 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment First or Comprehend First? Explore the Limit of Unsupervised Word Segmentation with Large Language Models
May 26, 2025Word segmentation stands as a cornerstone of Natural Language Processing (NLP). Based on the concept of "comprehend first, segment later", we propose a new framework to explore the limit of unsupervised word segmentation with Large Language Models (LLMs) and evaluate the semantic understanding capabilities of LLMs based on word segmentation. We employ current mainstream LLMs to perform word segmentation across multiple languages to assess LLMs' "comprehension". Our findings reveal that LLMs are capable of following simple prompts to segment raw text into words. There is a trend suggesting that models with more parameters tend to perform better on multiple languages. Additionally, we introduce a novel unsupervised method, termed LLACA ($\textbf{L}$arge $\textbf{L}$anguage Model-Inspired $\textbf{A}$ho-$\textbf{C}$orasick $\textbf{A}$utomaton). Leveraging the advanced pattern recognition capabilities of Aho-Corasick automata, LLACA innovatively combines these with the deep insights of well-pretrained LLMs. This approach not only enables the construction of a dynamic $n$-gram model that adjusts based on contextual information but also integrates the nuanced understanding of LLMs, offering significant improvements over traditional methods. Our source code is available at https://github.com/hkr04/LLACA
Faster MoE LLM Inference for Extremely Large Models
May 06, 2025



Sparse Mixture of Experts (MoE) large language models (LLMs) are gradually becoming the mainstream approach for ultra-large-scale models. Existing optimization efforts for MoE models have focused primarily on coarse-grained MoE architectures. With the emergence of DeepSeek Models, fine-grained MoE models are gaining popularity, yet research on them remains limited. Therefore, we want to discuss the efficiency dynamic under different service loads. Additionally, fine-grained models allow deployers to reduce the number of routed experts, both activated counts and total counts, raising the question of how this reduction affects the trade-off between MoE efficiency and performance. Our findings indicate that while deploying MoE models presents greater challenges, it also offers significant optimization opportunities. Reducing the number of activated experts can lead to substantial efficiency improvements in certain scenarios, with only minor performance degradation. Reducing the total number of experts provides limited efficiency gains but results in severe performance degradation. Our method can increase throughput by at least 10\% without any performance degradation. Overall, we conclude that MoE inference optimization remains an area with substantial potential for exploration and improvement.
BriLLM: Brain-inspired Large Language Model
Mar 14, 2025



This paper reports the first brain-inspired large language model (BriLLM). This is a non-Transformer, non-GPT, non-traditional machine learning input-output controlled generative language model. The model is based on the Signal Fully-connected flowing (SiFu) definition on the directed graph in terms of the neural network, and has the interpretability of all nodes on the graph of the whole model, instead of the traditional machine learning model that only has limited interpretability at the input and output ends. In the language model scenario, the token is defined as a node in the graph. A randomly shaped or user-defined signal flow flows between nodes on the principle of "least resistance" along paths. The next token or node to be predicted or generated is the target of the signal flow. As a language model, BriLLM theoretically supports infinitely long $n$-gram models when the model size is independent of the input and predicted length of the model. The model's working signal flow provides the possibility of recall activation and innate multi-modal support similar to the cognitive patterns of the human brain. At present, we released the first BriLLM version in Chinese, with 4000 tokens, 32-dimensional node width, 16-token long sequence prediction ability, and language model prediction performance comparable to GPT-1. More computing power will help us explore the infinite possibilities depicted above.
Towards Enhanced Immersion and Agency for LLM-based Interactive Drama
Feb 25, 2025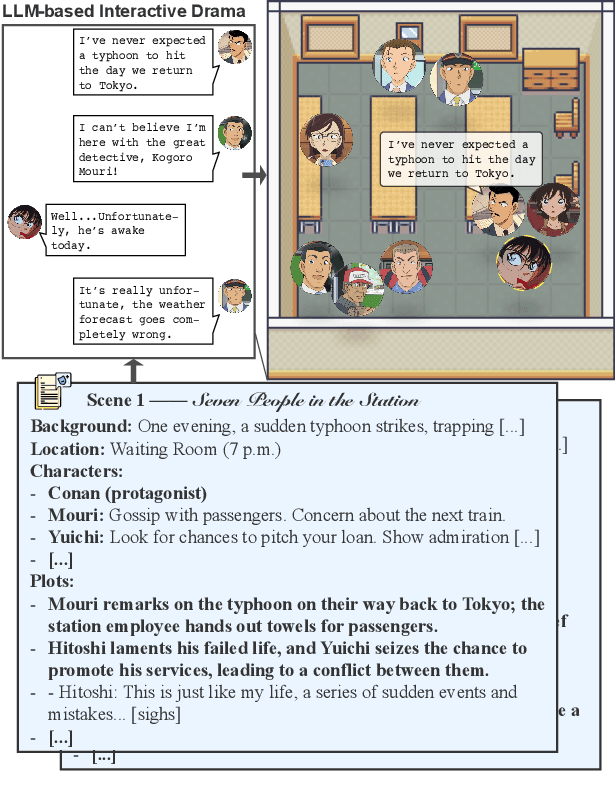

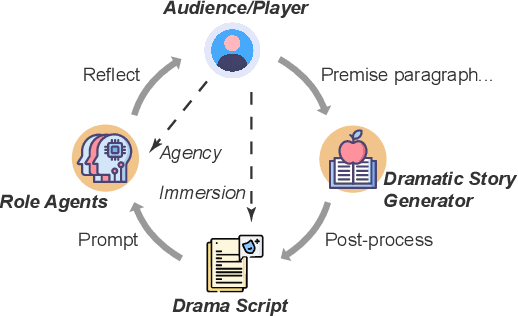

LLM-based Interactive Drama is a novel AI-based dialogue scenario, where the user (i.e. the player) plays the role of a character in the story, has conversations with characters played by LLM agents, and experiences an unfolding story. This paper begins with understanding interactive drama from two aspects: Immersion, the player's feeling of being present in the story, and Agency, the player's ability to influence the story world. Both are crucial to creating an enjoyable interactive experience, while they have been underexplored in previous work. To enhance these two aspects, we first propose Playwriting-guided Generation, a novel method that helps LLMs craft dramatic stories with substantially improved structures and narrative quality. Additionally, we introduce Plot-based Reflection for LLM agents to refine their reactions to align with the player's intentions. Our evaluation relies on human judgment to assess the gains of our methods in terms of immersion and agency.
Textual-to-Visual Iterative Self-Verification for Slide Generation
Feb 21, 2025



Generating presentation slides is a time-consuming task that urgently requires automation. Due to their limited flexibility and lack of automated refinement mechanisms, existing autonomous LLM-based agents face constraints in real-world applicability. We decompose the task of generating missing presentation slides into two key components: content generation and layout generation, aligning with the typical process of creating academic slides. First, we introduce a content generation approach that enhances coherence and relevance by incorporating context from surrounding slides and leveraging section retrieval strategies. For layout generation, we propose a textual-to-visual self-verification process using a LLM-based Reviewer + Refiner workflow, transforming complex textual layouts into intuitive visual formats. This modality transformation simplifies the task, enabling accurate and human-like review and refinement. Experiments show that our approach significantly outperforms baseline methods in terms of alignment, logical flow, visual appeal, and readability.
Plan-over-Graph: Towards Parallelable LLM Agent Schedule
Feb 20, 2025



Large Language Models (LLMs) have demonstrated exceptional abilities in reasoning for task planning. However, challenges remain under-explored for parallel schedules. This paper introduces a novel paradigm, plan-over-graph, in which the model first decomposes a real-life textual task into executable subtasks and constructs an abstract task graph. The model then understands this task graph as input and generates a plan for parallel execution. To enhance the planning capability of complex, scalable graphs, we design an automated and controllable pipeline to generate synthetic graphs and propose a two-stage training scheme. Experimental results show that our plan-over-graph method significantly improves task performance on both API-based LLMs and trainable open-sourced LLMs. By normalizing complex tasks as graphs, our method naturally supports parallel execution, demonstrating global efficiency. The code and data are available at https://github.com/zsq259/Plan-over-Graph.
LESA: Learnable LLM Layer Scaling-Up
Feb 19, 2025Training Large Language Models (LLMs) from scratch requires immense computational resources, making it prohibitively expensive. Model scaling-up offers a promising solution by leveraging the parameters of smaller models to create larger ones. However, existing depth scaling-up methods rely on empirical heuristic rules for layer duplication, which result in poorer initialization and slower convergence during continual pre-training. We propose \textbf{LESA}, a novel learnable method for depth scaling-up. By concatenating parameters from each layer and applying Singular Value Decomposition, we uncover latent patterns between layers, suggesting that inter-layer parameters can be learned. LESA uses a neural network to predict the parameters inserted between adjacent layers, enabling better initialization and faster training. Experiments show that LESA outperforms existing baselines, achieving superior performance with less than half the computational cost during continual pre-training. Extensive analyses demonstrate its effectiveness across different model sizes and tasks.
Unfolding the Headline: Iterative Self-Questioning for News Retrieval and Timeline Summarization
Jan 01, 2025



In the fast-changing realm of information, the capacity to construct coherent timelines from extensive event-related content has become increasingly significant and challenging. The complexity arises in aggregating related documents to build a meaningful event graph around a central topic. This paper proposes CHRONOS - Causal Headline Retrieval for Open-domain News Timeline SummarizatiOn via Iterative Self-Questioning, which offers a fresh perspective on the integration of Large Language Models (LLMs) to tackle the task of Timeline Summarization (TLS). By iteratively reflecting on how events are linked and posing new questions regarding a specific news topic to gather information online or from an offline knowledge base, LLMs produce and refresh chronological summaries based on documents retrieved in each round. Furthermore, we curate Open-TLS, a novel dataset of timelines on recent news topics authored by professional journalists to evaluate open-domain TLS where information overload makes it impossible to find comprehensive relevant documents from the web. Our experiments indicate that CHRONOS is not only adept at open-domain timeline summarization, but it also rivals the performance of existing state-of-the-art systems designed for closed-domain applications, where a related news corpus is provided for summarization.
KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache Sharing
Oct 24, 2024



The development of large language models (LLMs) has significantly expanded model sizes, resulting in substantial GPU memory requirements during inference. The key and value storage of the attention map in the KV (key-value) cache accounts for more than 80\% of this memory consumption. Nowadays, most existing KV cache compression methods focus on intra-layer compression within a single Transformer layer but few works consider layer-wise compression. In this paper, we propose a plug-and-play method called \textit{KVSharer}, which shares the KV cache between layers to achieve layer-wise compression. Rather than intuitively sharing based on higher similarity, we discover a counterintuitive phenomenon: sharing dissimilar KV caches better preserves the model performance. Experiments show that \textit{KVSharer} can reduce KV cache computation by 30\%, thereby lowering memory consumption without significantly impacting model performance and it can also achieve at least 1.3 times generation acceleration. Additionally, we verify that \textit{KVSharer} is compatible with existing intra-layer KV cache compression methods, and combining both can further save memory.
Instruction-Driven Game Engine: A Poker Case Study
Oct 17, 2024The Instruction-Driven Game Engine (IDGE) project aims to democratize game development by enabling a large language model (LLM) to follow free-form game descriptions and generate game-play processes. The IDGE allows users to create games simply by natural language instructions, which significantly lowers the barrier for game development. We approach the learning process for IDGEs as a Next State Prediction task, wherein the model autoregressively predicts the game states given player actions. The computation of game states must be precise; otherwise, slight errors could corrupt the game-play experience. This is challenging because of the gap between stability and diversity. To address this, we train the IDGE in a curriculum manner that progressively increases its exposure to complex scenarios. Our initial progress lies in developing an IDGE for Poker, which not only supports a wide range of poker variants but also allows for highly individualized new poker games through natural language inputs. This work lays the groundwork for future advancements in transforming how games are created and played.