 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunicative Message Passing for Inductive Relation Reasoning
Dec 16, 2020



Relation prediction for knowledge graphs aims at predicting missing relationships between entities. Despite the importance of inductive relation prediction, most previous works are limited to a transductive setting and cannot process previously unseen entities. The recent proposed subgraph-based relation reasoning models provided alternatives to predict links from the subgraph structure surrounding a candidate triplet inductively. However, we observe that these methods often neglect the directed nature of the extracted subgraph and weaken the role of relation information in the subgraph modeling. As a result, they fail to effectively handle the asymmetric/anti-symmetric triplets and produce insufficient embeddings for the target triplets. To this end, we introduce a \textbf{C}\textbf{o}mmunicative \textbf{M}essage \textbf{P}assing neural network for \textbf{I}nductive re\textbf{L}ation r\textbf{E}asoning, \textbf{CoMPILE}, that reasons over local directed subgraph structures and has a vigorous inductive bias to process entity-independent semantic relations. In contrast to existing models, CoMPILE strengthens the message interactions between edges and entitles through a communicative kernel and enables a sufficient flow of relation information. Moreover, we demonstrate that CoMPILE can naturally handle asymmetric/anti-symmetric relations without the need for explosively increasing the number of model parameters by extracting the directed enclosing subgraphs. Extensive experiments show substantial performance gains in comparison to state-of-the-art methods on commonly used benchmark datasets with variant inductive settings.
Analyzing Unaligned Multimodal Sequence via Graph Convolution and Graph Pooling Fusion
Dec 02, 2020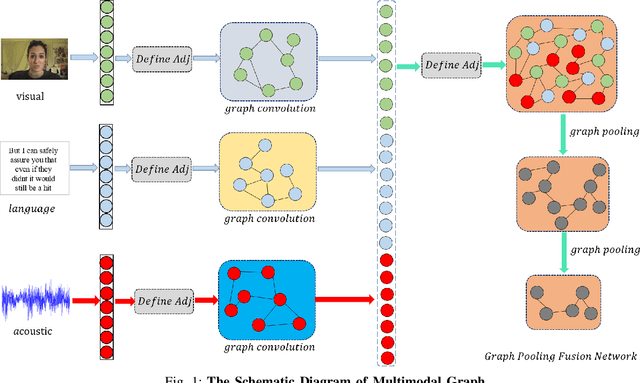

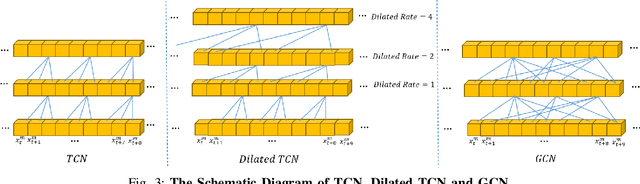
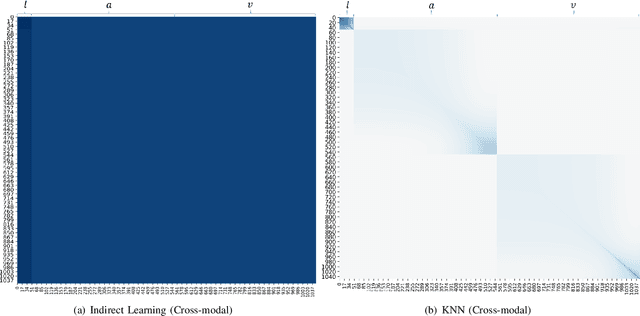
In this paper, we study the task of multimodal sequence analysis which aims to draw inferences from visual, language and acoustic sequences. A majority of existing works generally focus on aligned fusion, mostly at word level, of the three modalities to accomplish this task, which is impractical in real-world scenarios. To overcome this issue, we seek to address the task of multimodal sequence analysis on unaligned modality sequences which is still relatively underexplored and also more challenging. Recurrent neural network (RNN) and its variants are widely used in multimodal sequence analysis, but they are susceptible to the issues of gradient vanishing/explosion and high time complexity due to its recurrent nature. Therefore, we propose a novel model, termed Multimodal Graph, to investigate the effectiveness of graph neural networks (GNN) on modeling multimodal sequential data. The graph-based structure enables parallel computation in time dimension and can learn longer temporal dependency in long unaligned sequences. Specifically, our Multimodal Graph is hierarchically structured to cater to two stages, i.e., intra- and inter-modal dynamics learning. For the first stage, a graph convolutional network is employed for each modality to learn intra-modal dynamics. In the second stage, given that the multimodal sequences are unaligned, the commonly considered word-level fusion does not pertain. To this end, we devise a graph pooling fusion network to automatically learn the associations between various nodes from different modalities. Additionally, we define multiple ways to construct the adjacency matrix for sequential data. Experimental results suggest that our graph-based model reaches state-of-the-art performance on two benchmark datasets.
Universal Multi-Source Domain Adaptation
Nov 05, 2020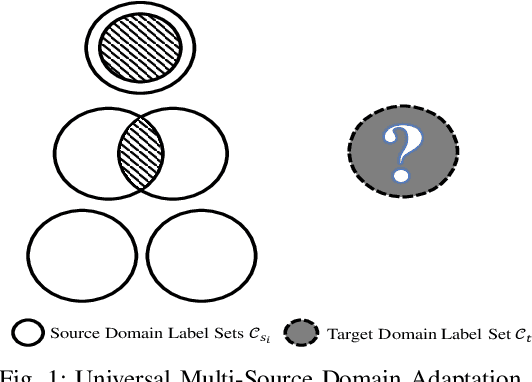
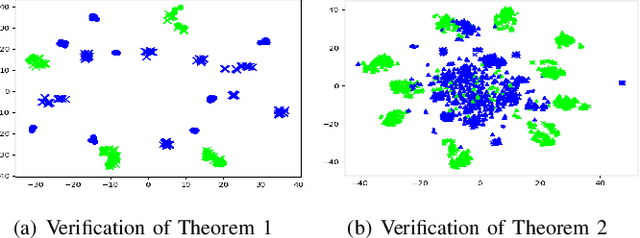
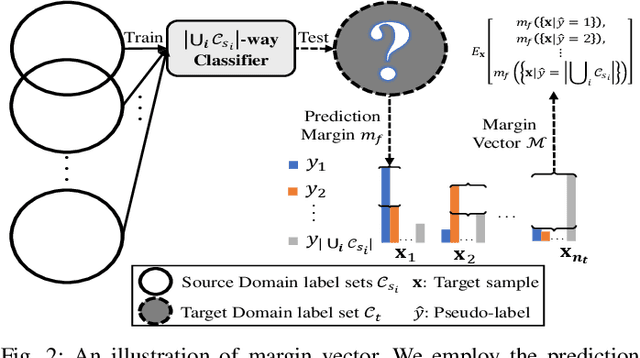
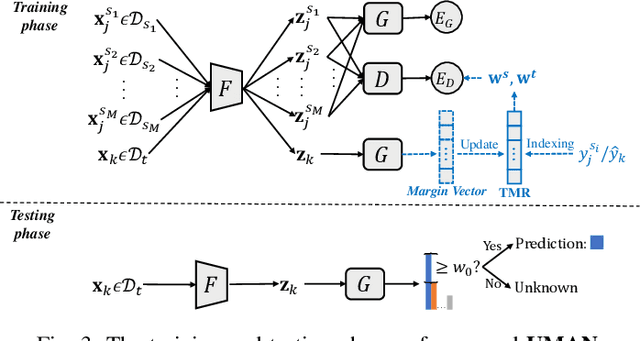
Unsupervised domain adaptation enables intelligent models to transfer knowledge from a labeled source domain to a similar but unlabeled target domain. Recent study reveals that knowledge can be transferred from one source domain to another unknown target domain, called Universal Domain Adaptation (UDA). However, in the real-world application, there are often more than one source domain to be exploited for domain adaptation. In this paper, we formally propose a more general domain adaptation setting, universal multi-source domain adaptation (UMDA), where the label sets of multiple source domains can be different and the label set of target domain is completely unknown. The main challenges in UMDA are to identify the common label set between each source domain and target domain, and to keep the model scalable as the number of source domains increases. To address these challenges, we propose a universal multi-source adaptation network (UMAN) to solve the domain adaptation problem without increasing the complexity of the model in various UMDA settings. In UMAN, we estimate the reliability of each known class in the common label set via the prediction margin, which helps adversarial training to better align the distributions of multiple source domains and target domain in the common label set. Moreover, the theoretical guarantee for UMAN is also provided. Massive experimental results show that existing UDA and multi-source DA (MDA) methods cannot be directly applied to UMDA and the proposed UMAN achieves the state-of-the-art performance in various UMDA settings.
Unveiling Class-Labeling Structure for Universal Domain Adaptation
Oct 10, 2020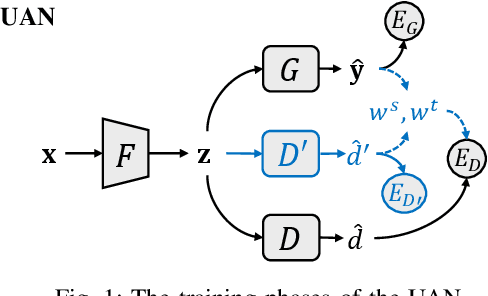
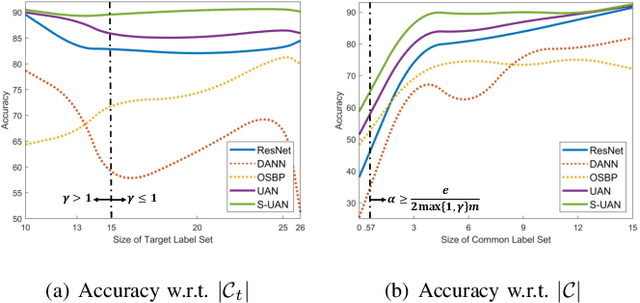
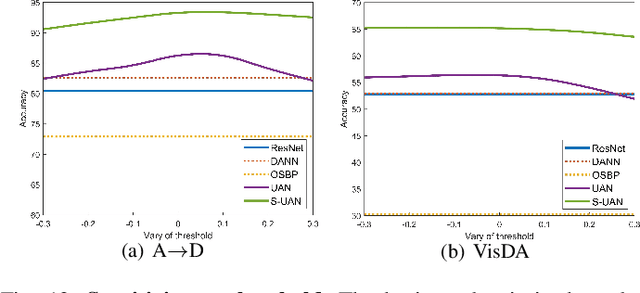
As a more practical setting for unsupervised domain adaptation, Universal Domain Adaptation (UDA) is recently introduced, where the target label set is unknown. One of the big challenges in UDA is how to determine the common label set shared by source and target domains, as there is simply no labeling available in the target domain. In this paper, we employ a probabilistic approach for locating the common label set, where each source class may come from the common label set with a probability. In particular, we propose a novel approach for evaluating the probability of each source class from the common label set, where this probability is computed by the prediction margin accumulated over the whole target domain. Then, we propose a simple universal adaptation network (S-UAN) by incorporating the probabilistic structure for the common label set. Finally, we analyse the generalization bound focusing on the common label set and explore the properties on the target risk for UDA. Extensive experiments indicate that S-UAN works well in different UDA settings and outperforms the state-of-the-art methods by large margins.
Learning-Based Safety-Stability-Driven Control for Safety-Critical Systems under Model Uncertainties
Sep 15, 2020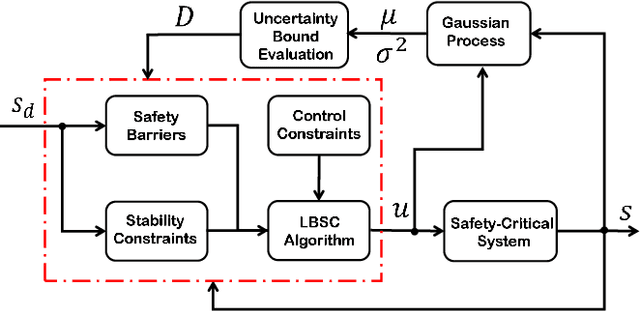
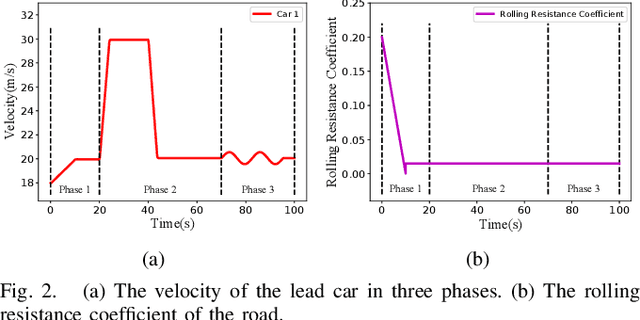
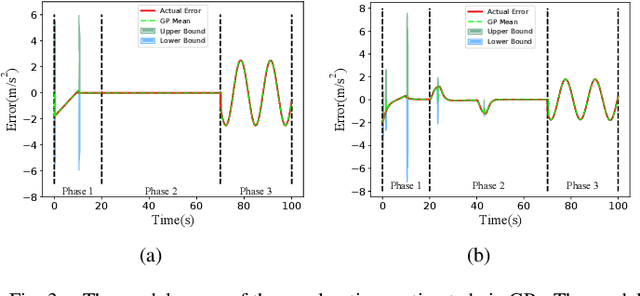
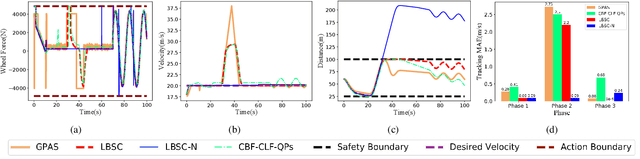
Safety and tracking stability are crucial for safety-critical systems such as self-driving cars, autonomous mobile robots, industrial manipulators. To efficiently control safety-critical systems to ensure their safety and achieve tracking stability, accurate system dynamic models are usually required. However, accurate system models are not always available in practice. In this paper, a learning-based safety-stability-driven control (LBSC) algorithm is presented to guarantee the safety and tracking stability for nonlinear safety-critical systems subject to control input constraints under model uncertainties. Gaussian Processes (GPs) are employed to learn the model error between the nominal model and the actual system dynamics, and the estimated mean and variance of the model error are used to quantify a high-confidence uncertainty bound. Using this estimated uncertainty bound, a safety barrier constraint is devised to ensure safety, and a stability constraint is developed to achieve rapid and accurate tracking. Then the proposed LBSC method is formulated as a quadratic program incorporating the safety barrier, the stability constraint, and the control constraints. The effectiveness of the LBSC method is illustrated on the safety-critical connected cruise control (CCC) system simulator under model uncertainties.
Safe Online Learning Tracking Control for Quadrotors under Wind Disturbances
Sep 08, 2020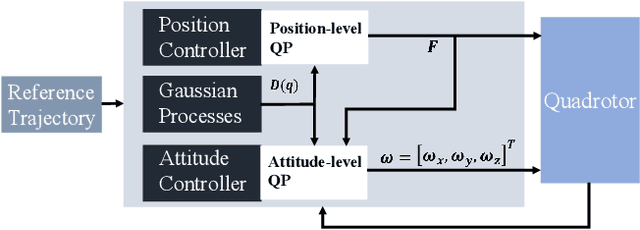
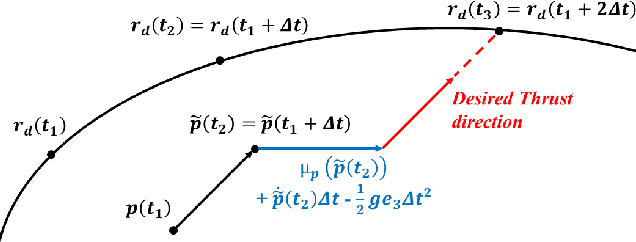
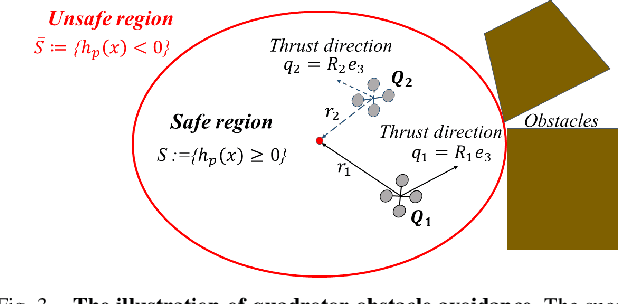
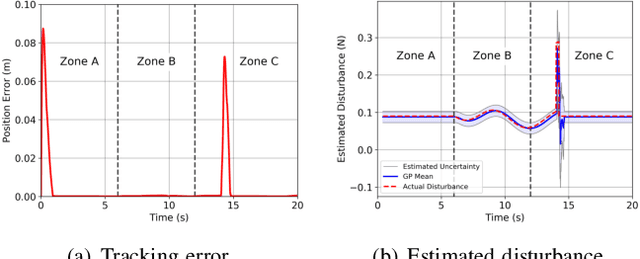
Enforcing safety on precise trajectory tracking is critical for aerial robotics subject to wind disturbances. In this paper, we present a learning-based safety-preserving cascaded quadratic programming control (SPQC) for safe trajectory tracking under wind disturbances. The SPQC controller consists of a position-level controller and an attitude-level controller. Gaussian Processes (GPs) are utilized to estimate the uncertainties caused by wind disturbances, and then a nominal Lyapunov-based cascaded quadratic program (QP) controller is designed to track the reference trajectory. To avoid unexpected obstacles when tracking, safety constraints represented by control barrier functions (CBFs) are enforced on each nominal QP controller in a way of minimal modification. The performance of the proposed SPQC controller is illustrated through numerical validations of (a) trajectory tracking under different wind disturbances, and (b) trajectory tracking in a cluttered environment with a dense time-varying obstacle field under wind disturbances.
Adaptive Interaction Modeling via Graph Operations Search
May 05, 2020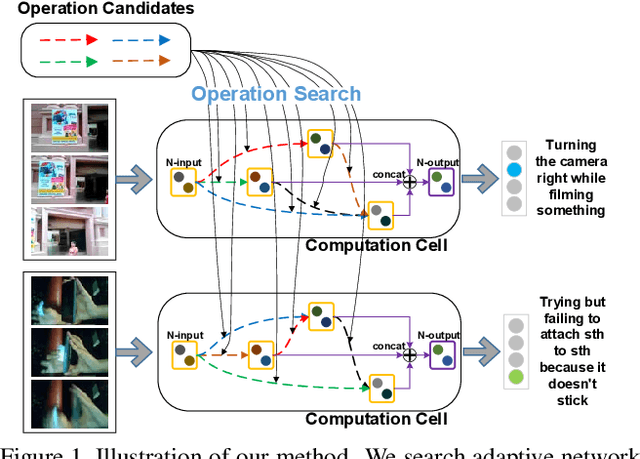
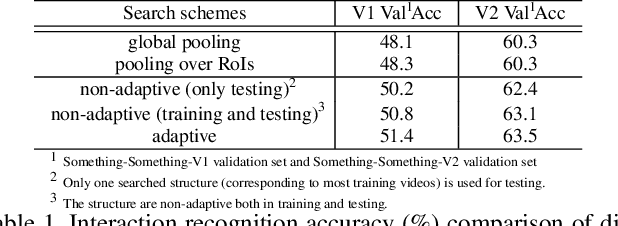
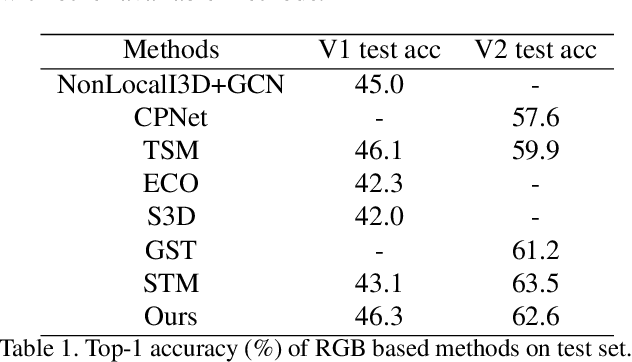
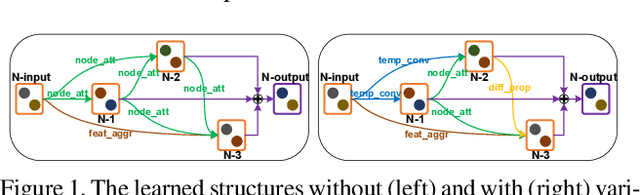
Interaction modeling is important for video action analysis. Recently, several works design specific structures to model interactions in videos. However, their structures are manually designed and non-adaptive, which require structures design efforts and more importantly could not model interactions adaptively. In this paper, we automate the process of structures design to learn adaptive structures for interaction modeling. We propose to search the network structures with differentiable architecture search mechanism, which learns to construct adaptive structures for different videos to facilitate adaptive interaction modeling. To this end, we first design the search space with several basic graph operations that explicitly capture different relations in videos. We experimentally demonstrate that our architecture search framework learns to construct adaptive interaction modeling structures, which provides more understanding about the relations between the structures and some interaction characteristics, and also releases the requirement of structures design efforts. Additionally, we show that the designed basic graph operations in the search space are able to model different interactions in videos. The experiments on two interaction datasets show that our method achieves competitive performance with state-of-the-arts.
Metric-Learning-Assisted Domain Adaptation
Apr 25, 2020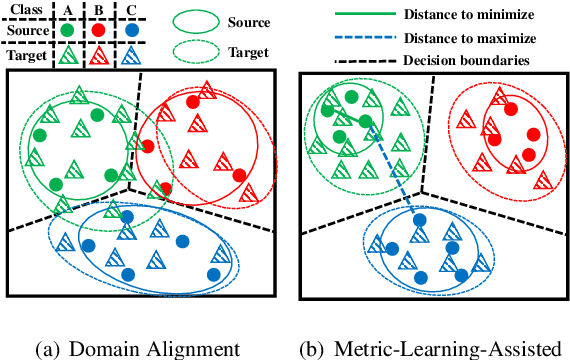
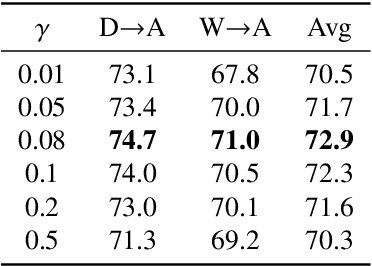
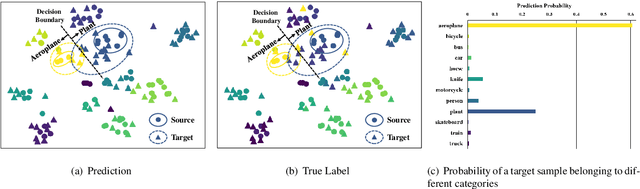
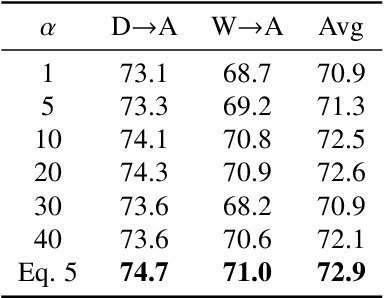
Domain alignment (DA) has been widely used in unsupervised domain adaptation. Many existing DA methods assume that a low source risk, together with the alignment of distributions of source and target, means a low target risk. In this paper, we show that this does not always hold. We thus propose a novel metric-learning-assisted domain adaptation (MLA-DA) method, which employs a novel triplet loss for helping better feature alignment. Experimental results show that the use of proposed triplet loss can achieve clearly better results. We also demonstrate the performance improvement of MLA-DA on all four standard benchmarks compared with the state-of-the-art unsupervised domain adaptation methods. Furthermore, MLA-DA shows stable performance in robust experiments.
Modality to Modality Translation: An Adversarial Representation Learning and Graph Fusion Network for Multimodal Fusion
Dec 12, 2019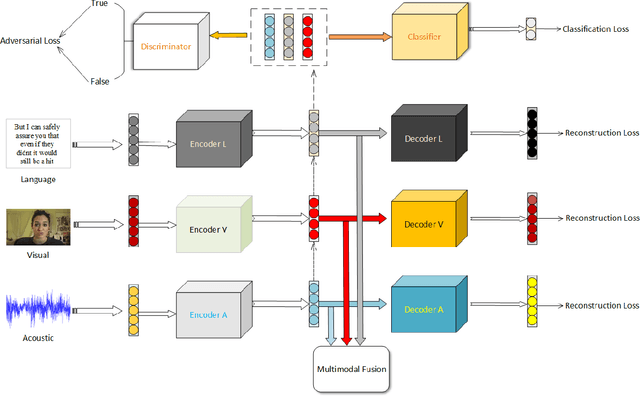
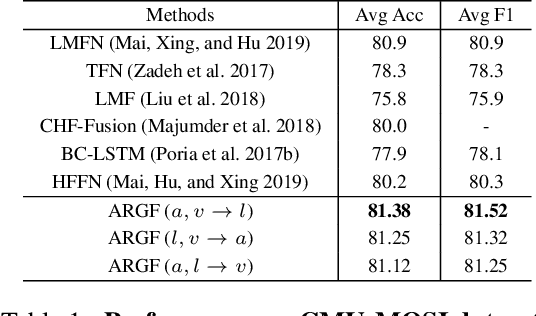
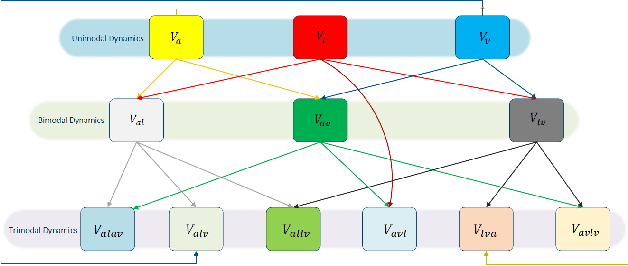
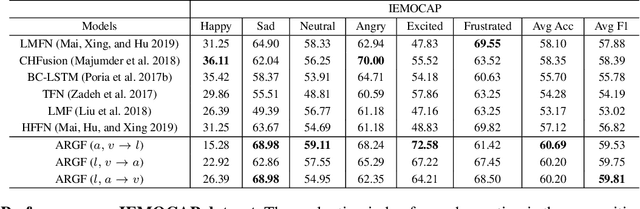
Learning joint embedding space for various modalities is of vital importance for multimodal fusion. Mainstream modality fusion approaches fail to achieve this goal, leaving a modality gap which heavily affects cross-modal fusion. In this paper, we propose a novel adversarial encoder-decoder-classifier framework to learn a modality-invariant embedding space. Since the distributions of various modalities vary in nature, to reduce the modality gap, we translate the distributions of source modalities into that of target modality via their respective encoders using adversarial training. Furthermore, we exert additional constraints on embedding space by introducing reconstruction loss and classification loss. Then we fuse the encoded representations using hierarchical graph neural network which explicitly explores unimodal, bimodal and trimodal interactions in multi-stage. Our method achieves state-of-the-art performance on multiple datasets. Visualization of the learned embeddings suggests that the joint embedding space learned by our method is discriminative.