan traces. We use a MAX-SAT framework for learning, where the constraints are derived from the given plan traces. Unlike traditional action models learners, the states in plan traces can be partially observable and noisy as well as the actions in plan traces can be disordered and parallel. We demonstrate the effectiveness of our approach through a systematic empirical evaluation with both IPC domains and the real-world dataset extracted from natural language documents.
Federated Hierarchical Hybrid Networks for Clickbait Detection
Jun 03, 2019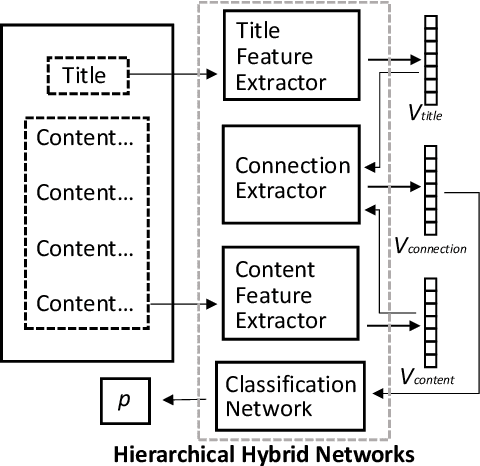
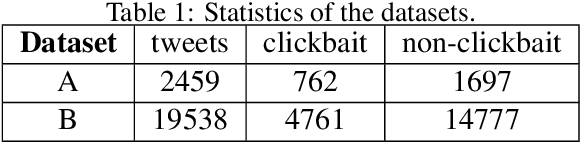
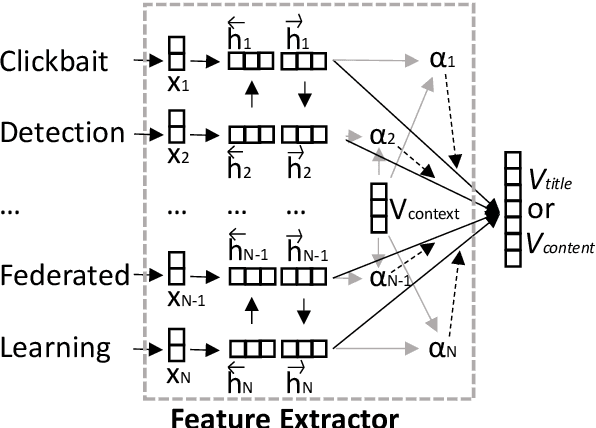
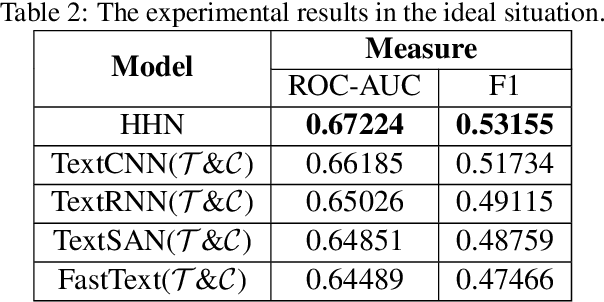
Online media outlets adopt clickbait techniques to lure readers to click on articles in a bid to expand their reach and subsequently increase revenue through ad monetization. As the adverse effects of clickbait attract more and more attention, researchers have started to explore machine learning techniques to automatically detect clickbaits. Previous work on clickbait detection assumes that all the training data is available locally during training. In many real-world applications, however, training data is generally distributedly stored by different parties (e.g., different parties maintain data with different feature spaces), and the parties cannot share their data with each other due to data privacy issues. It is challenging to build models of high-quality federally for detecting clickbaits effectively without data sharing. In this paper, we propose a federated training framework, which is called federated hierarchical hybrid networks, to build clickbait detection models, where the titles and contents are stored by different parties, whose relationships must be exploited for clickbait detection. We empirically demonstrate that our approach is effective by comparing our approach to the state-of-the-art approaches using datasets from social media.
Federated Reinforcement Learning
Jan 25, 2019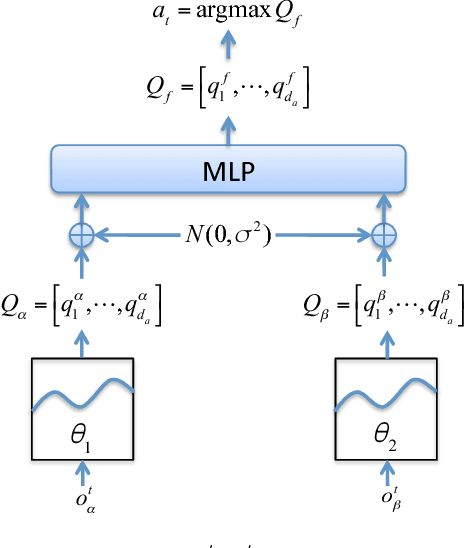
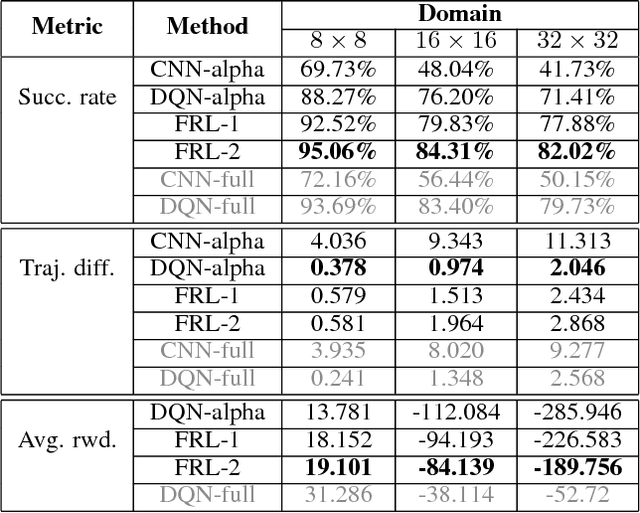
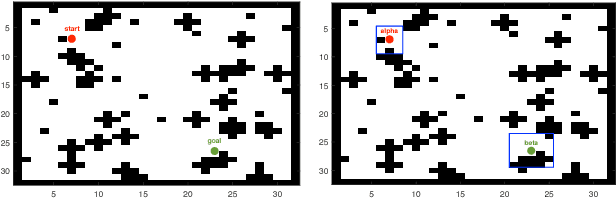
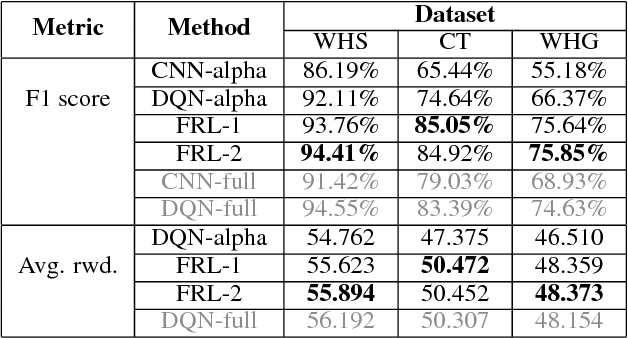
In reinforcement learning, building policies of high-quality is challenging when the feature space of states is small and the training data is limited. Directly transferring data or knowledge from an agent to another agent will not work due to the privacy requirement of data and models. In this paper, we propose a novel reinforcement learning approach to considering the privacy requirement and building Q-network for each agent with the help of other agents, namely federated reinforcement learning (FRL). To protect the privacy of data and models, we exploit Gausian differentials on the information shared with each other when updating their local models. In the experiment, we evaluate our FRL framework in two diverse domains, Grid-world and Text2Action domains, by comparing to various baselines.
Extracting Action Sequences from Texts Based on Deep Reinforcement Learning
May 11, 2018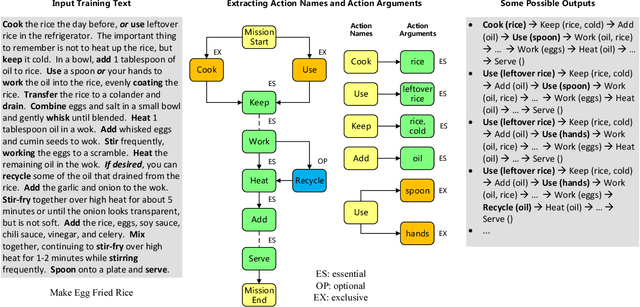
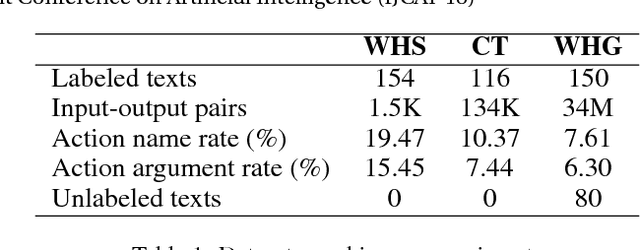

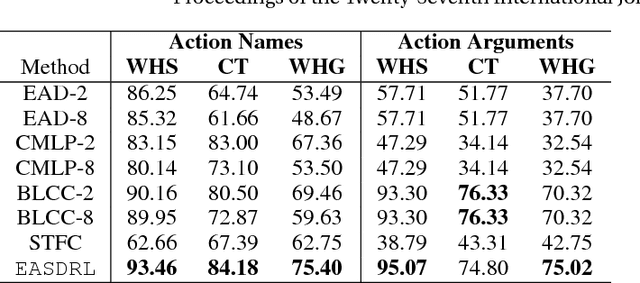
Extracting action sequences from natural language texts is challenging, as it requires commonsense inferences based on world knowledge. Although there has been work on extracting action scripts, instructions, navigation actions, etc., they require that either the set of candidate actions be provided in advance, or that action descriptions are restricted to a specific form, e.g., description templates. In this paper, we aim to extract action sequences from texts in free natural language, i.e., without any restricted templates, provided the candidate set of actions is unknown. We propose to extract action sequences from texts based on the deep reinforcement learning framework. Specifically, we view "selecting" or "eliminating" words from texts as "actions", and the texts associated with actions as "states". We then build Q-networks to learn the policy of extracting actions and extract plans from the labeled texts. We demonstrate the effectiveness of our approach on several datasets with comparison to state-of-the-art approaches, including online experiments interacting with humans.
An Integrated Development Environment for Planning Domain Modeling
Apr 19, 2018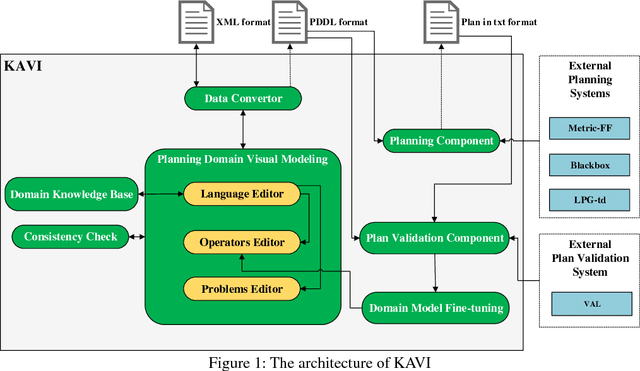
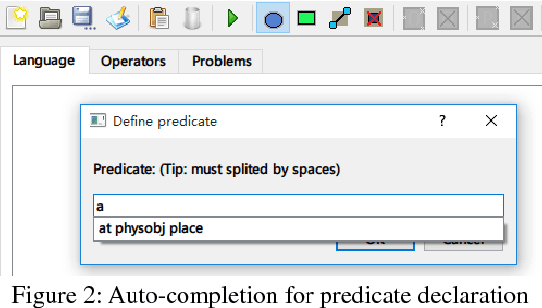
In order to make the task, description of planning domains and problems, more comprehensive for non-experts in planning, the visual representation has been used in planning domain modeling in recent years. However, current knowledge engineering tools with visual modeling, like itSIMPLE (Vaquero et al. 2012) and VIZ (Vodr\'a\v{z}ka and Chrpa 2010), are less efficient than the traditional method of hand-coding by a PDDL expert using a text editor, and rarely involved in finetuning planning domains depending on the plan validation. Aim at this, we present an integrated development environment KAVI for planning domain modeling inspired by itSIMPLE and VIZ. KAVI using an abstract domain knowledge base to improve the efficiency of planning domain visual modeling. By integrating planners and a plan validator, KAVI proposes a method to fine-tune planning domains based on the plan validation.
Discovering Underlying Plans Based on Shallow Models
Mar 04, 2018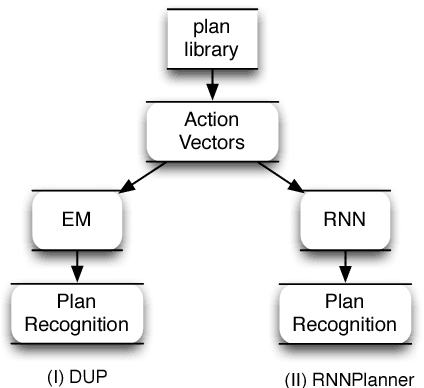
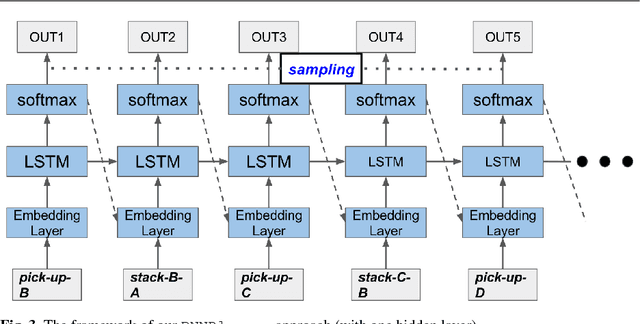
Plan recognition aims to discover target plans (i.e., sequences of actions) behind observed actions, with history plan libraries or domain models in hand. Previous approaches either discover plans by maximally "matching" observed actions to plan libraries, assuming target plans are from plan libraries, or infer plans by executing domain models to best explain the observed actions, assuming that complete domain models are available. In real world applications, however, target plans are often not from plan libraries, and complete domain models are often not available, since building complete sets of plans and complete domain models are often difficult or expensive. In this paper we view plan libraries as corpora and learn vector representations of actions using the corpora, we then discover target plans based on the vector representations. Specifically, we propose two approaches, DUP and RNNPlanner, to discover target plans based on vector representations of actions. DUP explores the EM-style framework to capture local contexts of actions and discover target plans by optimizing the probability of target plans, while RNNPlanner aims to leverage long-short term contexts of actions based on RNNs (recurrent neural networks) framework to help recognize target plans. In the experiments, we empirically show that our approaches are capable of discovering underlying plans that are not from plan libraries, without requiring domain models provided. We demonstrate the effectiveness of our approaches by comparing its performance to traditional plan recognition approaches in three planning domains. We also compare DUP and RNNPlanner to see their advantages and disadvantages.
Distributed-Representation Based Hybrid Recommender System with Short Item Descriptions
Mar 15, 2017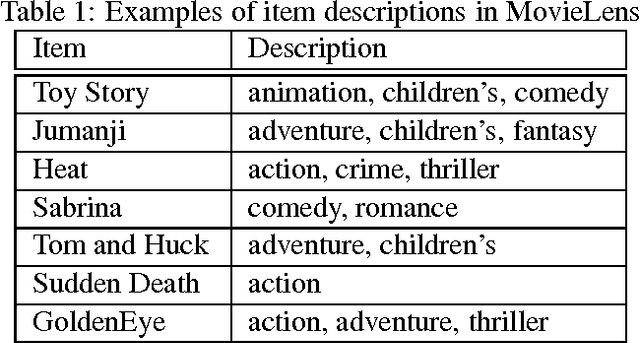
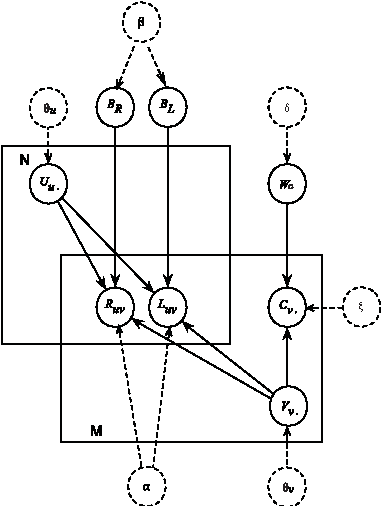
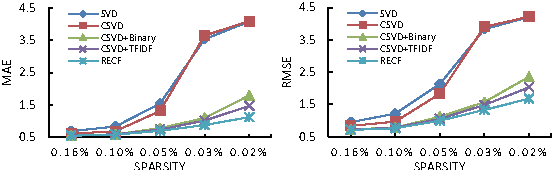
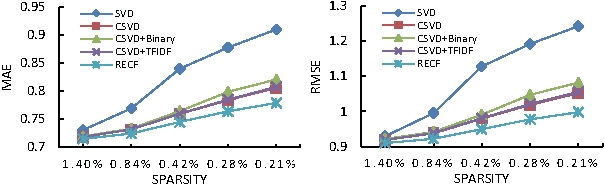
Collaborative filtering (CF) aims to build a model from users' past behaviors and/or similar decisions made by other users, and use the model to recommend items for users. Despite of the success of previous collaborative filtering approaches, they are all based on the assumption that there are sufficient rating scores available for building high-quality recommendation models. In real world applications, however, it is often difficult to collect sufficient rating scores, especially when new items are introduced into the system, which makes the recommendation task challenging. We find that there are often "short" texts describing features of items, based on which we can approximate the similarity of items and make recommendation together with rating scores. In this paper we "borrow" the idea of vector representation of words to capture the information of short texts and embed it into a matrix factorization framework. We empirically show that our approach is effective by comparing it with state-of-the-art approaches.
LTSG: Latent Topical Skip-Gram for Mutually Learning Topic Model and Vector Representations
Feb 23, 2017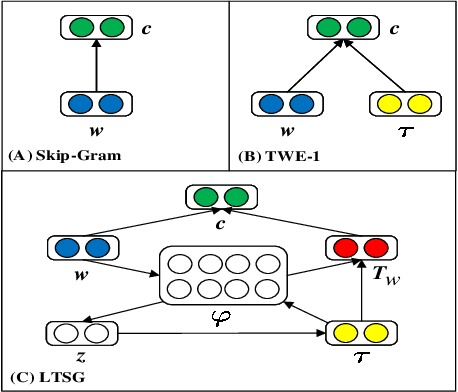

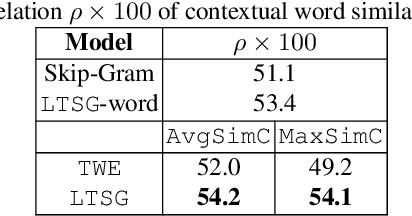
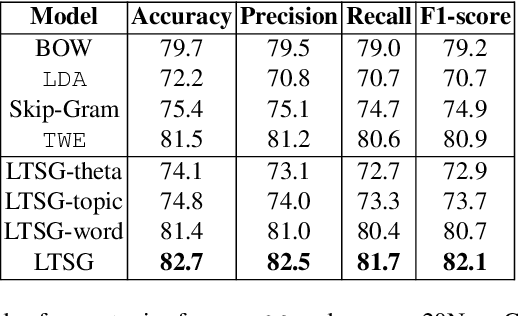
Topic models have been widely used in discovering latent topics which are shared across documents in text mining. Vector representations, word embeddings and topic embeddings, map words and topics into a low-dimensional and dense real-value vector space, which have obtained high performance in NLP tasks. However, most of the existing models assume the result trained by one of them are perfect correct and used as prior knowledge for improving the other model. Some other models use the information trained from external large corpus to help improving smaller corpus. In this paper, we aim to build such an algorithm framework that makes topic models and vector representations mutually improve each other within the same corpus. An EM-style algorithm framework is employed to iteratively optimize both topic model and vector representations. Experimental results show that our model outperforms state-of-art methods on various NLP tasks.