 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-sparsity DNN: Fast Sparsity Optimization for On-Device Streaming E2E ASR via Supernet
Oct 15, 2021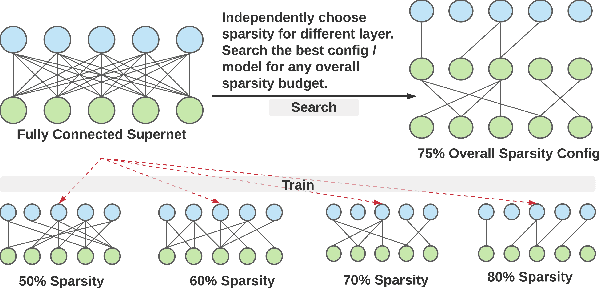
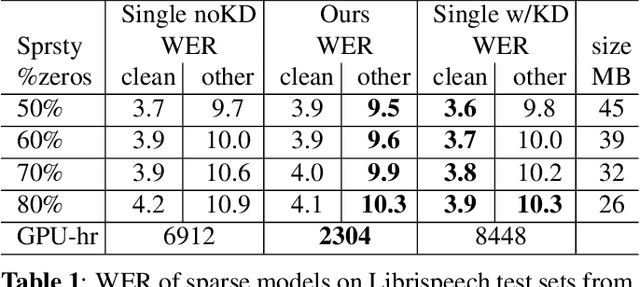
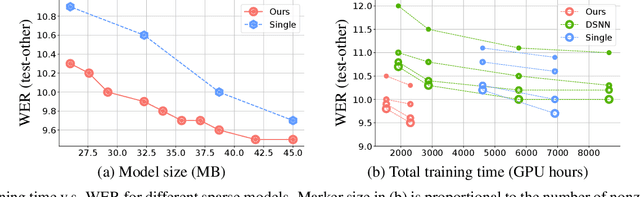
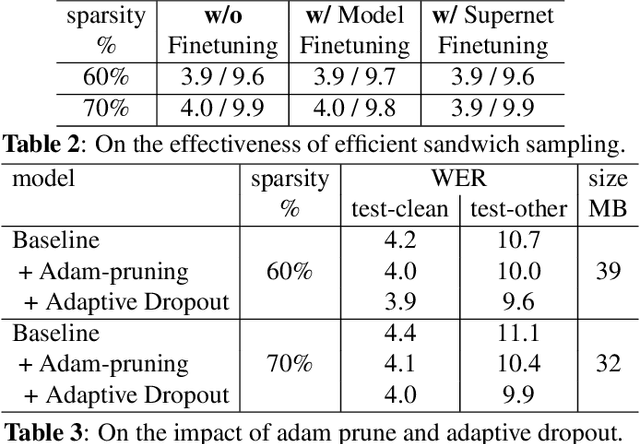
From wearables to powerful smart devices, modern automatic speech recognition (ASR) models run on a variety of edge devices with different computational budgets. To navigate the Pareto front of model accuracy vs model size, researchers are trapped in a dilemma of optimizing model accuracy by training and fine-tuning models for each individual edge device while keeping the training GPU-hours tractable. In this paper, we propose Omni-sparsity DNN, where a single neural network can be pruned to generate optimized model for a large range of model sizes. We develop training strategies for Omni-sparsity DNN that allows it to find models along the Pareto front of word-error-rate (WER) vs model size while keeping the training GPU-hours to no more than that of training one singular model. We demonstrate the Omni-sparsity DNN with streaming E2E ASR models. Our results show great saving on training time and resources with similar or better accuracy on LibriSpeech compared to individually pruned sparse models: 2%-6.6% better WER on Test-other.
Noisy Training Improves E2E ASR for the Edge
Jul 09, 2021
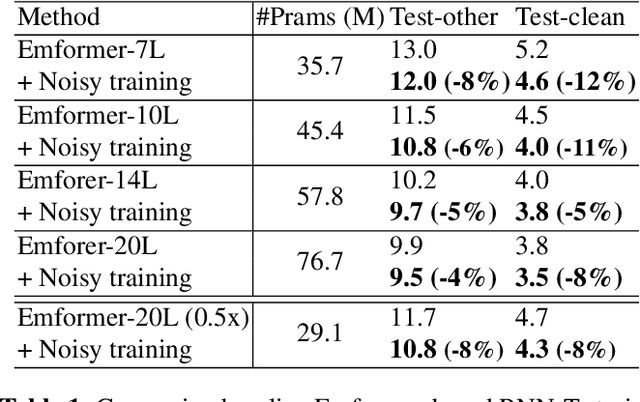
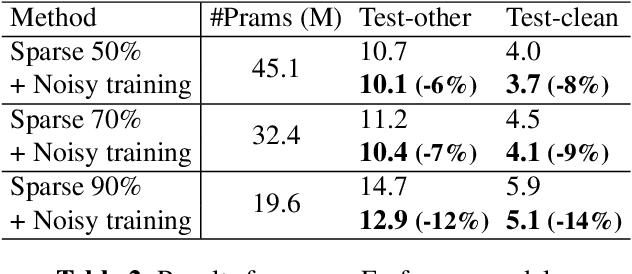
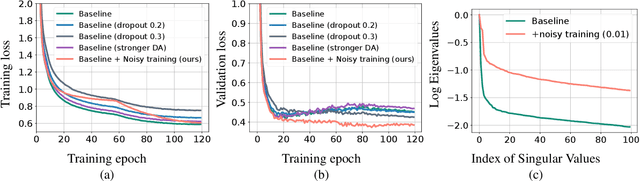
Automatic speech recognition (ASR) has become increasingly ubiquitous on modern edge devices. Past work developed streaming End-to-End (E2E) all-neural speech recognizers that can run compactly on edge devices. However, E2E ASR models are prone to overfitting and have difficulties in generalizing to unseen testing data. Various techniques have been proposed to regularize the training of ASR models, including layer normalization, dropout, spectrum data augmentation and speed distortions in the inputs. In this work, we present a simple yet effective noisy training strategy to further improve the E2E ASR model training. By introducing random noise to the parameter space during training, our method can produce smoother models at convergence that generalize better. We apply noisy training to improve both dense and sparse state-of-the-art Emformer models and observe consistent WER reduction. Specifically, when training Emformers with 90% sparsity, we achieve 12% and 14% WER improvements on the LibriSpeech Test-other and Test-clean data set, respectively.
GAN Slimming: All-in-One GAN Compression by A Unified Optimization Framework
Aug 25, 2020

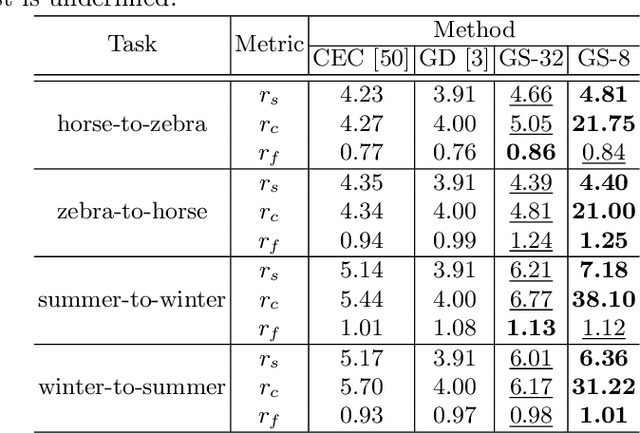

Generative adversarial networks (GANs) have gained increasing popularity in various computer vision applications, and recently start to be deployed to resource-constrained mobile devices. Similar to other deep models, state-of-the-art GANs suffer from high parameter complexities. That has recently motivated the exploration of compressing GANs (usually generators). Compared to the vast literature and prevailing success in compressing deep classifiers, the study of GAN compression remains in its infancy, so far leveraging individual compression techniques instead of more sophisticated combinations. We observe that due to the notorious instability of training GANs, heuristically stacking different compression techniques will result in unsatisfactory results. To this end, we propose the first unified optimization framework combining multiple compression means for GAN compression, dubbed GAN Slimming (GS). GS seamlessly integrates three mainstream compression techniques: model distillation, channel pruning and quantization, together with the GAN minimax objective, into one unified optimization form, that can be efficiently optimized from end to end. Without bells and whistles, GS largely outperforms existing options in compressing image-to-image translation GANs. Specifically, we apply GS to compress CartoonGAN, a state-of-the-art style transfer network, by up to 47 times, with minimal visual quality degradation. Codes and pre-trained models can be found at https://github.com/TAMU-VITA/GAN-Slimming.
Learning Sparsity and Quantization Jointly and Automatically for Neural Network Compression via Constrained Optimization
Oct 17, 2019
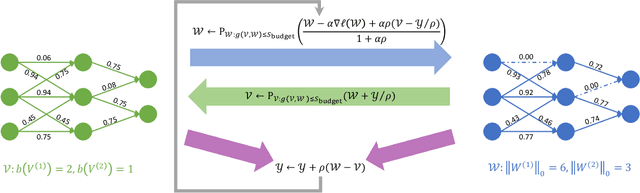
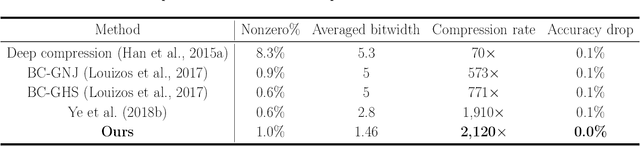
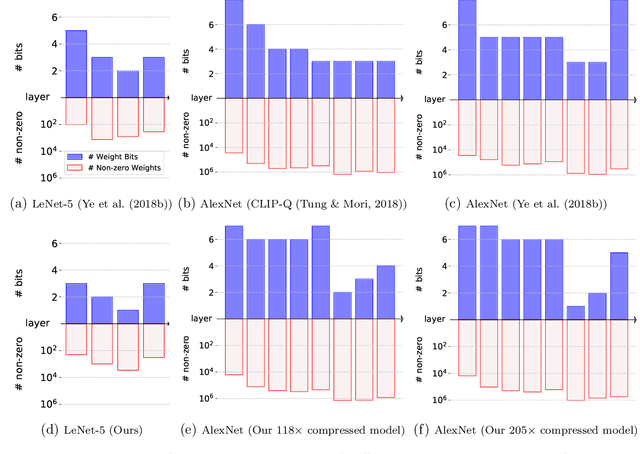
Deep Neural Networks (DNNs) are widely applied in a wide range of usecases. There is an increased demand for deploying DNNs on devices that do not have abundant resources such as memory and computation units. Recently, network compression through a variety of techniques such as pruning and quantization have been proposed to reduce the resource requirement. A key parameter that all existing compression techniques are sensitive to is the compression ratio (e.g., pruning sparsity, quantization bitwidth) of each layer. Traditional solutions treat the compression ratios of each layer as hyper-parameters, and tune them using human heuristic. Recent researchers start using black-box hyper-parameter optimizations, but they will introduce new hyper-parameters and have efficiency issue. In this paper, we propose a framework to jointly prune and quantize the DNNs automatically according to a target model size without using any hyper-parameters to manually set the compression ratio for each layer. In the experiments, we show that our framework can compress the weights data of ResNet-50 to be 836x smaller without accuracy loss on CIFAR-10, and compress AlexNet to be 205x smaller without accuracy loss on ImageNet classification.
Adversarially Trained Model Compression: When Robustness Meets Efficiency
Feb 10, 2019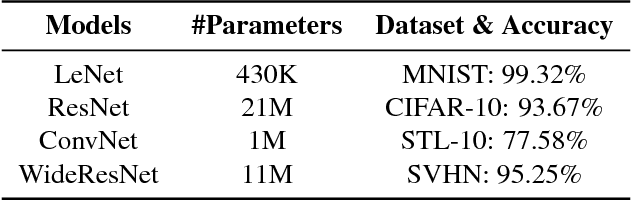
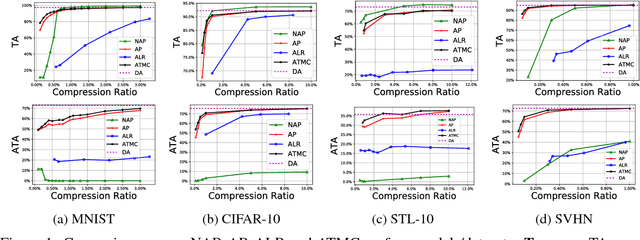
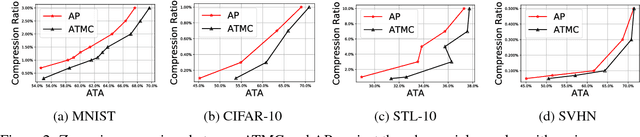
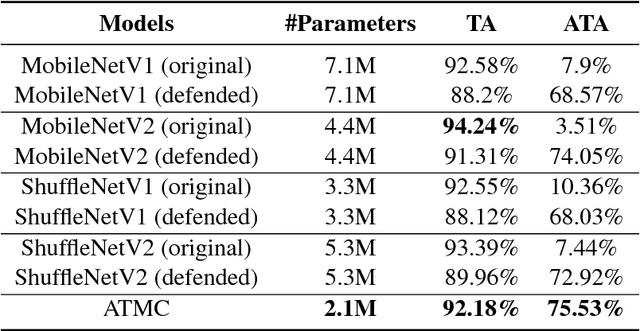
The robustness of deep models to adversarial attacks has gained significant attention in recent years, so has the model compactness and efficiency: yet the two have been mostly studied separately, with few relationships drawn between each other. This paper is concerned with: how can we combine the best of both worlds, obtaining a robust and compact network? The answer is not as straightforward as it may seem, since the two goals of model robustness and compactness may contradict from time to time. We formally study this new question, by proposing a novel Adversarially Trained Model Compression (ATMC) framework. A unified constrained optimization formulation is designed, with an efficient algorithm developed. An extensive group of experiments are then carefully designed and presented, demonstrating that ATMC obtains remarkably more favorable trade-off among model size, accuracy and robustness, over currently available alternatives in various settings.
ECC: Energy-Constrained Deep Neural Network Compression via a Bilinear Regression Model
Dec 17, 2018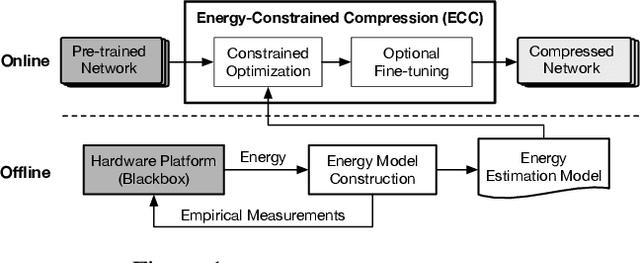
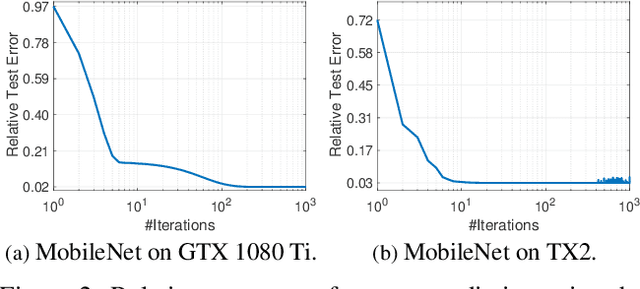

Many DNN-enabled vision applications constantly operate under severe energy constraints such as unmanned aerial vehicles, Augmented Reality headsets, and smartphones. Designing DNNs that can meet a stringent energy budget is becoming increasingly important. This paper proposes ECC, a framework that compresses DNNs to meet a given energy constraint while minimizing accuracy loss. The key idea of ECC is to model the DNN energy consumption via a novel bilinear regression function. The energy estimate model allows us to formulate DNN compression as a constrained optimization that minimizes the DNN loss function over the energy constraint. The optimization problem, however, has nontrivial constraints. Therefore, existing deep learning solvers do not apply directly. We propose an optimization algorithm that combines the essence of the Alternating Direction Method of Multipliers (ADMM) framework with gradient-based learning algorithms. The algorithm decomposes the original constrained optimization into several subproblems that are solved iteratively and efficiently. ECC is also portable across different hardware platforms without requiring hardware knowledge. Experiments show that ECC achieves higher accuracy under the same or lower energy budget compared to state-of-the-art resource-constrained DNN compression techniques.
Marginal Policy Gradients: A Unified Family of Estimators for Bounded Action Spaces with Applications
Sep 27, 2018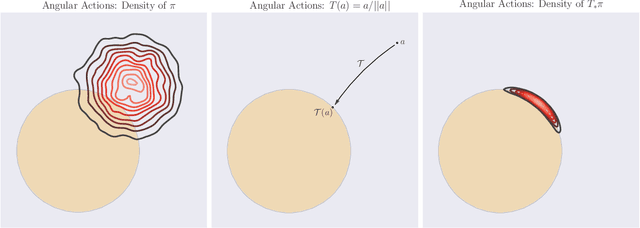
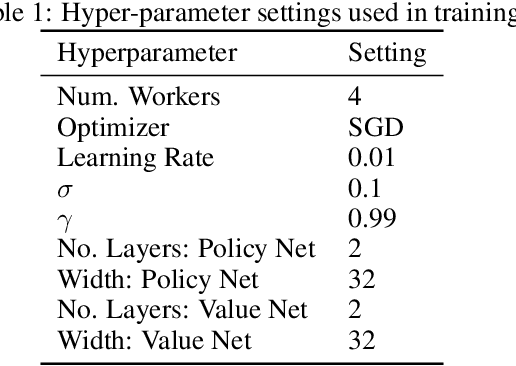
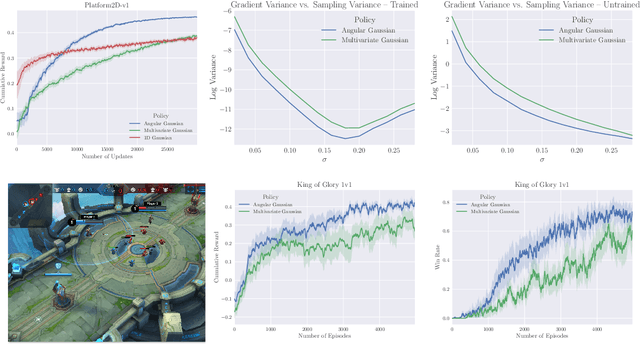
Many complex domains, such as robotics control and real-time strategy (RTS) games, require an agent to learn a continuous control. In the former, an agent learns a policy over $\mathbb{R}^d$ and in the latter, over a discrete set of actions each of which is parametrized by a continuous parameter. Such problems are naturally solved using policy based reinforcement learning (RL) methods, but unfortunately these often suffer from high variance leading to instability and slow convergence. Unnecessary variance is introduced whenever policies over bounded action spaces are modeled using distributions with unbounded support by applying a transformation $T$ to the sampled action before execution in the environment. Recently, the variance reduced clipped action policy gradient (CAPG) was introduced for actions in bounded intervals, but to date no variance reduced methods exist when the action is a direction, something often seen in RTS games. To this end we introduce the angular policy gradient (APG), a stochastic policy gradient method for directional control. With the marginal policy gradients family of estimators we present a unified analysis of the variance reduction properties of APG and CAPG; our results provide a stronger guarantee than existing analyses for CAPG. Experimental results on a popular RTS game and a navigation task show that the APG estimator offers a substantial improvement over the standard policy gradient.
End-to-End Learning of Energy-Constrained Deep Neural Networks
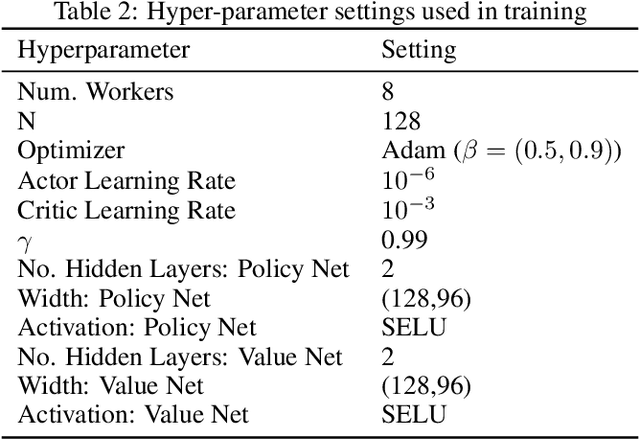
Jun 12, 2018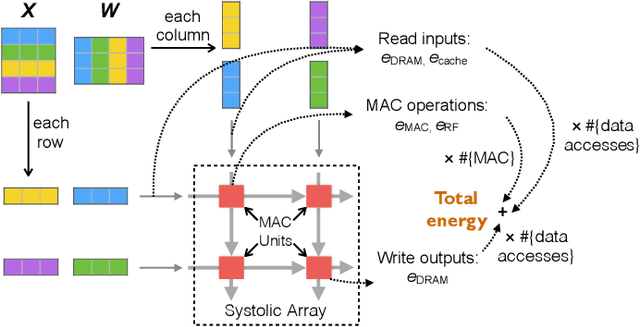

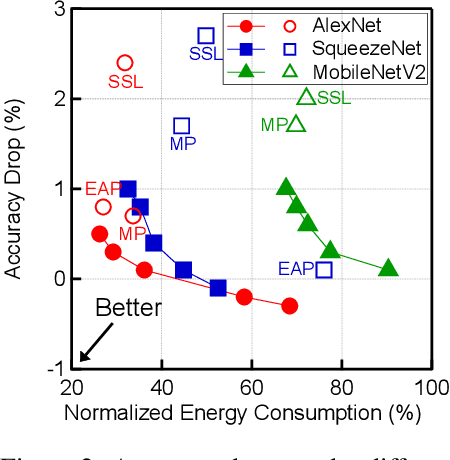

Deep Neural Networks (DNN) are increasingly deployed in highly energy-constrained environments such as autonomous drones and wearable devices while at the same time must operate in real-time. Therefore, reducing the energy consumption has become a major design consideration in DNN training. This paper proposes the first end-to-end DNN training framework that provides quantitative energy guarantees. The key idea is to formulate the DNN training as an optimization problem in which the energy budget imposes a previously unconsidered optimization constraint. We integrate the quantitative DNN energy estimation into the DNN training process to assist the constraint optimization. We prove that an approximate algorithm can be used to efficiently solve the optimization problem. Compared to the best prior energy-saving techniques, our framework trains DNNs that provide higher accuracies under same or lower energy budgets.
Learning Simple Thresholded Features with Sparse Support Recovery
Apr 16, 2018
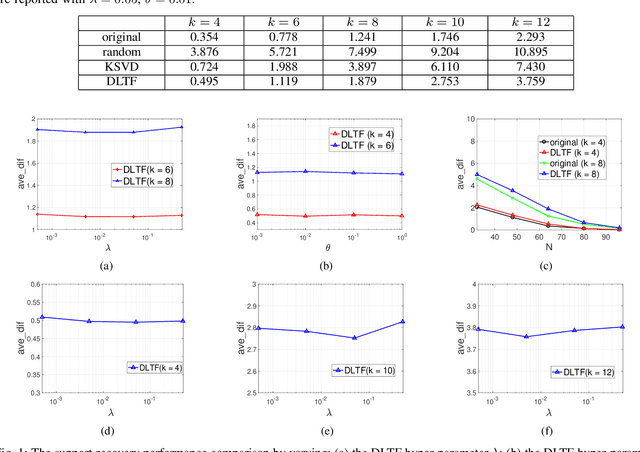
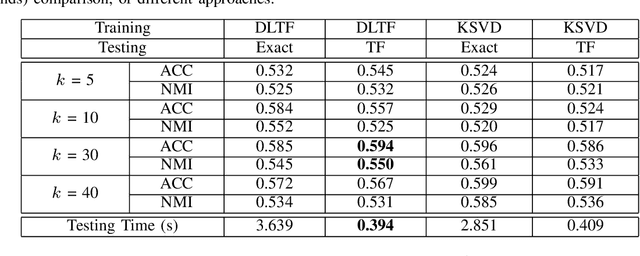

The thresholded feature has recently emerged as an extremely efficient, yet rough empirical approximation, of the time-consuming sparse coding inference process. Such an approximation has not yet been rigorously examined, and standard dictionaries often lead to non-optimal performance when used for computing thresholded features. In this paper, we first present two theoretical recovery guarantees for the thresholded feature to exactly recover the nonzero support of the sparse code. Motivated by them, we then formulate the Dictionary Learning for Thresholded Features (DLTF) model, which learns an optimized dictionary for applying the thresholded feature. In particular, for the $(k, 2)$ norm involved, a novel proximal operator with log-linear time complexity $O(m\log m)$ is derived. We evaluate the performance of DLTF on a vast range of synthetic and real-data tasks, where DLTF demonstrates remarkable efficiency, effectiveness and robustness in all experiments. In addition, we briefly discuss the potential link between DLTF and deep learning building blocks.
A Robust AUC Maximization Framework with Simultaneous Outlier Detection and Feature Selection for Positive-Unlabeled Classification
Mar 18, 2018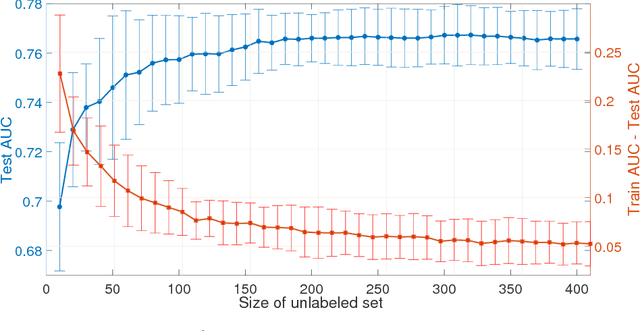
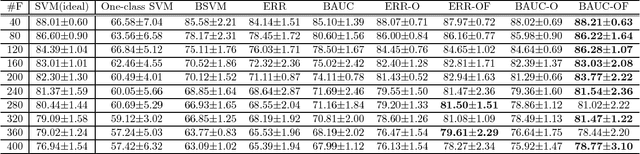
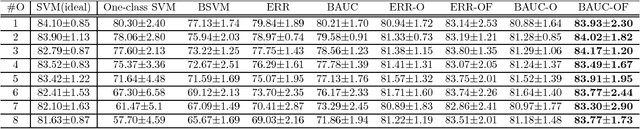
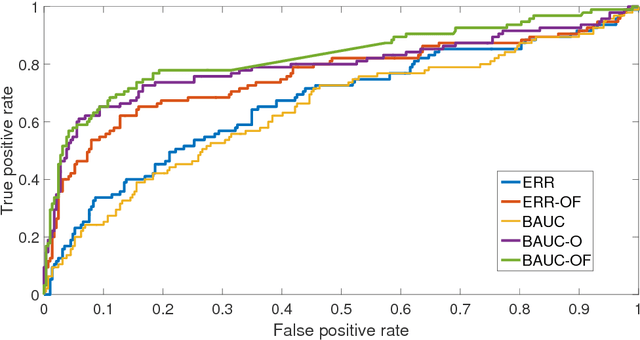
The positive-unlabeled (PU) classification is a common scenario in real-world applications such as healthcare, text classification, and bioinformatics, in which we only observe a few samples labeled as "positive" together with a large volume of "unlabeled" samples that may contain both positive and negative samples. Building robust classifier for the PU problem is very challenging, especially for complex data where the negative samples overwhelm and mislabeled samples or corrupted features exist. To address these three issues, we propose a robust learning framework that unifies AUC maximization (a robust metric for biased labels), outlier detection (for excluding wrong labels), and feature selection (for excluding corrupted features). The generalization error bounds are provided for the proposed model that give valuable insight into the theoretical performance of the method and lead to useful practical guidance, e.g., to train a model, we find that the included unlabeled samples are sufficient as long as the sample size is comparable to the number of positive samples in the training process. Empirical comparisons and two real-world applications on surgical site infection (SSI) and EEG seizure detection are also conducted to show the effectiveness of the proposed model.