 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed-Representation Based Hybrid Recommender System with Short Item Descriptions
Mar 15, 2017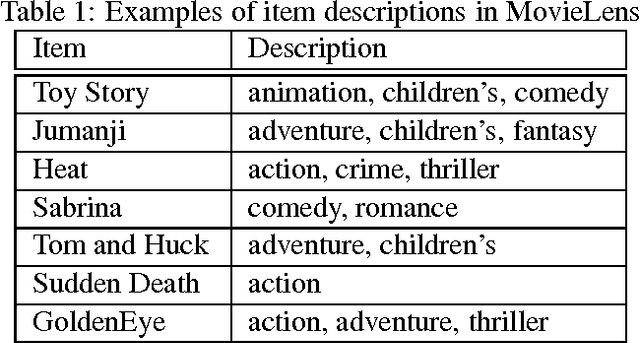
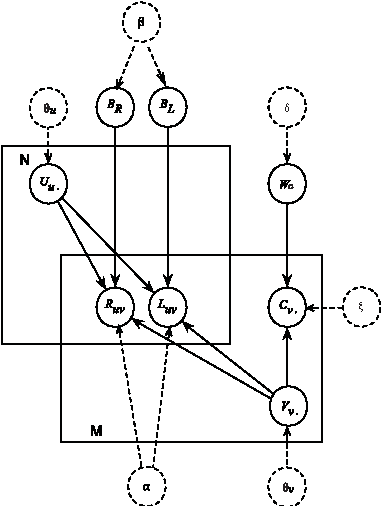
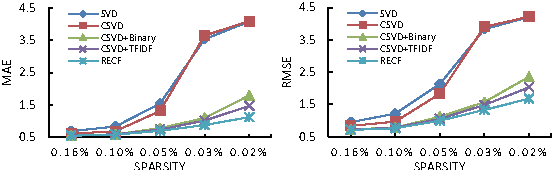
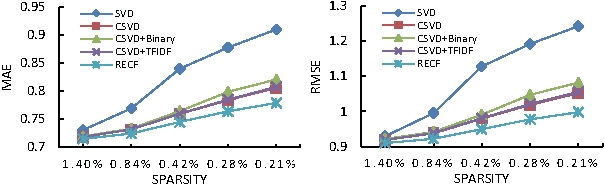
Collaborative filtering (CF) aims to build a model from users' past behaviors and/or similar decisions made by other users, and use the model to recommend items for users. Despite of the success of previous collaborative filtering approaches, they are all based on the assumption that there are sufficient rating scores available for building high-quality recommendation models. In real world applications, however, it is often difficult to collect sufficient rating scores, especially when new items are introduced into the system, which makes the recommendation task challenging. We find that there are often "short" texts describing features of items, based on which we can approximate the similarity of items and make recommendation together with rating scores. In this paper we "borrow" the idea of vector representation of words to capture the information of short texts and embed it into a matrix factorization framework. We empirically show that our approach is effective by comparing it with state-of-the-art approaches.
LTSG: Latent Topical Skip-Gram for Mutually Learning Topic Model and Vector Representations
Feb 23, 2017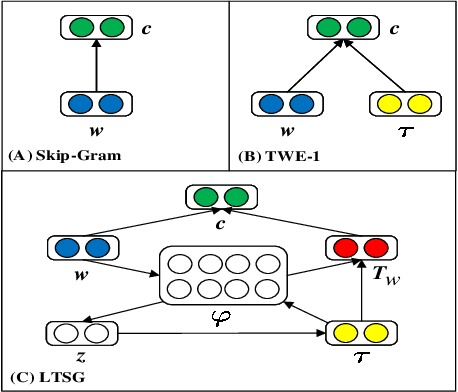

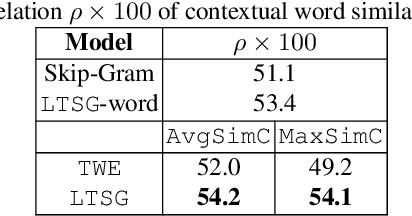
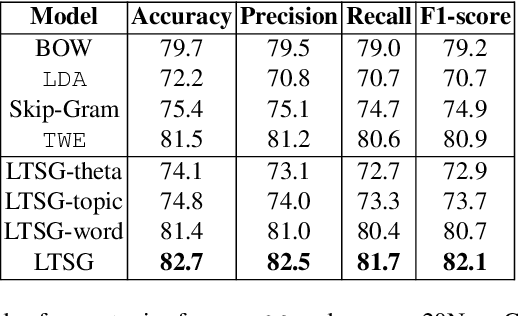
Topic models have been widely used in discovering latent topics which are shared across documents in text mining. Vector representations, word embeddings and topic embeddings, map words and topics into a low-dimensional and dense real-value vector space, which have obtained high performance in NLP tasks. However, most of the existing models assume the result trained by one of them are perfect correct and used as prior knowledge for improving the other model. Some other models use the information trained from external large corpus to help improving smaller corpus. In this paper, we aim to build such an algorithm framework that makes topic models and vector representations mutually improve each other within the same corpus. An EM-style algorithm framework is employed to iteratively optimize both topic model and vector representations. Experimental results show that our model outperforms state-of-art methods on various NLP tasks.