 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Data-aware Covariance Estimator from Compressed Data
Oct 10, 2020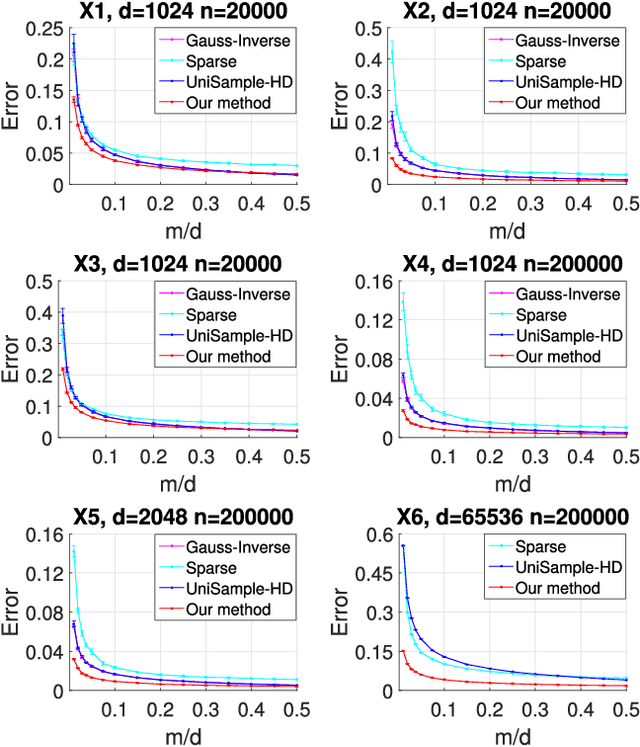
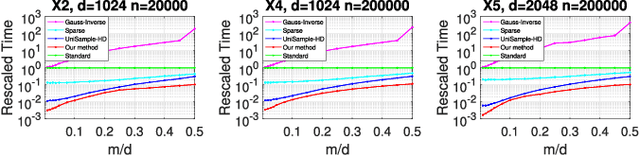
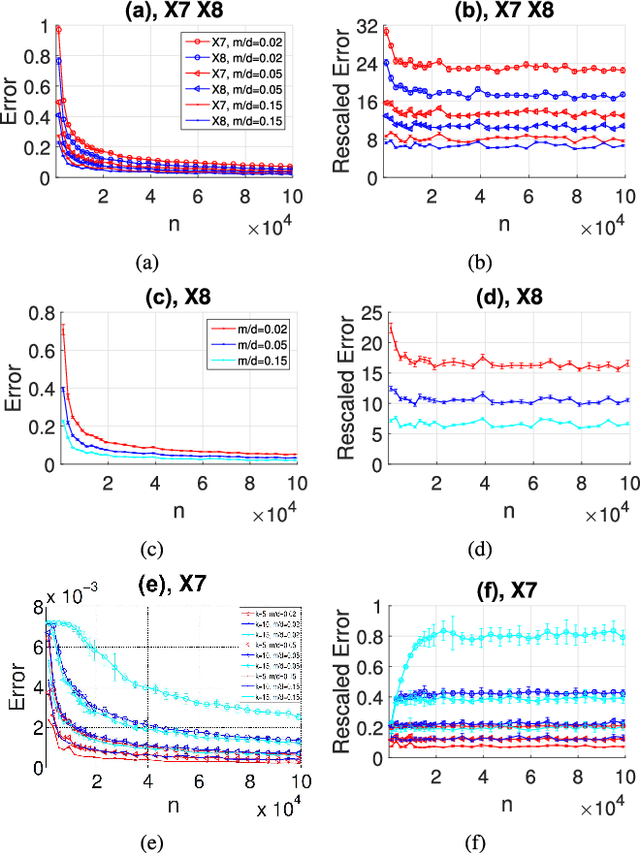
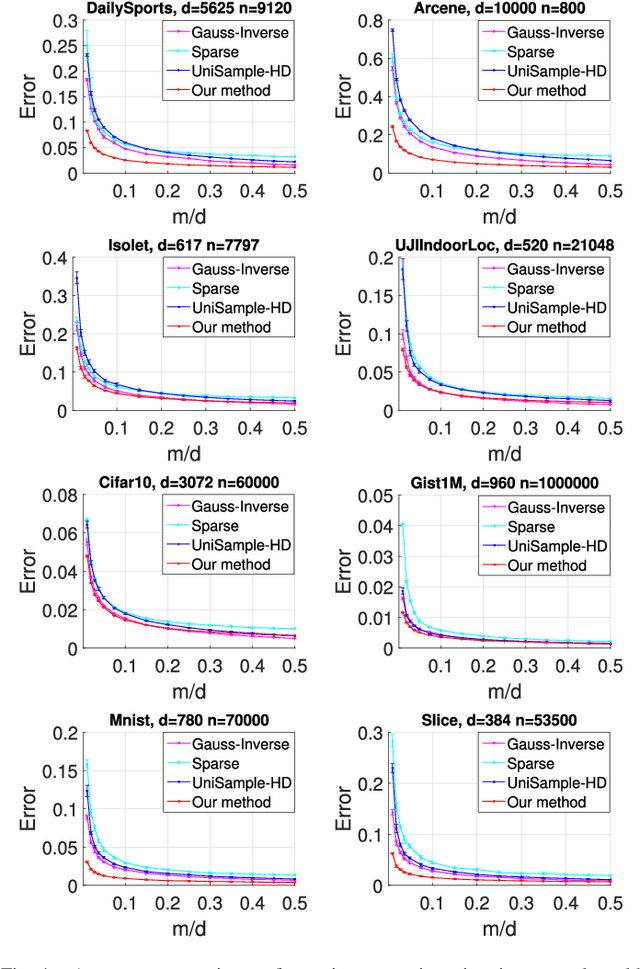
Estimating covariance matrix from massive high-dimensional and distributed data is significant for various real-world applications. In this paper, we propose a data-aware weighted sampling based covariance matrix estimator, namely DACE, which can provide an unbiased covariance matrix estimation and attain more accurate estimation under the same compression ratio. Moreover, we extend our proposed DACE to tackle multiclass classification problems with theoretical justification and conduct extensive experiments on both synthetic and real-world datasets to demonstrate the superior performance of our DACE.
* 12 pages, 5 figures
Block-term Tensor Neural Networks
Oct 10, 2020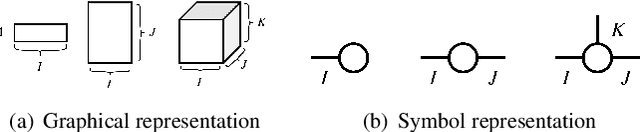

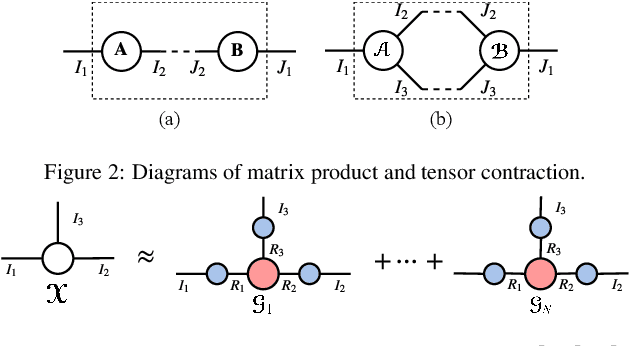
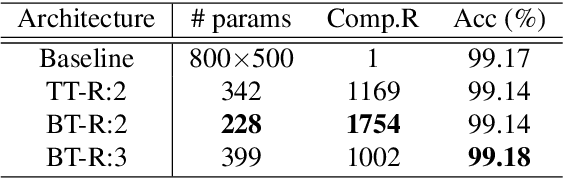
Deep neural networks (DNNs) have achieved outstanding performance in a wide range of applications, e.g., image classification, natural language processing, etc. Despite the good performance, the huge number of parameters in DNNs brings challenges to efficient training of DNNs and also their deployment in low-end devices with limited computing resources. In this paper, we explore the correlations in the weight matrices, and approximate the weight matrices with the low-rank block-term tensors. We name the new corresponding structure as block-term tensor layers (BT-layers), which can be easily adapted to neural network models, such as CNNs and RNNs. In particular, the inputs and the outputs in BT-layers are reshaped into low-dimensional high-order tensors with a similar or improved representation power. Sufficient experiments have demonstrated that BT-layers in CNNs and RNNs can achieve a very large compression ratio on the number of parameters while preserving or improving the representation power of the original DNNs.
* 12 pages, 15 figures
Making Online Sketching Hashing Even Faster
Oct 10, 2020
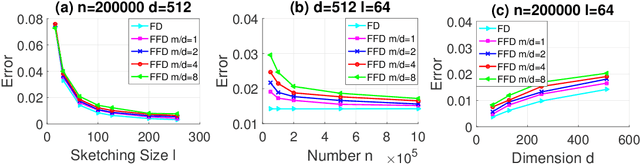
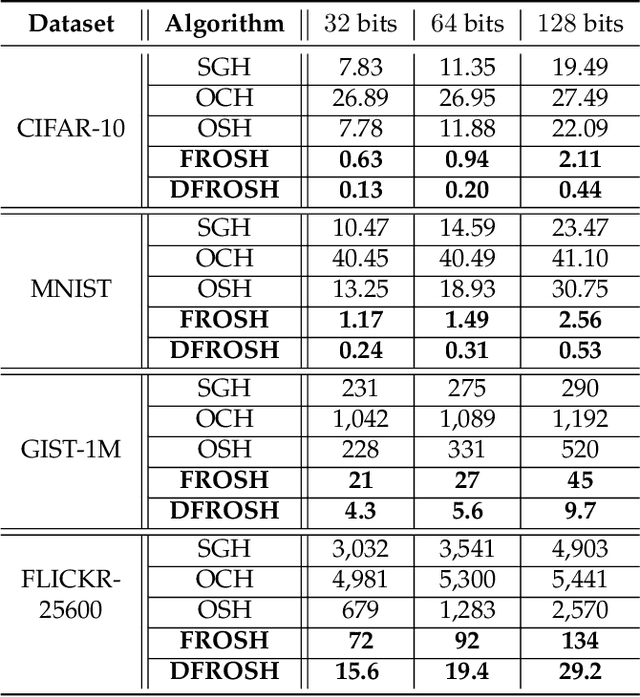
Data-dependent hashing methods have demonstrated good performance in various machine learning applications to learn a low-dimensional representation from the original data. However, they still suffer from several obstacles: First, most of existing hashing methods are trained in a batch mode, yielding inefficiency for training streaming data. Second, the computational cost and the memory consumption increase extraordinarily in the big data setting, which perplexes the training procedure. Third, the lack of labeled data hinders the improvement of the model performance. To address these difficulties, we utilize online sketching hashing (OSH) and present a FasteR Online Sketching Hashing (FROSH) algorithm to sketch the data in a more compact form via an independent transformation. We provide theoretical justification to guarantee that our proposed FROSH consumes less time and achieves a comparable sketching precision under the same memory cost of OSH. We also extend FROSH to its distributed implementation, namely DFROSH, to further reduce the training time cost of FROSH while deriving the theoretical bound of the sketching precision. Finally, we conduct extensive experiments on both synthetic and real datasets to demonstrate the attractive merits of FROSH and DFROSH.
* 12 pages, 5 figures
Hierarchical Context Enhanced Multi-Domain Dialogue System for Multi-domain Task Completion
Mar 03, 2020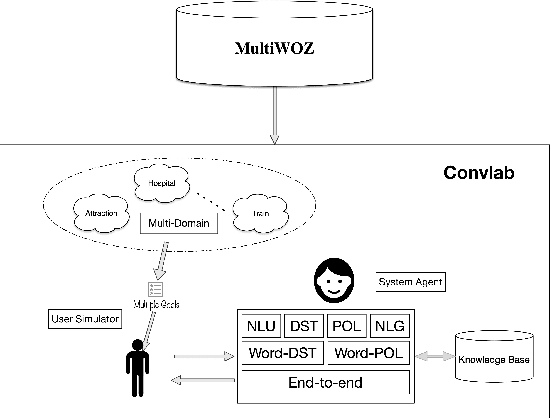
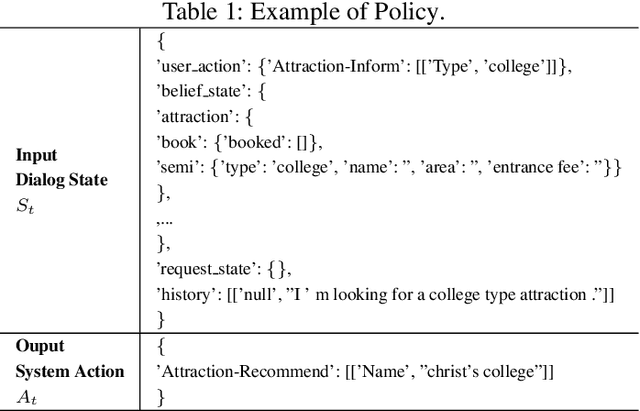
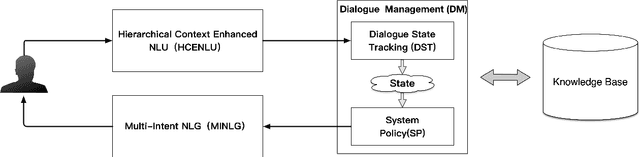
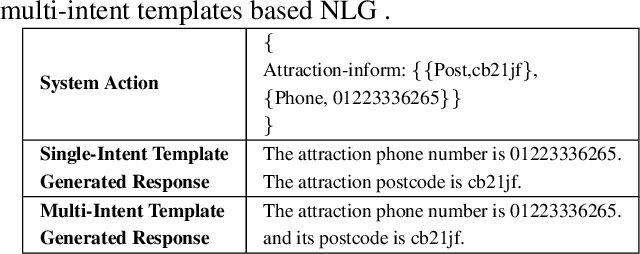
Task 1 of the DSTC8-track1 challenge aims to develop an end-to-end multi-domain dialogue system to accomplish complex users' goals under tourist information desk settings. This paper describes our submitted solution, Hierarchical Context Enhanced Dialogue System (HCEDS), for this task. The main motivation of our system is to comprehensively explore the potential of hierarchical context for sufficiently understanding complex dialogues. More specifically, we apply BERT to capture token-level information and employ the attention mechanism to capture sentence-level information. The results listed in the leaderboard show that our system achieves first place in automatic evaluation and the second place in human evaluation.
BERT Meets Chinese Word Segmentation
Sep 20, 2019
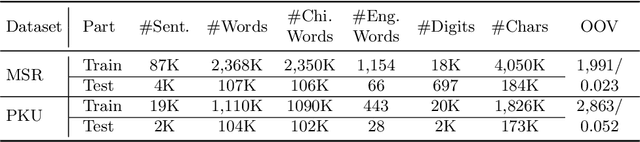
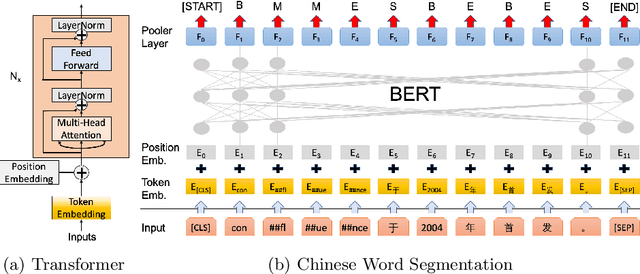
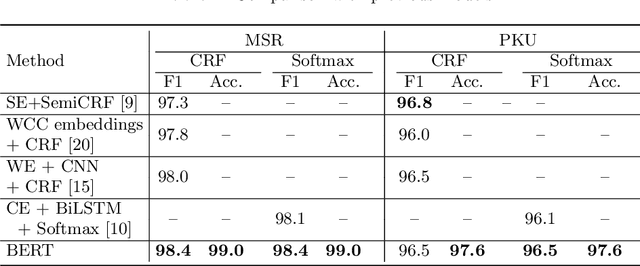
Chinese word segmentation (CWS) is a fundamental task for Chinese language understanding. Recently, neural network-based models have attained superior performance in solving the in-domain CWS task. Last year, Bidirectional Encoder Representation from Transformers (BERT), a new language representation model, has been proposed as a backbone model for many natural language tasks and redefined the corresponding performance. The excellent performance of BERT motivates us to apply it to solve the CWS task. By conducting intensive experiments in the benchmark datasets from the second International Chinese Word Segmentation Bake-off, we obtain several keen observations. BERT can slightly improve the performance even when the datasets contain the issue of labeling inconsistency. When applying sufficiently learned features, Softmax, a simpler classifier, can attain the same performance as that of a more complicated classifier, e.g., Conditional Random Field (CRF). The performance of BERT usually increases as the model size increases. The features extracted by BERT can be also applied as good candidates for other neural network models.
HiGRU: Hierarchical Gated Recurrent Units for Utterance-level Emotion Recognition
Apr 09, 2019

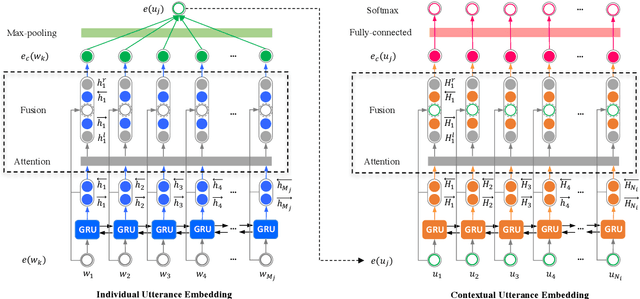
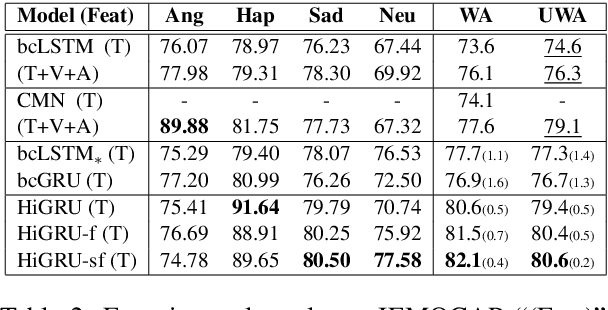
In this paper, we address three challenges in utterance-level emotion recognition in dialogue systems: (1) the same word can deliver different emotions in different contexts; (2) some emotions are rarely seen in general dialogues; (3) long-range contextual information is hard to be effectively captured. We therefore propose a hierarchical Gated Recurrent Unit (HiGRU) framework with a lower-level GRU to model the word-level inputs and an upper-level GRU to capture the contexts of utterance-level embeddings. Moreover, we promote the framework to two variants, HiGRU with individual features fusion (HiGRU-f) and HiGRU with self-attention and features fusion (HiGRU-sf), so that the word/utterance-level individual inputs and the long-range contextual information can be sufficiently utilized. Experiments on three dialogue emotion datasets, IEMOCAP, Friends, and EmotionPush demonstrate that our proposed HiGRU models attain at least 8.7%, 7.5%, 6.0% improvement over the state-of-the-art methods on each dataset, respectively. Particularly, by utilizing only the textual feature in IEMOCAP, our HiGRU models gain at least 3.8% improvement over the state-of-the-art conversational memory network (CMN) with the trimodal features of text, video, and audio.
BT-Nets: Simplifying Deep Neural Networks via Block Term Decomposition
Dec 15, 2017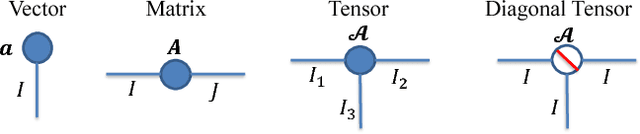
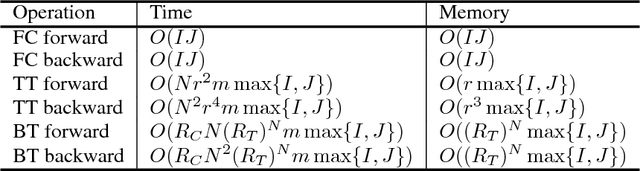
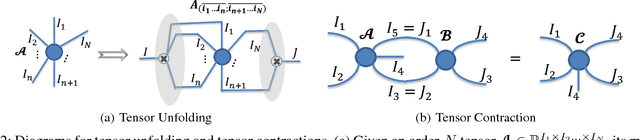

Recently, deep neural networks (DNNs) have been regarded as the state-of-the-art classification methods in a wide range of applications, especially in image classification. Despite the success, the huge number of parameters blocks its deployment to situations with light computing resources. Researchers resort to the redundancy in the weights of DNNs and attempt to find how fewer parameters can be chosen while preserving the accuracy at the same time. Although several promising results have been shown along this research line, most existing methods either fail to significantly compress a well-trained deep network or require a heavy fine-tuning process for the compressed network to regain the original performance. In this paper, we propose the \textit{Block Term} networks (BT-nets) in which the commonly used fully-connected layers (FC-layers) are replaced with block term layers (BT-layers). In BT-layers, the inputs and the outputs are reshaped into two low-dimensional high-order tensors, then block-term decomposition is applied as tensor operators to connect them. We conduct extensive experiments on benchmark datasets to demonstrate that BT-layers can achieve a very large compression ratio on the number of parameters while preserving the representation power of the original FC-layers as much as possible. Specifically, we can get a higher performance while requiring fewer parameters compared with the tensor train method.
A deep learning approach for predicting the quality of online health expert question-answering services
Dec 21, 2016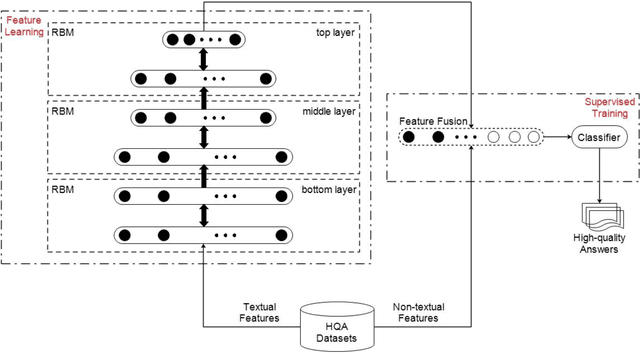
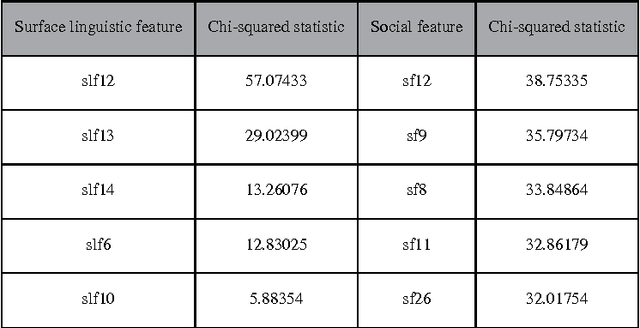
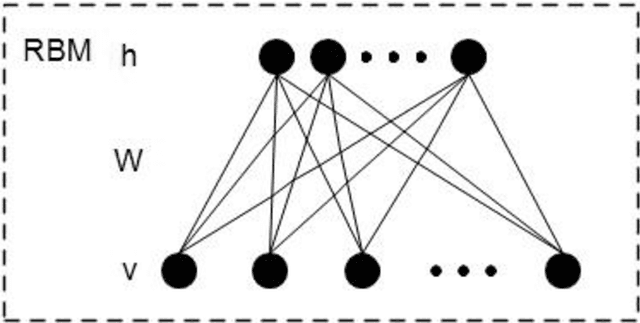
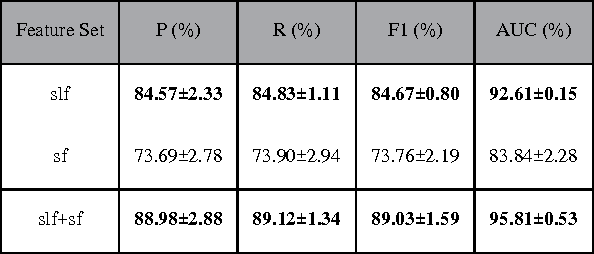
Currently, a growing number of health consumers are asking health-related questions online, at any time and from anywhere, which effectively lowers the cost of health care. The most common approach is using online health expert question-answering (HQA) services, as health consumers are more willing to trust answers from professional physicians. However, these answers can be of varying quality depending on circumstance. In addition, as the available HQA services grow, how to predict the answer quality of HQA services via machine learning becomes increasingly important and challenging. In an HQA service, answers are normally short texts, which are severely affected by the data sparsity problem. Furthermore, HQA services lack community features such as best answer and user votes. Therefore, the wisdom of the crowd is not available to rate answer quality. To address these problems, in this paper, the prediction of HQA answer quality is defined as a classification task. First, based on the characteristics of HQA services and feedback from medical experts, a standard for HQA service answer quality evaluation is defined. Next, based on the characteristics of HQA services, several novel non-textual features are proposed, including surface linguistic features and social features. Finally, a deep belief network (DBN)-based HQA answer quality prediction framework is proposed to predict the quality of answers by learning the high-level hidden semantic representation from the physicians' answers. Our results prove that the proposed framework overcomes the problem of overly sparse textual features in short text answers and effectively identifies high-quality answers.
Efficient Non-oblivious Randomized Reduction for Risk Minimization with Improved Excess Risk Guarantee
Dec 06, 2016
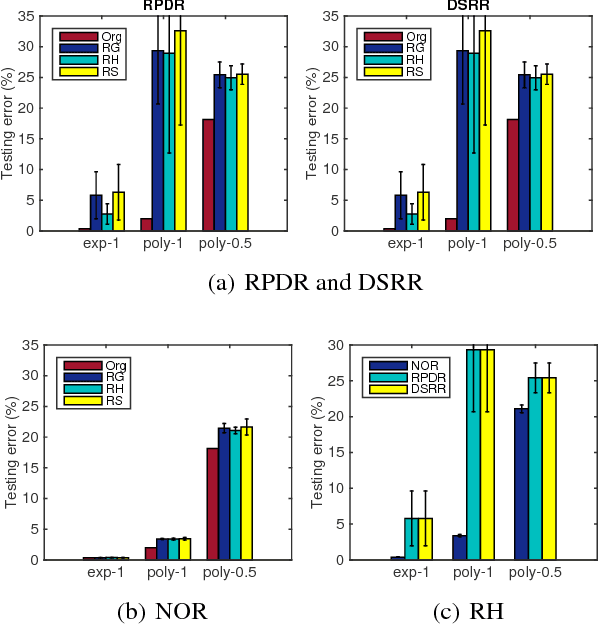
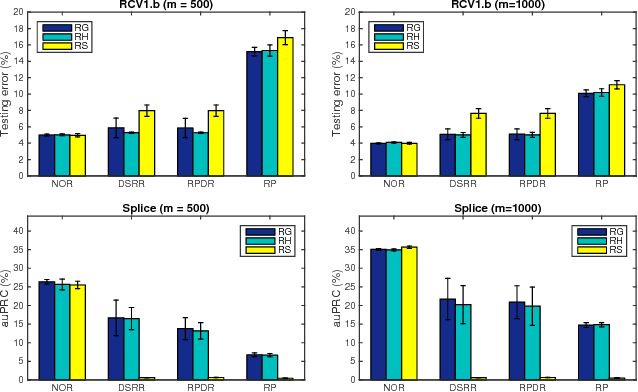
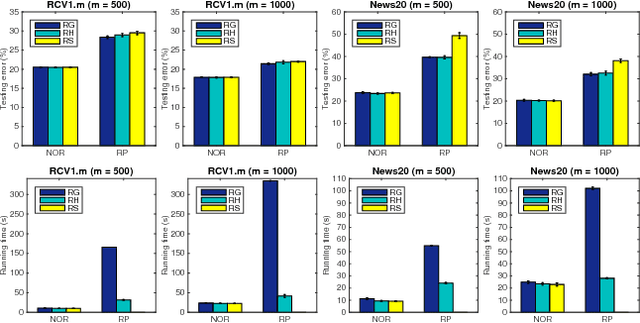
In this paper, we address learning problems for high dimensional data. Previously, oblivious random projection based approaches that project high dimensional features onto a random subspace have been used in practice for tackling high-dimensionality challenge in machine learning. Recently, various non-oblivious randomized reduction methods have been developed and deployed for solving many numerical problems such as matrix product approximation, low-rank matrix approximation, etc. However, they are less explored for the machine learning tasks, e.g., classification. More seriously, the theoretical analysis of excess risk bounds for risk minimization, an important measure of generalization performance, has not been established for non-oblivious randomized reduction methods. It therefore remains an open problem what is the benefit of using them over previous oblivious random projection based approaches. To tackle these challenges, we propose an algorithmic framework for employing non-oblivious randomized reduction method for general empirical risk minimizing in machine learning tasks, where the original high-dimensional features are projected onto a random subspace that is derived from the data with a small matrix approximation error. We then derive the first excess risk bound for the proposed non-oblivious randomized reduction approach without requiring strong assumptions on the training data. The established excess risk bound exhibits that the proposed approach provides much better generalization performance and it also sheds more insights about different randomized reduction approaches. Finally, we conduct extensive experiments on both synthetic and real-world benchmark datasets, whose dimension scales to $O(10^7)$, to demonstrate the efficacy of our proposed approach.
Response Aware Model-Based Collaborative Filtering
Oct 16, 2012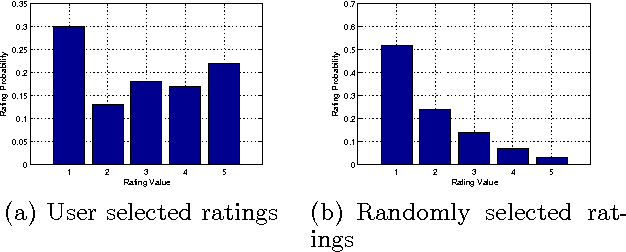
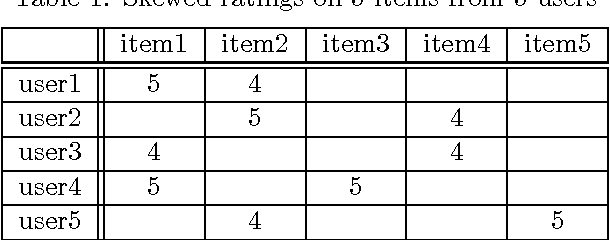

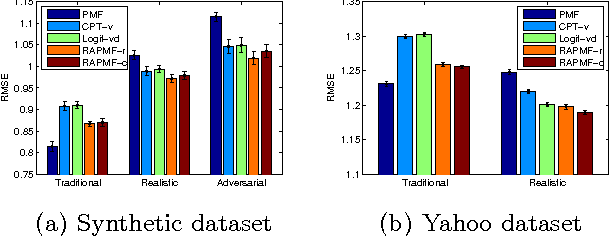
Previous work on recommender systems mainly focus on fitting the ratings provided by users. However, the response patterns, i.e., some items are rated while others not, are generally ignored. We argue that failing to observe such response patterns can lead to biased parameter estimation and sub-optimal model performance. Although several pieces of work have tried to model users' response patterns, they miss the effectiveness and interpretability of the successful matrix factorization collaborative filtering approaches. To bridge the gap, in this paper, we unify explicit response models and PMF to establish the Response Aware Probabilistic Matrix Factorization (RAPMF) framework. We show that RAPMF subsumes PMF as a special case. Empirically we demonstrate the merits of RAPMF from various aspects.