 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding up convolutional networks pruning with coarse ranking
Feb 18, 2019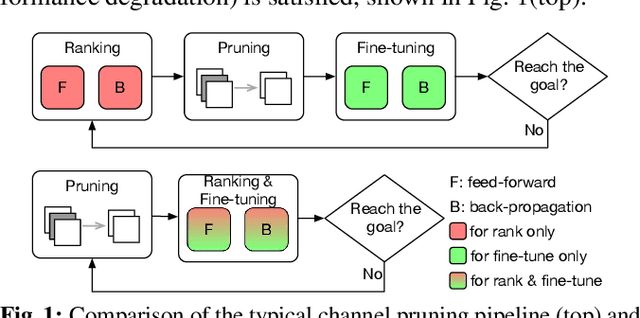
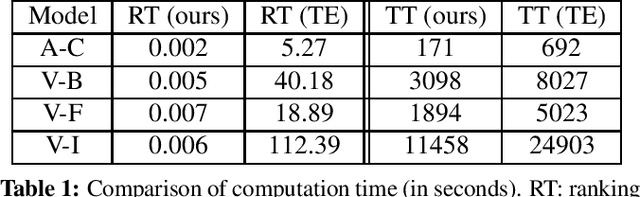
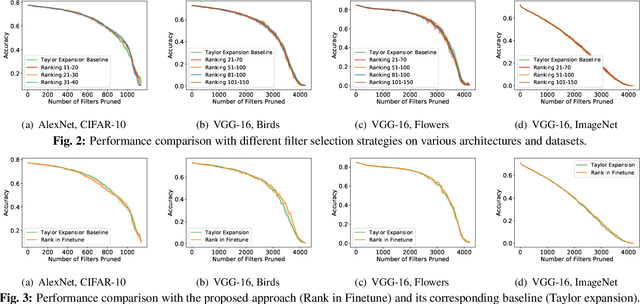
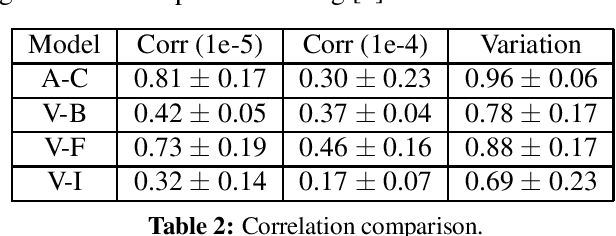
Channel-based pruning has achieved significant successes in accelerating deep convolutional neural network, whose pipeline is an iterative three-step procedure: ranking, pruning and fine-tuning. However, this iterative procedure is computationally expensive. In this study, we present a novel computationally efficient channel pruning approach based on the coarse ranking that utilizes the intermediate results during fine-tuning to rank the importance of filters, built upon state-of-the-art works with data-driven ranking criteria. The goal of this work is not to propose a single improved approach built upon a specific channel pruning method, but to introduce a new general framework that works for a series of channel pruning methods. Various benchmark image datasets (CIFAR-10, ImageNet, Birds-200, and Flowers-102) and network architectures (AlexNet and VGG-16) are utilized to evaluate the proposed approach for object classification purpose. Experimental results show that the proposed method can achieve almost identical performance with the corresponding state-of-the-art works (baseline) while our ranking time is negligibly short. In specific, with the proposed method, 75% and 54% of the total computation time for the whole pruning procedure can be reduced for AlexNet on CIFAR-10, and for VGG-16 on ImageNet, respectively. Our approach would significantly facilitate pruning practice, especially on resource-constrained platforms.
Single-shot Channel Pruning Based on Alternating Direction Method of Multipliers
Feb 18, 2019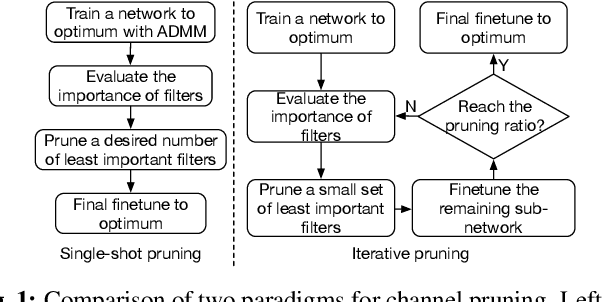
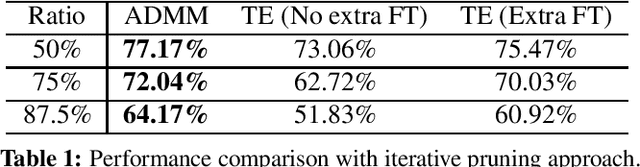
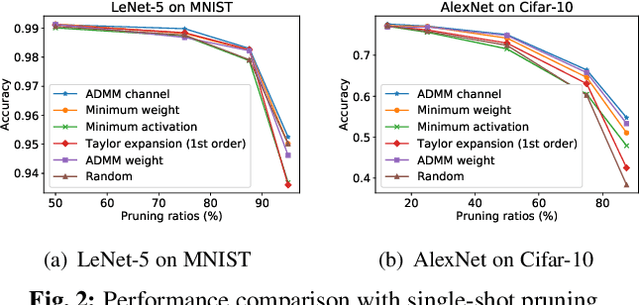
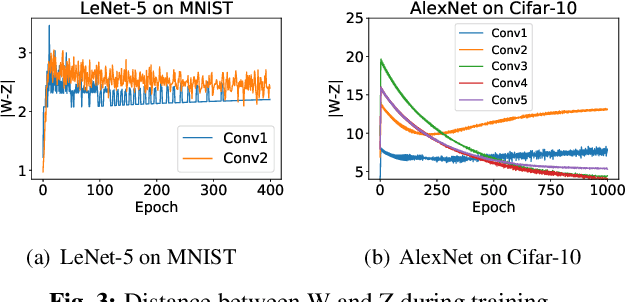
Channel pruning has been identified as an effective approach to constructing efficient network structures. Its typical pipeline requires iterative pruning and fine-tuning. In this work, we propose a novel single-shot channel pruning approach based on alternating direction methods of multipliers (ADMM), which can eliminate the need for complex iterative pruning and fine-tuning procedure and achieve a target compression ratio with only one run of pruning and fine-tuning. To the best of our knowledge, this is the first study of single-shot channel pruning. The proposed method introduces filter-level sparsity during training and can achieve competitive performance with a simple heuristic pruning criterion (L1-norm). Extensive evaluations have been conducted with various widely-used benchmark architectures and image datasets for object classification purpose. The experimental results on classification accuracy show that the proposed method can outperform state-of-the-art network pruning works under various scenarios.
Beyond Inferring Class Representatives: User-Level Privacy Leakage From Federated Learning
Dec 05, 2018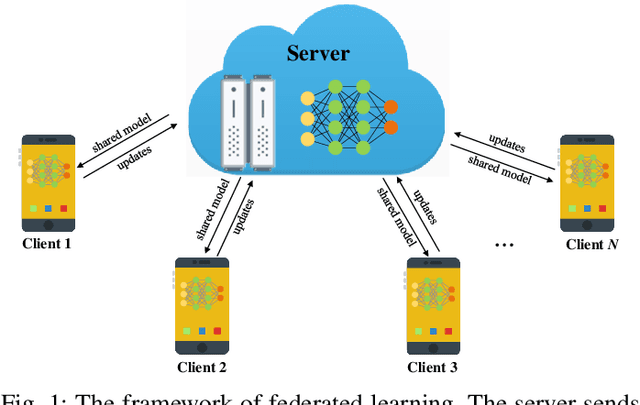
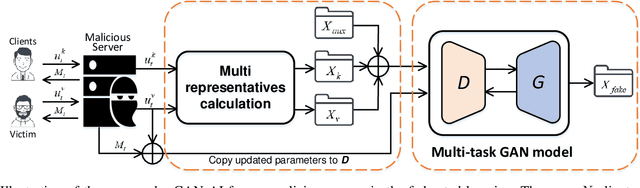
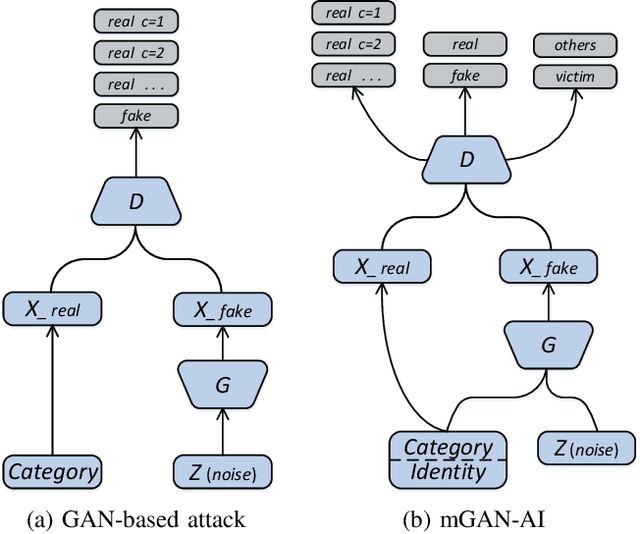

Federated learning, i.e., a mobile edge computing framework for deep learning, is a recent advance in privacy-preserving machine learning, where the model is trained in a decentralized manner by the clients, i.e., data curators, preventing the server from directly accessing those private data from the clients. This learning mechanism significantly challenges the attack from the server side. Although the state-of-the-art attacking techniques that incorporated the advance of Generative adversarial networks (GANs) could construct class representatives of the global data distribution among all clients, it is still challenging to distinguishably attack a specific client (i.e., user-level privacy leakage), which is a stronger privacy threat to precisely recover the private data from a specific client. This paper gives the first attempt to explore user-level privacy leakage against the federated learning by the attack from a malicious server. We propose a framework incorporating GAN with a multi-task discriminator, which simultaneously discriminates category, reality, and client identity of input samples. The novel discrimination on client identity enables the generator to recover user specified private data. Unlike existing works that tend to interfere the training process of the federated learning, the proposed method works "invisibly" on the server side. The experimental results demonstrate the effectiveness of the proposed attacking approach and the superior to the state-of-the-art.
Attention-based Few-Shot Person Re-identification Using Meta Learning
Oct 08, 2018
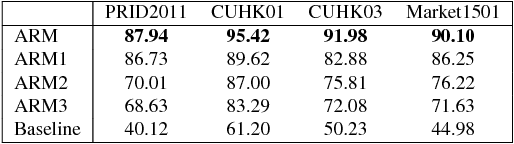
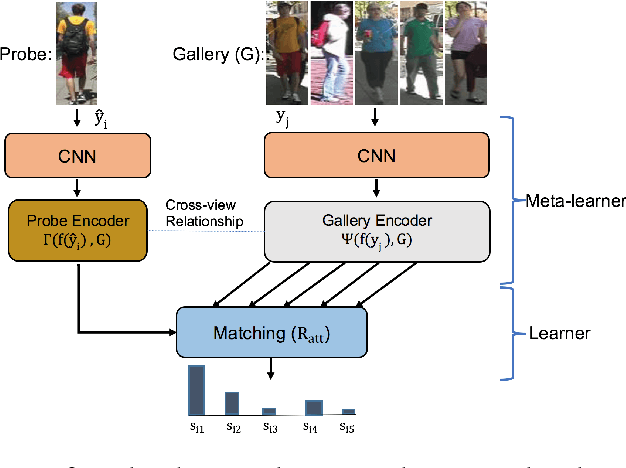
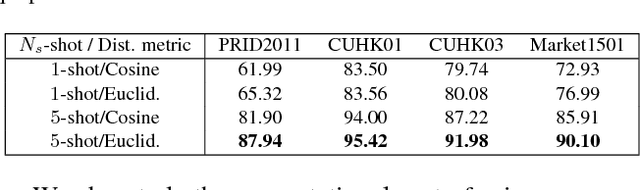
In this paper, we investigate the challenging task of person re-identification from a new perspective and propose an end-to-end attention-based architecture for few-shot re-identification through meta-learning. The motivation for this task lies in the fact that humans, can usually identify another person after just seeing that given person a few times (or even once) by attending to their memory. On the other hand, the unique nature of the person re-identification problem, i.e., only few examples exist per identity and new identities always appearing during testing, calls for a few shot learning architecture with the capacity of handling new identities. Hence, we frame the problem within a meta-learning setting, where a neural network based meta-learner is trained to optimize a learner i.e., an attention-based matching function. Another challenge of the person re-identification problem is the small inter-class difference between different identities and large intra-class difference of the same identity. In order to increase the discriminative power of the model, we propose a new attention-based feature encoding scheme that takes into account the critical intra-view and cross-view relationship of images. We refer to the proposed Attention-based Re-identification Metalearning model as ARM. Extensive evaluations demonstrate the advantages of the ARM as compared to the state-of-the-art on the challenging PRID2011, CUHK01, CUHK03 and Market1501 datasets.
Unsupervised Sparse Dirichlet-Net for Hyperspectral Image Super-Resolution
Jul 15, 2018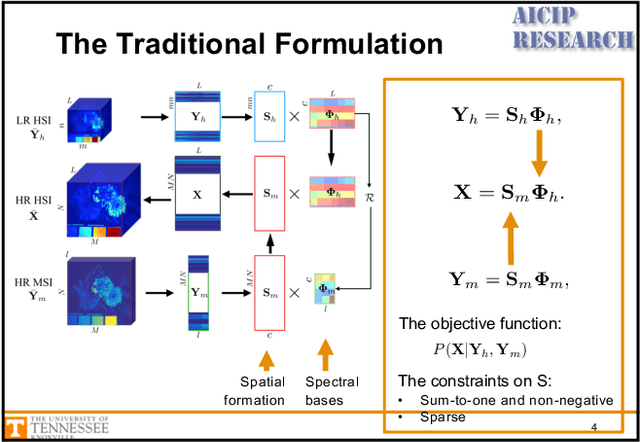
In many computer vision applications, obtaining images of high resolution in both the spatial and spectral domains are equally important. However, due to hardware limitations, one can only expect to acquire images of high resolution in either the spatial or spectral domains. This paper focuses on hyperspectral image super-resolution (HSI-SR), where a hyperspectral image (HSI) with low spatial resolution (LR) but high spectral resolution is fused with a multispectral image (MSI) with high spatial resolution (HR) but low spectral resolution to obtain HR HSI. Existing deep learning-based solutions are all supervised that would need a large training set and the availability of HR HSI, which is unrealistic. Here, we make the first attempt to solving the HSI-SR problem using an unsupervised encoder-decoder architecture that carries the following uniquenesses. First, it is composed of two encoder-decoder networks, coupled through a shared decoder, in order to preserve the rich spectral information from the HSI network. Second, the network encourages the representations from both modalities to follow a sparse Dirichlet distribution which naturally incorporates the two physical constraints of HSI and MSI. Third, the angular difference between representations are minimized in order to reduce the spectral distortion. We refer to the proposed architecture as unsupervised Sparse Dirichlet-Net, or uSDN. Extensive experimental results demonstrate the superior performance of uSDN as compared to the state-of-the-art.
Person Re-identification Using Visual Attention
Jun 25, 2018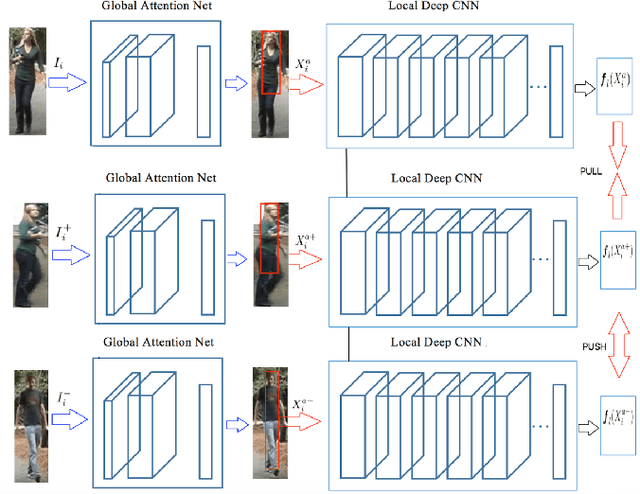
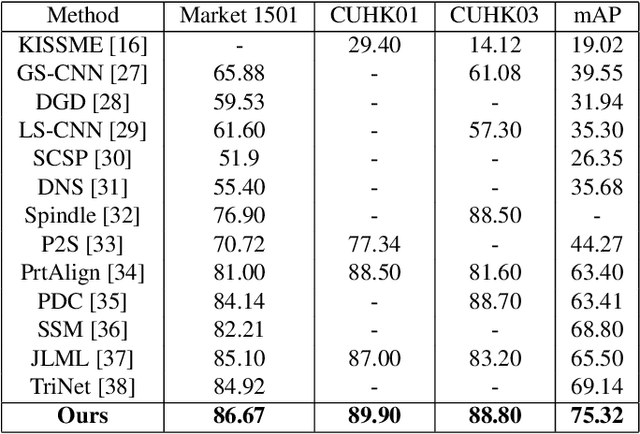

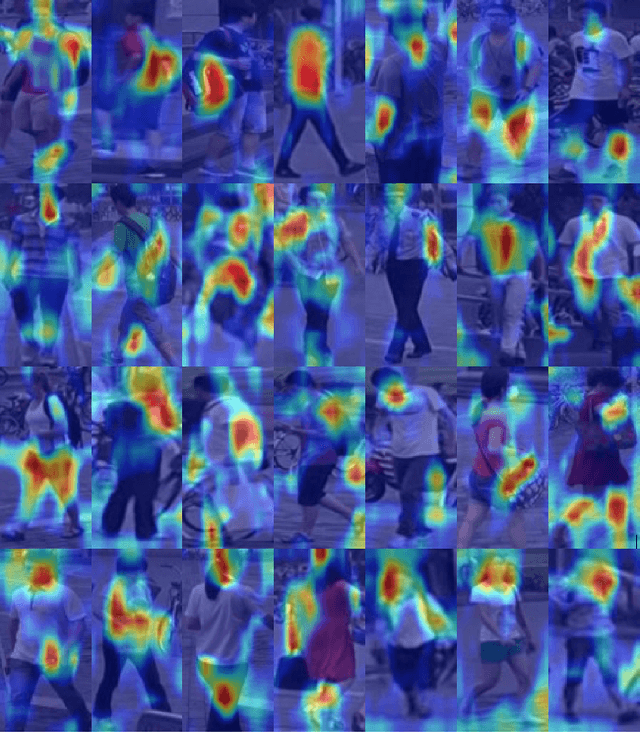
Despite recent attempts for solving the person re-identification problem, it remains a challenging task since a person's appearance can vary significantly when large variations in view angle, human pose and illumination are involved. The concept of attention is one of the most interesting recent architectural innovations in neural networks. Inspired by that, in this paper we propose a novel approach based on using a gradient-based attention mechanism in deep convolution neural network for solving the person re-identification problem. Our model learns to focus selectively on parts of the input image for which the networks' output is most sensitive to. Extensive comparative evaluations demonstrate that the proposed method outperforms state-of-the-art approaches, including both traditional and deep neural network-based methods on the challenging CUHK01, CUHK03, and Market1501 datasets.
Talking Face Generation by Conditional Recurrent Adversarial Network
May 05, 2018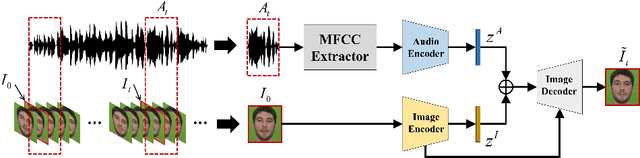
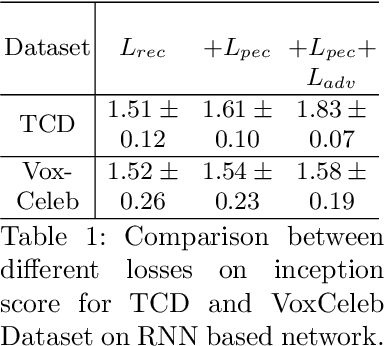
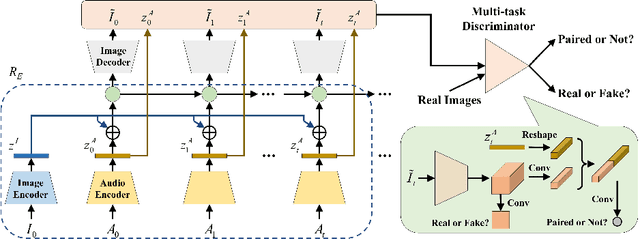

Given an arbitrary face image and an arbitrary speech clip, the proposed work attempts to generating the talking face video with accurate lip synchronization while maintaining smooth transition of both lip and facial movement over the entire video clip. Existing works either do not consider temporal dependency on face images across different video frames thus easily yielding noticeable/abrupt facial and lip movement or are only limited to the generation of talking face video for a specific person thus lacking generalization capacity. We propose a novel conditional video generation network where the audio input is treated as a condition for the recurrent adversarial network such that temporal dependency is incorporated to realize smooth transition for the lip and facial movement. In addition, we deploy a multi-task adversarial training scheme in the context of video generation to improve both photo-realism and the accuracy for lip synchronization. Finally, based on the phoneme distribution information extracted from the audio clip, we develop a sample selection method that effectively reduces the size of the training dataset without sacrificing the quality of the generated video. Extensive experiments on both controlled and uncontrolled datasets demonstrate the superiority of the proposed approach in terms of visual quality, lip sync accuracy, and smooth transition of lip and facial movement, as compared to the state-of-the-art.
Fast-converging Conditional Generative Adversarial Networks for Image Synthesis
May 05, 2018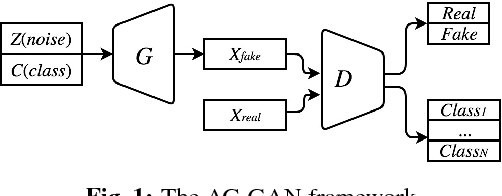
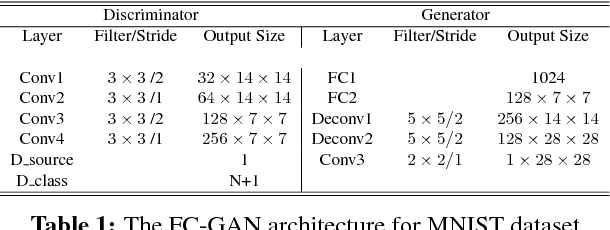
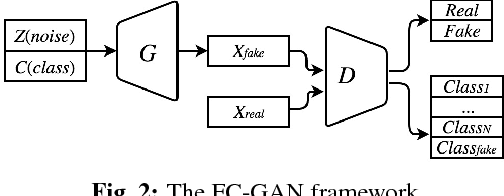

Building on top of the success of generative adversarial networks (GANs), conditional GANs attempt to better direct the data generation process by conditioning with certain additional information. Inspired by the most recent AC-GAN, in this paper we propose a fast-converging conditional GAN (FC-GAN). In addition to the real/fake classifier used in vanilla GANs, our discriminator has an advanced auxiliary classifier which distinguishes each real class from an extra `fake' class. The `fake' class avoids mixing generated data with real data, which can potentially confuse the classification of real data as AC-GAN does, and makes the advanced auxiliary classifier behave as another real/fake classifier. As a result, FC-GAN can accelerate the process of differentiation of all classes, thus boost the convergence speed. Experimental results on image synthesis demonstrate our model is competitive in the quality of images generated while achieving a faster convergence rate.
Reference-Conditioned Super-Resolution by Neural Texture Transfer
Apr 10, 2018
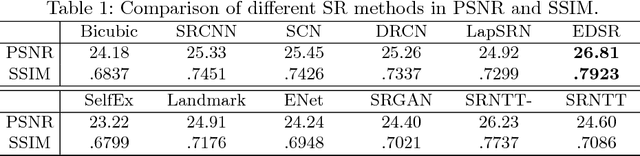
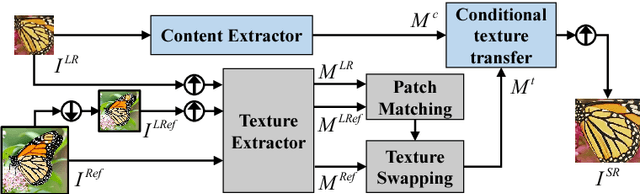
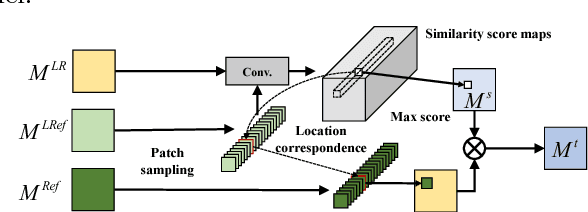
With the recent advancement in deep learning, we have witnessed a great progress in single image super-resolution. However, due to the significant information loss of the image downscaling process, it has become extremely challenging to further advance the state-of-the-art, especially for large upscaling factors. This paper explores a new research direction in super resolution, called reference-conditioned super-resolution, in which a reference image containing desired high-resolution texture details is provided besides the low-resolution image. We focus on transferring the high-resolution texture from reference images to the super-resolution process without the constraint of content similarity between reference and target images, which is a key difference from previous example-based methods. Inspired by recent work on image stylization, we address the problem via neural texture transfer. We design an end-to-end trainable deep model which generates detail enriched results by adaptively fusing the content from the low-resolution image with the texture patterns from the reference image. We create a benchmark dataset for the general research of reference-based super-resolution, which contains reference images paired with low-resolution inputs with varying degrees of similarity. Both objective and subjective evaluations demonstrate the great potential of using reference images as well as the superiority of our results over other state-of-the-art methods.
Discriminative Cross-View Binary Representation Learning
Apr 04, 2018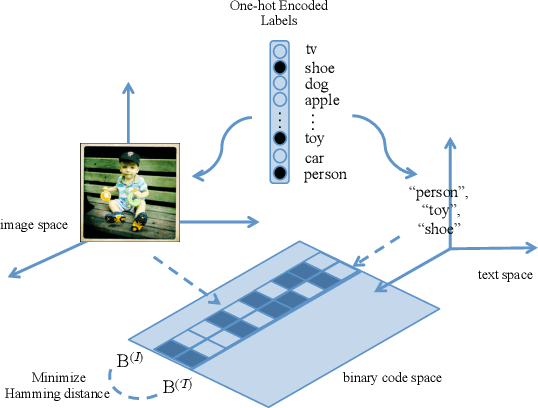
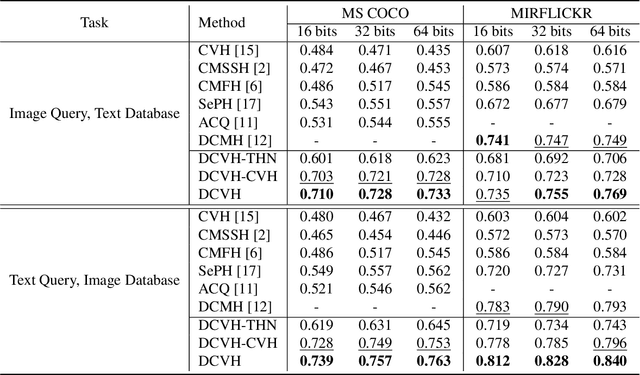
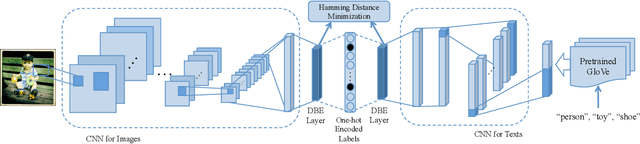
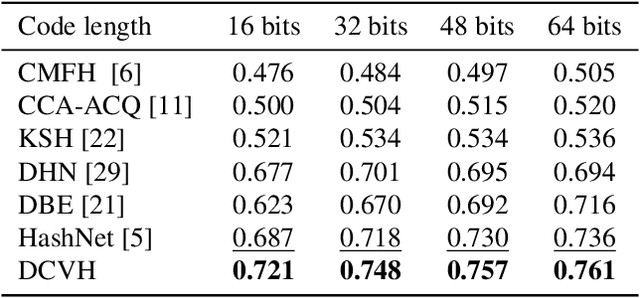
Learning compact representation is vital and challenging for large scale multimedia data. Cross-view/cross-modal hashing for effective binary representation learning has received significant attention with exponentially growing availability of multimedia content. Most existing cross-view hashing algorithms emphasize the similarities in individual views, which are then connected via cross-view similarities. In this work, we focus on the exploitation of the discriminative information from different views, and propose an end-to-end method to learn semantic-preserving and discriminative binary representation, dubbed Discriminative Cross-View Hashing (DCVH), in light of learning multitasking binary representation for various tasks including cross-view retrieval, image-to-image retrieval, and image annotation/tagging. The proposed DCVH has the following key components. First, it uses convolutional neural network (CNN) based nonlinear hashing functions and multilabel classification for both images and texts simultaneously. Such hashing functions achieve effective continuous relaxation during training without explicit quantization loss by using Direct Binary Embedding (DBE) layers. Second, we propose an effective view alignment via Hamming distance minimization, which is efficiently accomplished by bit-wise XOR operation. Extensive experiments on two image-text benchmark datasets demonstrate that DCVH outperforms state-of-the-art cross-view hashing algorithms as well as single-view image hashing algorithms. In addition, DCVH can provide competitive performance for image annotation/tagging.
* Published in WACV2018. Code will be available soon