 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically-Constrained Transfer Learning through Shared Abundance Space for Hyperspectral Image Classification
Aug 30, 2020

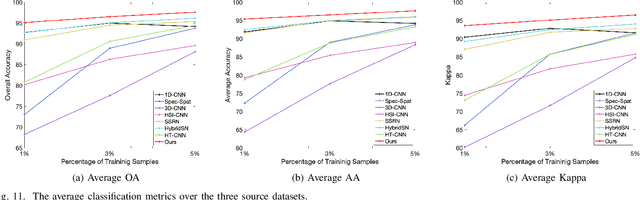
Hyperspectral image (HSI) classification is one of the most active research topics and has achieved promising results boosted by the recent development of deep learning. However, most state-of-the-art approaches tend to perform poorly when the training and testing images are on different domains, e.g., source domain and target domain, respectively, due to the spectral variability caused by different acquisition conditions. Transfer learning-based methods address this problem by pre-training in the source domain and fine-tuning on the target domain. Nonetheless, a considerable amount of data on the target domain has to be labeled and non-negligible computational resources are required to retrain the whole network. In this paper, we propose a new transfer learning scheme to bridge the gap between the source and target domains by projecting the HSI data from the source and target domains into a shared abundance space based on their own physical characteristics. In this way, the domain discrepancy would be largely reduced such that the model trained on the source domain could be applied on the target domain without extra efforts for data labeling or network retraining. The proposed method is referred to as physically-constrained transfer learning through shared abundance space (PCTL-SAS). Extensive experimental results demonstrate the superiority of the proposed method as compared to the state-of-the-art. The success of this endeavor would largely facilitate the deployment of HSI classification for real-world sensing scenarios.
Representative-Discriminative Learning for Open-set Land Cover Classification of Satellite Imagery
Jul 21, 2020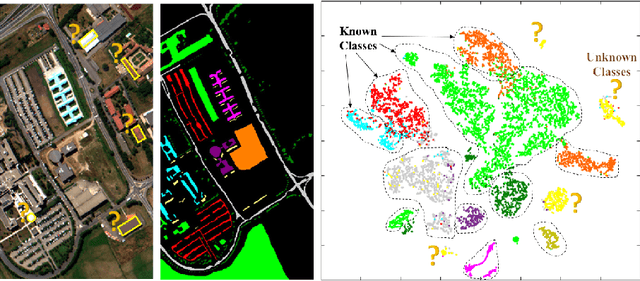

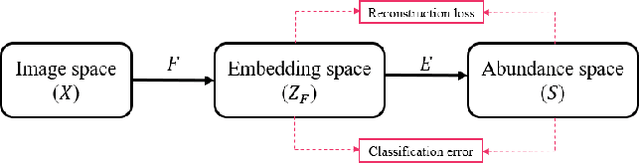
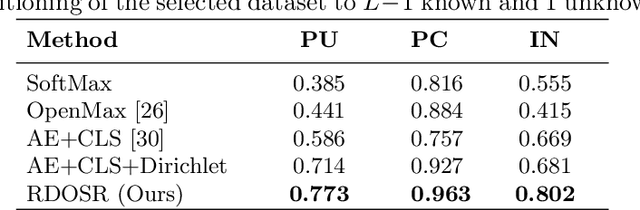
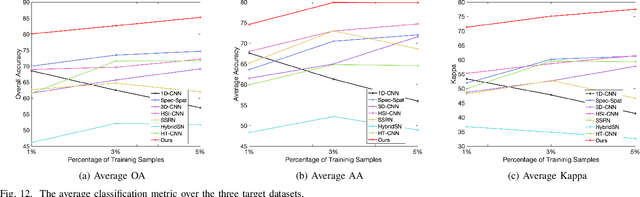
Land cover classification of satellite imagery is an important step toward analyzing the Earth's surface. Existing models assume a closed-set setting where both the training and testing classes belong to the same label set. However, due to the unique characteristics of satellite imagery with an extremely vast area of versatile cover materials, the training data are bound to be non-representative. In this paper, we study the problem of open-set land cover classification that identifies the samples belonging to unknown classes during testing, while maintaining performance on known classes. Although inherently a classification problem, both representative and discriminative aspects of data need to be exploited in order to better distinguish unknown classes from known. We propose a representative-discriminative open-set recognition (RDOSR) framework, which 1) projects data from the raw image space to the embedding feature space that facilitates differentiating similar classes, and further 2) enhances both the representative and discriminative capacity through transformation to a so-called abundance space. Experiments on multiple satellite benchmarks demonstrate the effectiveness of the proposed method. We also show the generality of the proposed approach by achieving promising results on open-set classification tasks using RGB images.
Unsupervised Pansharpening Based on Self-Attention Mechanism
Jun 16, 2020

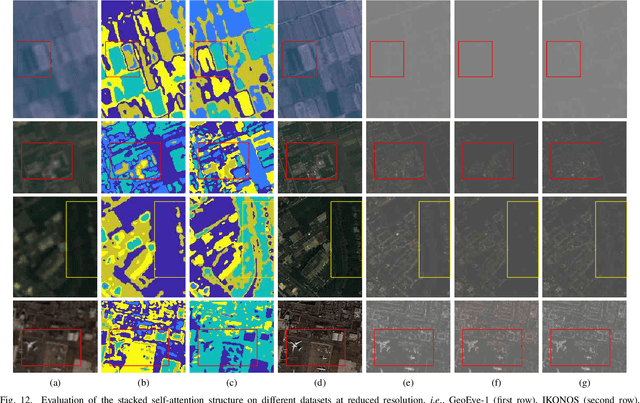

Pansharpening is to fuse a multispectral image (MSI) of low-spatial-resolution (LR) but rich spectral characteristics with a panchromatic image (PAN) of high-spatial-resolution (HR) but poor spectral characteristics. Traditional methods usually inject the extracted high-frequency details from PAN into the up-sampled MSI. Recent deep learning endeavors are mostly supervised assuming the HR MSI is available, which is unrealistic especially for satellite images. Nonetheless, these methods could not fully exploit the rich spectral characteristics in the MSI. Due to the wide existence of mixed pixels in satellite images where each pixel tends to cover more than one constituent material, pansharpening at the subpixel level becomes essential. In this paper, we propose an unsupervised pansharpening (UP) method in a deep-learning framework to address the above challenges based on the self-attention mechanism (SAM), referred to as UP-SAM. The contribution of this paper is three-fold. First, the self-attention mechanism is proposed where the spatial varying detail extraction and injection functions are estimated according to the attention representations indicating spectral characteristics of the MSI with sub-pixel accuracy. Second, such attention representations are derived from mixed pixels with the proposed stacked attention network powered with a stick-breaking structure to meet the physical constraints of mixed pixel formulations. Third, the detail extraction and injection functions are spatial varying based on the attention representations, which largely improves the reconstruction accuracy. Extensive experimental results demonstrate that the proposed approach is able to reconstruct sharper MSI of different types, with more details and less spectral distortion as compared to the state-of-the-art.
Context Aware Road-user Importance Estimation (iCARE)
Aug 30, 2019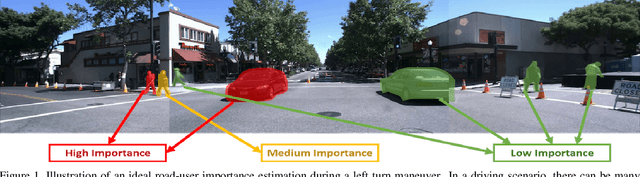
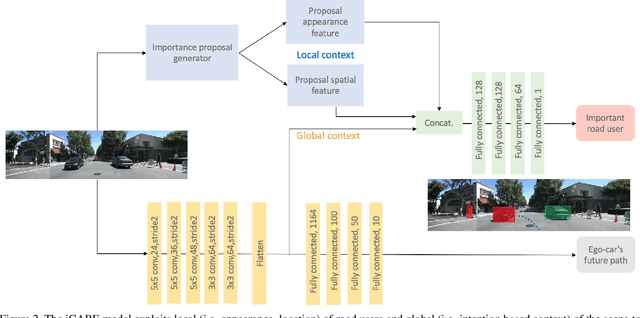

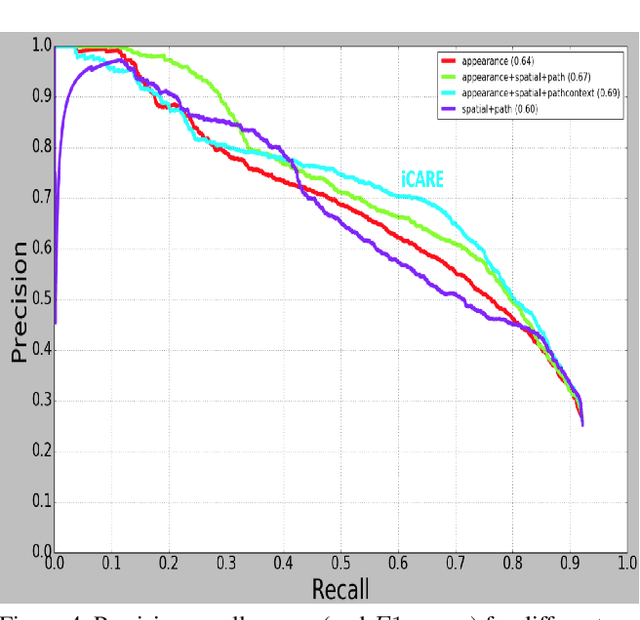
Road-users are a critical part of decision-making for both self-driving cars and driver assistance systems. Some road-users, however, are more important for decision-making than others because of their respective intentions, ego vehicle's intention and their effects on each other. In this paper, we propose a novel architecture for road-user importance estimation which takes advantage of the local and global context of the scene. For local context, the model exploits the appearance of the road users (which captures orientation, intention, etc.) and their location relative to ego-vehicle. The global context in our model is defined based on the feature map of the convolutional layer of the module which predicts the future path of the ego-vehicle and contains rich global information of the scene (e.g., infrastructure, road lanes, etc.), as well as the ego vehicle's intention information. Moreover, this paper introduces a new data set of real-world driving, concentrated around inter-sections and includes annotations of important road users. Systematic evaluations of our proposed method against several baselines show promising results.
advPattern: Physical-World Attacks on Deep Person Re-Identification via Adversarially Transformable Patterns
Aug 28, 2019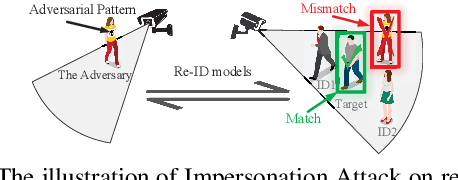
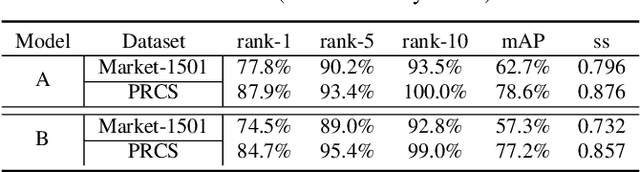

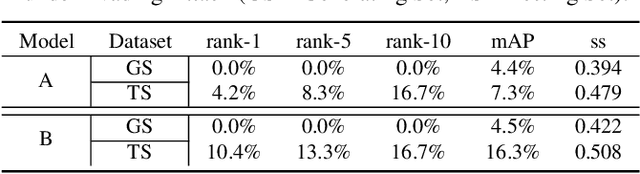
Person re-identification (re-ID) is the task of matching person images across camera views, which plays an important role in surveillance and security applications. Inspired by great progress of deep learning, deep re-ID models began to be popular and gained state-of-the-art performance. However, recent works found that deep neural networks (DNNs) are vulnerable to adversarial examples, posing potential threats to DNNs based applications. This phenomenon throws a serious question about whether deep re-ID based systems are vulnerable to adversarial attacks. In this paper, we take the first attempt to implement robust physical-world attacks against deep re-ID. We propose a novel attack algorithm, called advPattern, for generating adversarial patterns on clothes, which learns the variations of image pairs across cameras to pull closer the image features from the same camera, while pushing features from different cameras farther. By wearing our crafted "invisible cloak", an adversary can evade person search, or impersonate a target person to fool deep re-ID models in physical world. We evaluate the effectiveness of our transformable patterns on adversaries'clothes with Market1501 and our established PRCS dataset. The experimental results show that the rank-1 accuracy of re-ID models for matching the adversary decreases from 87.9% to 27.1% under Evading Attack. Furthermore, the adversary can impersonate a target person with 47.1% rank-1 accuracy and 67.9% mAP under Impersonation Attack. The results demonstrate that deep re-ID systems are vulnerable to our physical attacks.
One-Shot Mutual Affine-Transfer for Photorealistic Stylization
Jul 24, 2019

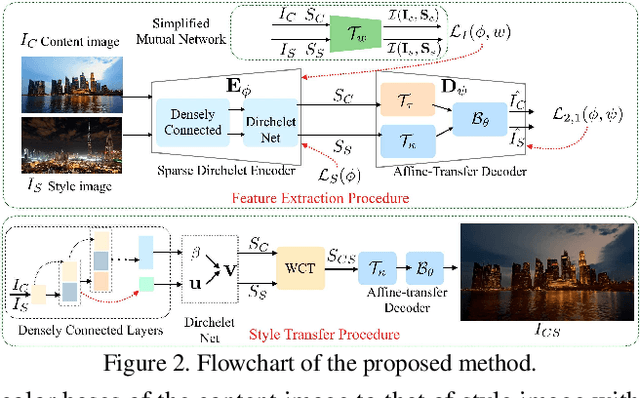
Photorealistic style transfer aims to transfer the style of a reference photo onto a content photo naturally, such that the stylized image looks like a real photo taken by a camera. Existing state-of-the-art methods are prone to spatial structure distortion of the content image and global color inconsistency across different semantic objects, making the results less photorealistic. In this paper, we propose a one-shot mutual Dirichlet network, to address these challenging issues. The essential contribution of the work is the realization of a representation scheme that successfully decouples the spatial structure and color information of images, such that the spatial structure can be well preserved during stylization. This representation is discriminative and context-sensitive with respect to semantic objects. It is extracted with a shared sparse Dirichlet encoder. Moreover, such representation is encouraged to be matched between the content and style images for faithful color transfer. The affine-transfer model is embedded in the decoder of the network to facilitate the color transfer. The strong representative and discriminative power of the proposed network enables one-shot learning given only one content-style image pair. Experimental results demonstrate that the proposed method is able to generate photorealistic photos without spatial distortion or abrupt color changes.
Investigating Channel Pruning through Structural Redundancy Reduction - A Statistical Study
May 19, 2019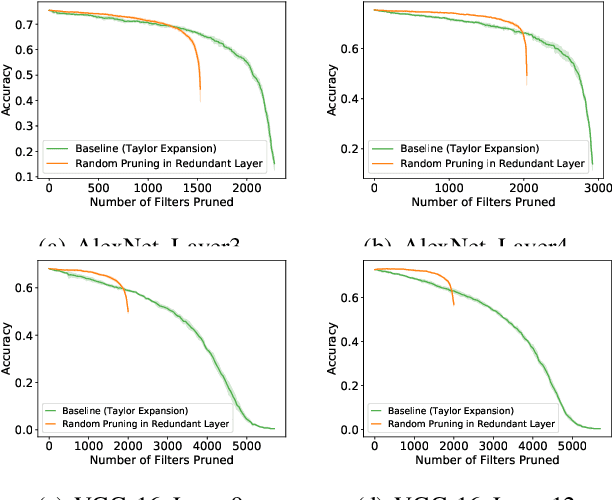
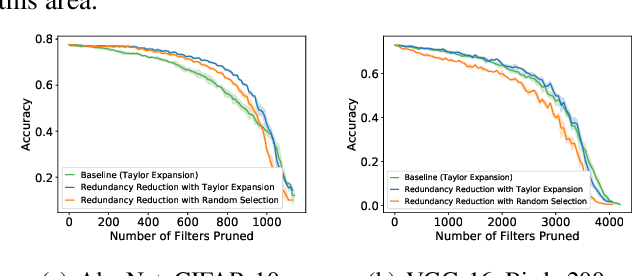
Most existing channel pruning methods formulate the pruning task from a perspective of inefficiency reduction which iteratively rank and remove the least important filters, or find the set of filters that minimizes some reconstruction errors after pruning. In this work, we investigate the channel pruning from a new perspective with statistical modeling. We hypothesize that the number of filters at a certain layer reflects the level of 'redundancy' in that layer and thus formulate the pruning problem from the aspect of redundancy reduction. Based on both theoretic analysis and empirical studies, we make an important discovery: randomly pruning filters from layers of high redundancy outperforms pruning the least important filters across all layers based on the state-of-the-art ranking criterion. These results advance our understanding of pruning and further testify to the recent findings that the structure of the pruned model plays a key role in the network efficiency as compared to inherited weights.
RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles
May 15, 2019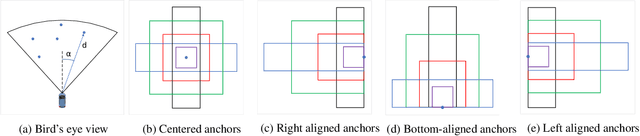

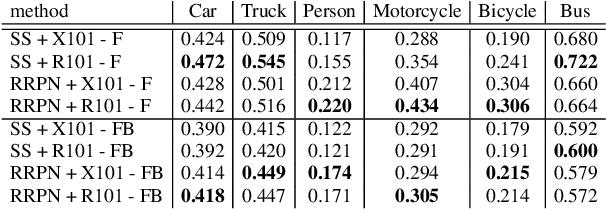
Region proposal algorithms play an important role in most state-of-the-art two-stage object detection networks by hypothesizing object locations in the image. Nonetheless, region proposal algorithms are known to be the bottleneck in most two-stage object detection networks, increasing the processing time for each image and resulting in slow networks not suitable for real-time applications such as autonomous driving vehicles. In this paper we introduce RRPN, a Radar-based real-time region proposal algorithm for object detection in autonomous driving vehicles. RRPN generates object proposals by mapping Radar detections to the image coordinate system and generating pre-defined anchor boxes for each mapped Radar detection point. These anchor boxes are then transformed and scaled based on the object's distance from the vehicle, to provide more accurate proposals for the detected objects. We evaluate our method on the newly released NuScenes dataset [1] using the Fast R-CNN object detection network [2]. Compared to the Selective Search object proposal algorithm [3], our model operates more than 100x faster while at the same time achieves higher detection precision and recall. Code has been made publicly available at https://github.com/mrnabati/RRPN .
Unsupervised and Unregistered Hyperspectral Image Super-Resolution with Mutual Dirichlet-Net
May 10, 2019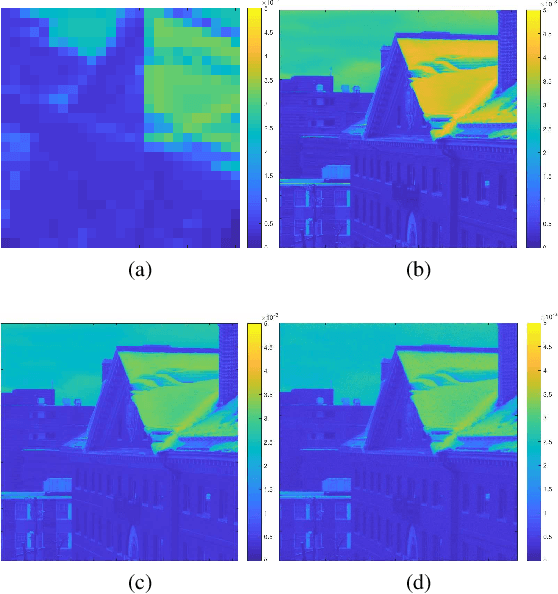


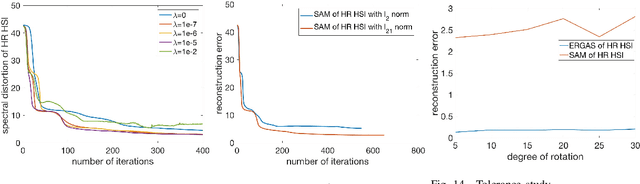
Hyperspectral images (HSI) provide rich spectral information that contributed to the successful performance improvement of numerous computer vision tasks. However, it can only be achieved at the expense of images' spatial resolution. Hyperspectral image super-resolution (HSI-SR) addresses this problem by fusing low resolution (LR) HSI with multispectral image (MSI) carrying much higher spatial resolution (HR). All existing HSI-SR approaches require the LR HSI and HR MSI to be well registered and the reconstruction accuracy of the HR HSI relies heavily on the registration accuracy of different modalities. This paper exploits the uncharted problem domain of HSI-SR without the requirement of multi-modality registration. Given the unregistered LR HSI and HR MSI with overlapped regions, we design a unique unsupervised learning structure linking the two unregistered modalities by projecting them into the same statistical space through the same encoder. The mutual information (MI) is further adopted to capture the non-linear statistical dependencies between the representations from two modalities (carrying spatial information) and their raw inputs. By maximizing the MI, spatial correlations between different modalities can be well characterized to further reduce the spectral distortion. A collaborative $l_{2,1}$ norm is employed as the reconstruction error instead of the more common $l_2$ norm, so that individual pixels can be recovered as accurately as possible. With this design, the network allows to extract correlated spectral and spatial information from unregistered images that better preserves the spectral information. The proposed method is referred to as unregistered and unsupervised mutual Dirichlet Net ($u^2$-MDN). Extensive experimental results using benchmark HSI datasets demonstrate the superior performance of $u^2$-MDN as compared to the state-of-the-art.
Image Super-Resolution by Neural Texture Transfer
Mar 06, 2019
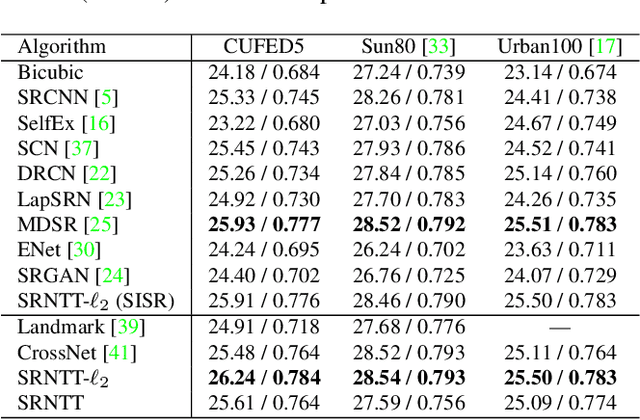
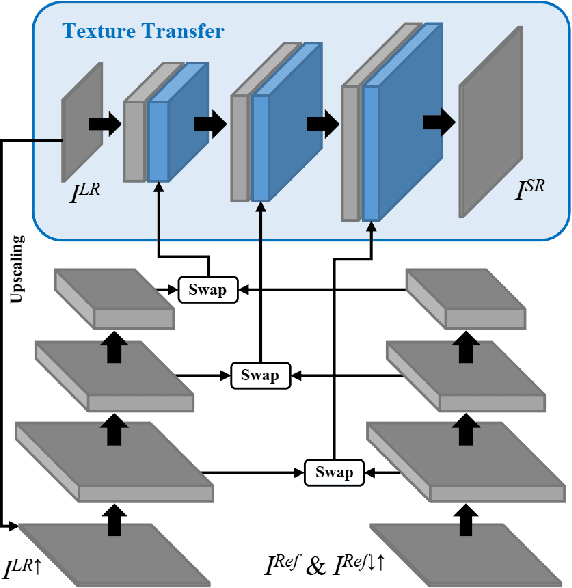

Due to the significant information loss in low-resolution (LR) images, it has become extremely challenging to further advance the state-of-the-art of single image super-resolution (SISR). Reference-based super-resolution (RefSR), on the other hand, has proven to be promising in recovering high-resolution (HR) details when a reference (Ref) image with similar content as that of the LR input is given. However, the quality of RefSR can degrade severely when Ref is less similar. This paper aims to unleash the potential of RefSR by leveraging more texture details from Ref images with stronger robustness even when irrelevant Ref images are provided. Inspired by the recent work on image stylization, we formulate the RefSR problem as neural texture transfer. We design an end-to-end deep model which enriches HR details by adaptively transferring the texture from Ref images according to their textural similarity. Instead of matching content in the raw pixel space as done by previous methods, our key contribution is a multi-level matching conducted in the neural space. This matching scheme facilitates multi-scale neural transfer that allows the model to benefit more from those semantically related Ref patches, and gracefully degrade to SISR performance on the least relevant Ref inputs. We build a benchmark dataset for the general research of RefSR, which contains Ref images paired with LR inputs with varying levels of similarity. Both quantitative and qualitative evaluations demonstrate the superiority of our method over state-of-the-art.