 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Preserving Adversarial Code Comprehension
Sep 12, 2022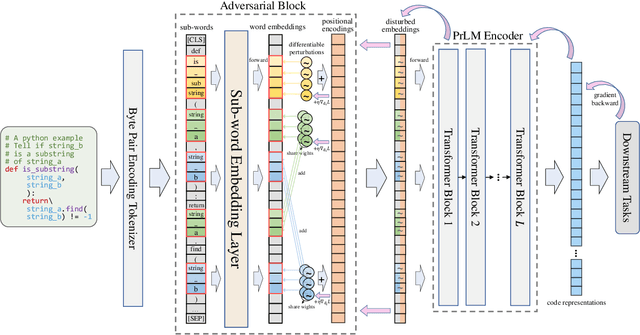
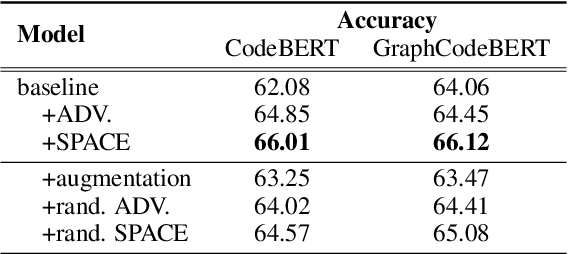
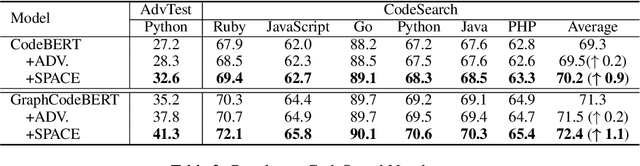

Based on the tremendous success of pre-trained language models (PrLMs) for source code comprehension tasks, current literature studies either ways to further improve the performance (generalization) of PrLMs, or their robustness against adversarial attacks. However, they have to compromise on the trade-off between the two aspects and none of them consider improving both sides in an effective and practical way. To fill this gap, we propose Semantic-Preserving Adversarial Code Embeddings (SPACE) to find the worst-case semantic-preserving attacks while forcing the model to predict the correct labels under these worst cases. Experiments and analysis demonstrate that SPACE can stay robust against state-of-the-art attacks while boosting the performance of PrLMs for code.
Evaluate Confidence Instead of Perplexity for Zero-shot Commonsense Reasoning
Aug 23, 2022
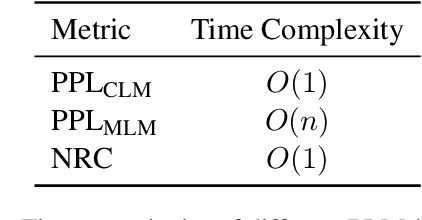
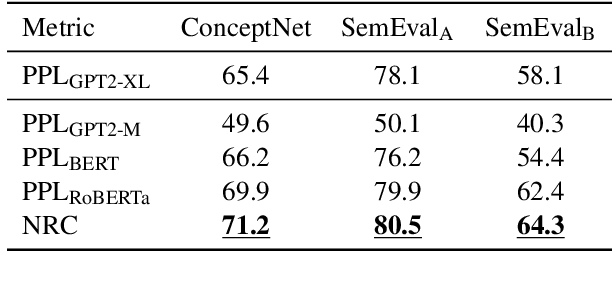
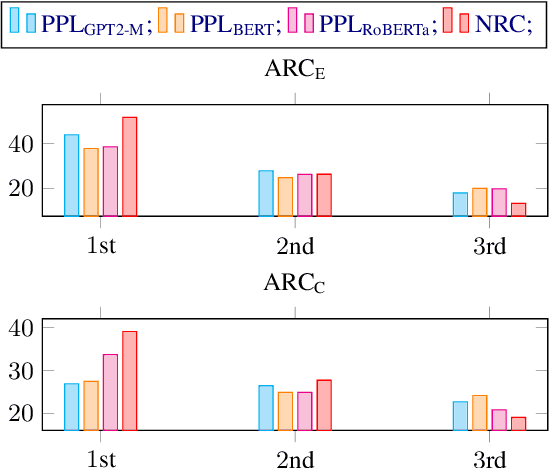
Commonsense reasoning is an appealing topic in natural language processing (NLP) as it plays a fundamental role in supporting the human-like actions of NLP systems. With large-scale language models as the backbone, unsupervised pre-training on numerous corpora shows the potential to capture commonsense knowledge. Current pre-trained language model (PLM)-based reasoning follows the traditional practice using perplexity metric. However, commonsense reasoning is more than existing probability evaluation, which is biased by word frequency. This paper reconsiders the nature of commonsense reasoning and proposes a novel commonsense reasoning metric, Non-Replacement Confidence (NRC). In detail, it works on PLMs according to the Replaced Token Detection (RTD) pre-training objective in ELECTRA, in which the corruption detection objective reflects the confidence on contextual integrity that is more relevant to commonsense reasoning than existing probability. Our proposed novel method boosts zero-shot performance on two commonsense reasoning benchmark datasets and further seven commonsense question-answering datasets. Our analysis shows that pre-endowed commonsense knowledge, especially for RTD-based PLMs, is essential in downstream reasoning.
Learning Better Masking for Better Language Model Pre-training
Aug 23, 2022
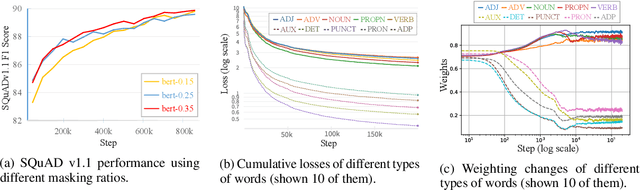
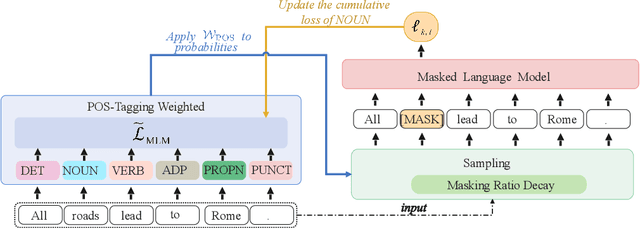
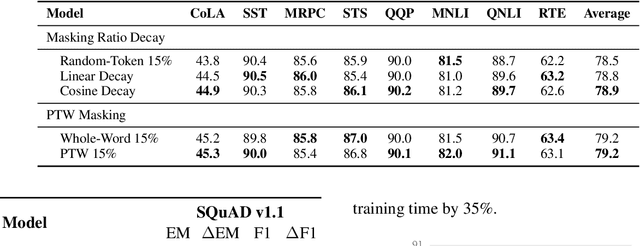
Masked Language Modeling (MLM) has been widely used as the denoising objective in pre-training language models (PrLMs). Existing PrLMs commonly adopt a random-token masking strategy where a fixed masking ratio is applied and different contents are masked by an equal probability throughout the entire training. However, the model may receive complicated impact from pre-training status, which changes accordingly as training time goes on. In this paper, we show that such time-invariant MLM settings on masking ratio and masked content are unlikely to deliver an optimal outcome, which motivates us to explore the influence of time-variant MLM settings. We propose two scheduled masking approaches that adaptively tune the masking ratio and contents in different training stages, which improves the pre-training efficiency and effectiveness verified on the downstream tasks. Our work is a pioneer study on time-variant masking strategy on ratio and contents and gives a better understanding of how masking ratio and masked content influence the MLM pre-training.
Adversarial Self-Attention for Language Understanding
Jun 25, 2022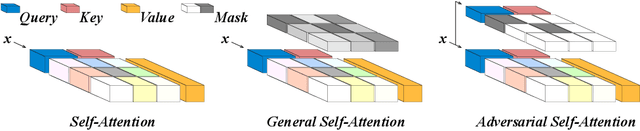
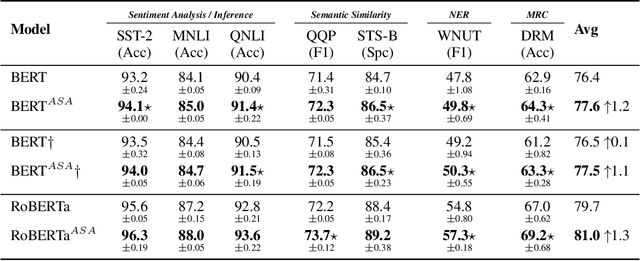

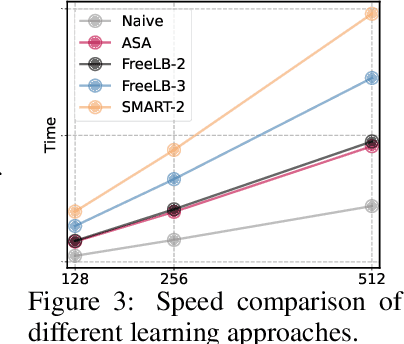
An ultimate language system aims at the high generalization and robustness when adapting to diverse scenarios. Unfortunately, the recent white hope pre-trained language models (PrLMs) barely escape from stacking excessive parameters to the over-parameterized Transformer architecture to achieve higher performances. This paper thus proposes \textit{Adversarial Self-Attention} mechanism (ASA), which adversarially reconstructs the Transformer attentions and facilitates model training from contaminated model structures, coupled with a fast and simple implementation for better PrLM building. We conduct comprehensive evaluation across a wide range of tasks on both pre-training and fine-tuning stages. For pre-training, ASA unfolds remarkable performance gain compared to regular training for longer periods. For fine-tuning, ASA-empowered models consistently outweigh naive models by a large margin considering both generalization and robustness.
Generative or Contrastive? Phrase Reconstruction for Better Sentence Representation Learning
Apr 20, 2022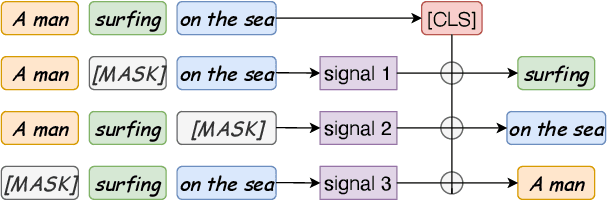
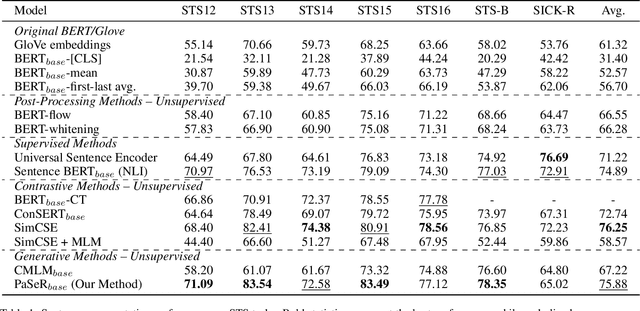
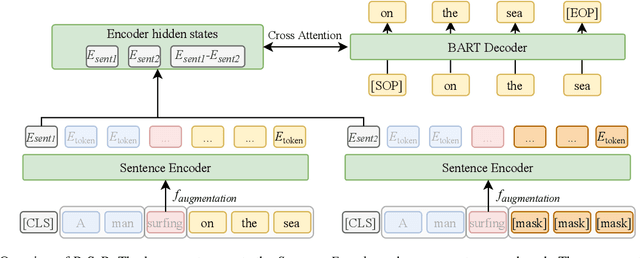
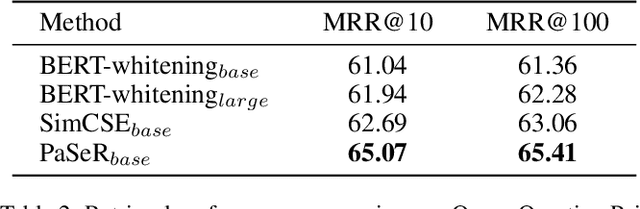
Though offering amazing contextualized token-level representations, current pre-trained language models actually take less attention on acquiring sentence-level representation during its self-supervised pre-training. If self-supervised learning can be distinguished into two subcategories, generative and contrastive, then most existing studies show that sentence representation learning may more benefit from the contrastive methods but not the generative methods. However, contrastive learning cannot be well compatible with the common token-level generative self-supervised learning, and does not guarantee good performance on downstream semantic retrieval tasks. Thus, to alleviate such obvious inconveniences, we instead propose a novel generative self-supervised learning objective based on phrase reconstruction. Empirical studies show that our generative learning may yield powerful enough sentence representation and achieve performance in Sentence Textual Similarity (STS) tasks on par with contrastive learning. Further, in terms of unsupervised setting, our generative method outperforms previous state-of-the-art SimCSE on the benchmark of downstream semantic retrieval tasks.
Back to the Future: Bidirectional Information Decoupling Network for Multi-turn Dialogue Modeling
Apr 18, 2022
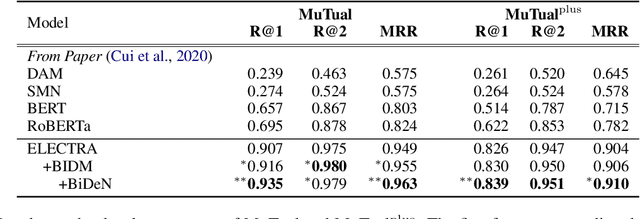
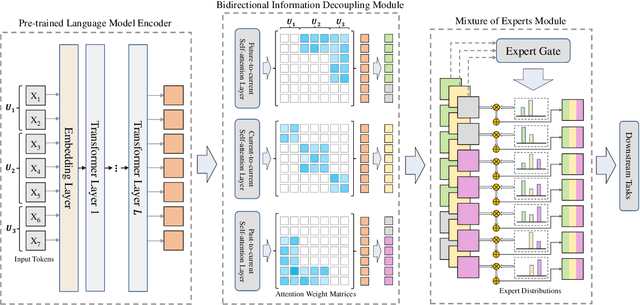
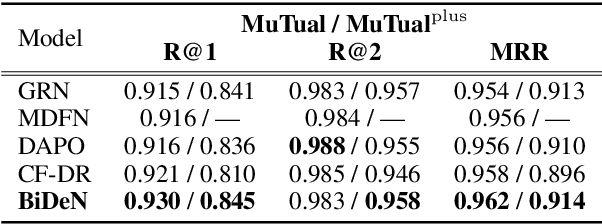
Multi-turn dialogue modeling as a challenging branch of natural language understanding (NLU), aims to build representations for machines to understand human dialogues, which provides a solid foundation for multiple downstream tasks. Recent studies of dialogue modeling commonly employ pre-trained language models (PrLMs) to encode the dialogue history as successive tokens, which is insufficient in capturing the temporal characteristics of dialogues. Therefore, we propose Bidirectional Information Decoupling Network (BiDeN) as a universal dialogue encoder, which explicitly incorporates both the past and future contexts and can be generalized to a wide range of dialogue-related tasks. Experimental results on datasets of different downstream tasks demonstrate the universality and effectiveness of our BiDeN.
Nested Named Entity Recognition as Holistic Structure Parsing
Apr 17, 2022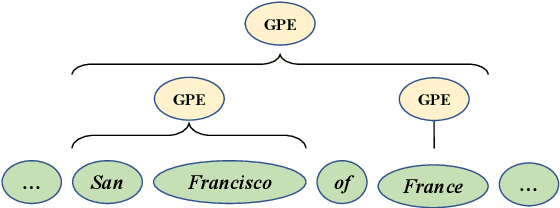
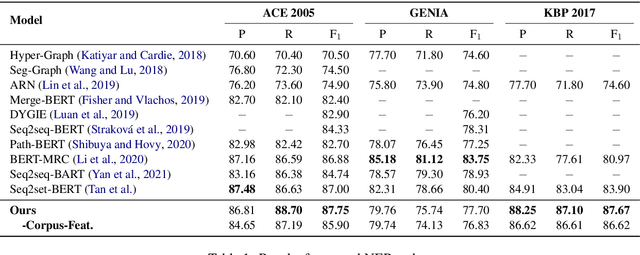
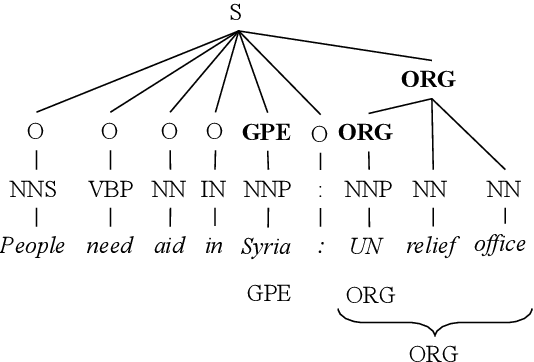
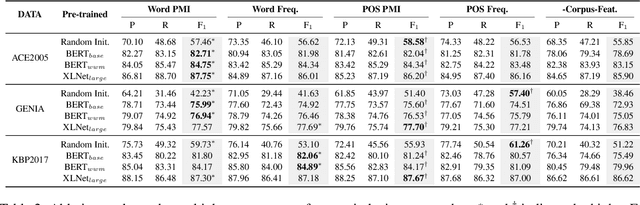
As a fundamental natural language processing task and one of core knowledge extraction techniques, named entity recognition (NER) is widely used to extract information from texts for downstream tasks. Nested NER is a branch of NER in which the named entities (NEs) are nested with each other. However, most of the previous studies on nested NER usually apply linear structure to model the nested NEs which are actually accommodated in a hierarchical structure. Thus in order to address this mismatch, this work models the full nested NEs in a sentence as a holistic structure, then we propose a holistic structure parsing algorithm to disclose the entire NEs once for all. Besides, there is no research on applying corpus-level information to NER currently. To make up for the loss of this information, we introduce Point-wise Mutual Information (PMI) and other frequency features from corpus-aware statistics for even better performance by holistic modeling from sentence-level to corpus-level. Experiments show that our model yields promising results on widely-used benchmarks which approach or even achieve state-of-the-art. Further empirical studies show that our proposed corpus-aware features can substantially improve NER domain adaptation, which demonstrates the surprising advantage of our proposed corpus-level holistic structure modeling.
Lite Unified Modeling for Discriminative Reading Comprehension
Mar 26, 2022
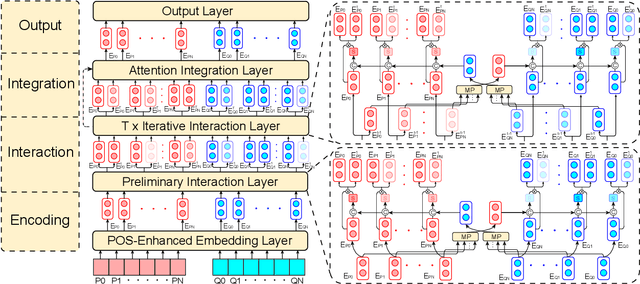
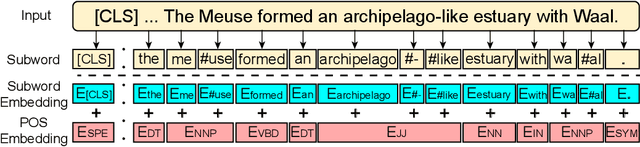
As a broad and major category in machine reading comprehension (MRC), the generalized goal of discriminative MRC is answer prediction from the given materials. However, the focuses of various discriminative MRC tasks may be diverse enough: multi-choice MRC requires model to highlight and integrate all potential critical evidence globally; while extractive MRC focuses on higher local boundary preciseness for answer extraction. Among previous works, there lacks a unified design with pertinence for the overall discriminative MRC tasks. To fill in above gap, we propose a lightweight POS-Enhanced Iterative Co-Attention Network (POI-Net) as the first attempt of unified modeling with pertinence, to handle diverse discriminative MRC tasks synchronously. Nearly without introducing more parameters, our lite unified design brings model significant improvement with both encoder and decoder components. The evaluation results on four discriminative MRC benchmarks consistently indicate the general effectiveness and applicability of our model, and the code is available at https://github.com/Yilin1111/poi-net.
Distinguishing Non-natural from Natural Adversarial Samples for More Robust Pre-trained Language Model
Mar 19, 2022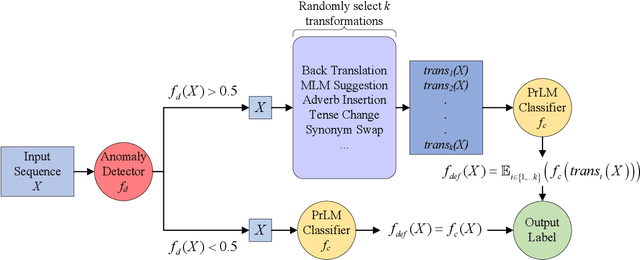

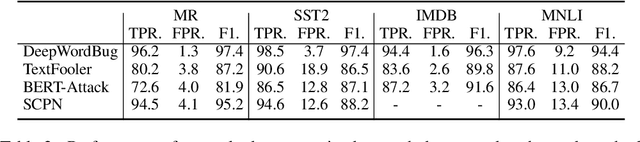
Recently, the problem of robustness of pre-trained language models (PrLMs) has received increasing research interest. Latest studies on adversarial attacks achieve high attack success rates against PrLMs, claiming that PrLMs are not robust. However, we find that the adversarial samples that PrLMs fail are mostly non-natural and do not appear in reality. We question the validity of current evaluation of robustness of PrLMs based on these non-natural adversarial samples and propose an anomaly detector to evaluate the robustness of PrLMs with more natural adversarial samples. We also investigate two applications of the anomaly detector: (1) In data augmentation, we employ the anomaly detector to force generating augmented data that are distinguished as non-natural, which brings larger gains to the accuracy of PrLMs. (2) We apply the anomaly detector to a defense framework to enhance the robustness of PrLMs. It can be used to defend all types of attacks and achieves higher accuracy on both adversarial samples and compliant samples than other defense frameworks.
Semantics-Preserved Distortion for Personal Privacy Protection
Jan 04, 2022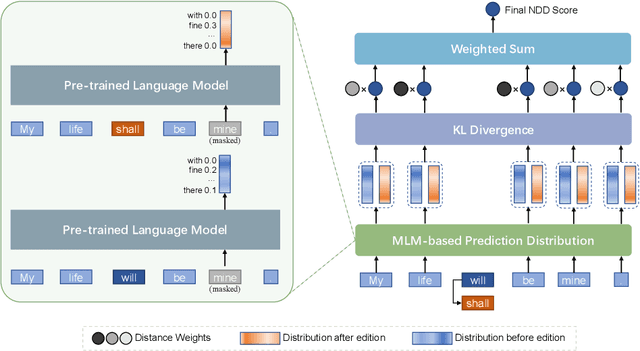
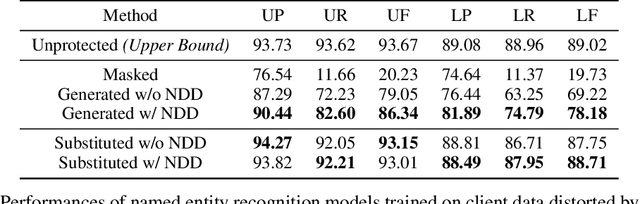
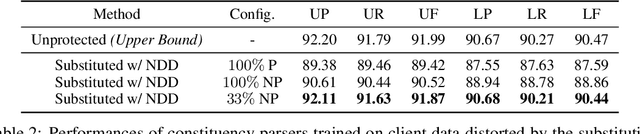

Privacy protection is an important and concerning topic in Federated Learning, especially for Natural Language Processing. In client devices, a large number of texts containing personal information are produced by users every day. As the direct application of information from users is likely to invade personal privacy, many methods have been proposed in Federated Learning to block the center model from the raw information in client devices. In this paper, we try to do this more linguistically via distorting the text while preserving the semantics. In practice, we leverage a recently proposed metric, Neighboring Distribution Divergence, to evaluate the semantic preservation during the distortion. Based on the metric, we propose two frameworks for semantics-preserved distortion, a generative one and a substitutive one. Due to the lack of privacy-related tasks in the current Natural Language Processing field, we conduct experiments on named entity recognition and constituency parsing. Results from our experiments show the plausibility and efficiency of our distortion as a method for personal privacy protection.