 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyffusion: A Diffusion Model for Polyphonic Score Generation with Internal and External Controls
Jul 19, 2023We propose Polyffusion, a diffusion model that generates polyphonic music scores by regarding music as image-like piano roll representations. The model is capable of controllable music generation with two paradigms: internal control and external control. Internal control refers to the process in which users pre-define a part of the music and then let the model infill the rest, similar to the task of masked music generation (or music inpainting). External control conditions the model with external yet related information, such as chord, texture, or other features, via the cross-attention mechanism. We show that by using internal and external controls, Polyffusion unifies a wide range of music creation tasks, including melody generation given accompaniment, accompaniment generation given melody, arbitrary music segment inpainting, and music arrangement given chords or textures. Experimental results show that our model significantly outperforms existing Transformer and sampling-based baselines, and using pre-trained disentangled representations as external conditions yields more effective controls.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jul 12, 2023In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
On the Effectiveness of Speech Self-supervised Learning for Music
Jul 11, 2023



Self-supervised learning (SSL) has shown promising results in various speech and natural language processing applications. However, its efficacy in music information retrieval (MIR) still remains largely unexplored. While previous SSL models pre-trained on music recordings may have been mostly closed-sourced, recent speech models such as wav2vec2.0 have shown promise in music modelling. Nevertheless, research exploring the effectiveness of applying speech SSL models to music recordings has been limited. We explore the music adaption of SSL with two distinctive speech-related models, data2vec1.0 and Hubert, and refer to them as music2vec and musicHuBERT, respectively. We train $12$ SSL models with 95M parameters under various pre-training configurations and systematically evaluate the MIR task performances with 13 different MIR tasks. Our findings suggest that training with music data can generally improve performance on MIR tasks, even when models are trained using paradigms designed for speech. However, we identify the limitations of such existing speech-oriented designs, especially in modelling polyphonic information. Based on the experimental results, empirical suggestions are also given for designing future musical SSL strategies and paradigms.
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Jun 06, 2023



Self-supervised learning (SSL) has recently emerged as a promising paradigm for training generalisable models on large-scale data in the fields of vision, text, and speech. Although SSL has been proven effective in speech and audio, its application to music audio has yet to be thoroughly explored. This is primarily due to the distinctive challenges associated with modelling musical knowledge, particularly its tonal and pitched characteristics of music. To address this research gap, we propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels in the masked language modelling (MLM) style acoustic pre-training. In our exploration, we identified a superior combination of teacher models, which outperforms conventional speech and audio approaches in terms of performance. This combination includes an acoustic teacher based on Residual Vector Quantization - Variational AutoEncoder (RVQ-VAE) and a musical teacher based on the Constant-Q Transform (CQT). These teachers effectively guide our student model, a BERT-style transformer encoder, to better model music audio. In addition, we introduce an in-batch noise mixture augmentation to enhance the representation robustness. Furthermore, we explore a wide range of settings to overcome the instability in acoustic language model pre-training, which allows our designed paradigm to scale from 95M to 330M parameters. Experimental results indicate that our model can generalise and perform well on 14 music understanding tasks and attains state-of-the-art (SOTA) overall scores. The code and models are online: https://github.com/yizhilll/MERT.
Q&A: Query-Based Representation Learning for Multi-Track Symbolic Music re-Arrangement
Jun 02, 2023



Music rearrangement is a common music practice of reconstructing and reconceptualizing a piece using new composition or instrumentation styles, which is also an important task of automatic music generation. Existing studies typically model the mapping from a source piece to a target piece via supervised learning. In this paper, we tackle rearrangement problems via self-supervised learning, in which the mapping styles can be regarded as conditions and controlled in a flexible way. Specifically, we are inspired by the representation disentanglement idea and propose Q&A, a query-based algorithm for multi-track music rearrangement under an encoder-decoder framework. Q&A learns both a content representation from the mixture and function (style) representations from each individual track, while the latter queries the former in order to rearrange a new piece. Our current model focuses on popular music and provides a controllable pathway to four scenarios: 1) re-instrumentation, 2) piano cover generation, 3) orchestration, and 4) voice separation. Experiments show that our query system achieves high-quality rearrangement results with delicate multi-track structures, significantly outperforming the baselines.
Calliffusion: Chinese Calligraphy Generation and Style Transfer with Diffusion Modeling
May 30, 2023



In this paper, we propose Calliffusion, a system for generating high-quality Chinese calligraphy using diffusion models. Our model architecture is based on DDPM (Denoising Diffusion Probabilistic Models), and it is capable of generating common characters in five different scripts and mimicking the styles of famous calligraphers. Experiments demonstrate that our model can generate calligraphy that is difficult to distinguish from real artworks and that our controls for characters, scripts, and styles are effective. Moreover, we demonstrate one-shot transfer learning, using LoRA (Low-Rank Adaptation) to transfer Chinese calligraphy art styles to unseen characters and even out-of-domain symbols such as English letters and digits.
Learning Interpretable Low-dimensional Representation via Physical Symmetry
Feb 24, 2023Interpretable representation learning has been playing a key role in creative intelligent systems. In the music domain, current learning algorithms can successfully learn various features such as pitch, timbre, chord, texture, etc. However, most methods rely heavily on music domain knowledge. It remains an open question what general computational principles give rise to interpretable representations, especially low-dim factors that agree with human perception. In this study, we take inspiration from modern physics and use physical symmetry as a self-consistency constraint for the latent space. Specifically, it requires the prior model that characterises the dynamics of the latent states to be equivariant with respect to certain group transformations. We show that physical symmetry leads the model to learn a linear pitch factor from unlabelled monophonic music audio in a self-supervised fashion. In addition, the same methodology can be applied to computer vision, learning a 3D Cartesian space from videos of a simple moving object without labels. Furthermore, physical symmetry naturally leads to representation augmentation, a new technique which improves sample efficiency.
Vis2Mus: Exploring Multimodal Representation Mapping for Controllable Music Generation
Nov 10, 2022In this study, we explore the representation mapping from the domain of visual arts to the domain of music, with which we can use visual arts as an effective handle to control music generation. Unlike most studies in multimodal representation learning that are purely data-driven, we adopt an analysis-by-synthesis approach that combines deep music representation learning with user studies. Such an approach enables us to discover \textit{interpretable} representation mapping without a huge amount of paired data. In particular, we discover that visual-to-music mapping has a nice property similar to equivariant. In other words, we can use various image transformations, say, changing brightness, changing contrast, style transfer, to control the corresponding transformations in the music domain. In addition, we released the Vis2Mus system as a controllable interface for symbolic music generation.
Self-Supervised Hierarchical Metrical Structure Modeling
Oct 31, 2022



We propose a novel method to model hierarchical metrical structures for both symbolic music and audio signals in a self-supervised manner with minimal domain knowledge. The model trains and inferences on beat-aligned music signals and predicts an 8-layer hierarchical metrical tree from beat, measure to the section level. The training procedural does not require any hierarchical metrical labeling except for beats, purely relying on the nature of metrical regularity and inter-voice consistency as inductive biases. We show in experiments that the method achieves comparable performance with supervised baselines on multiple metrical structure analysis tasks on both symbolic music and audio signals. All demos, source code and pre-trained models are publicly available on GitHub.
Modeling Perceptual Loudness of Piano Tone: Theory and Applications
Sep 21, 2022
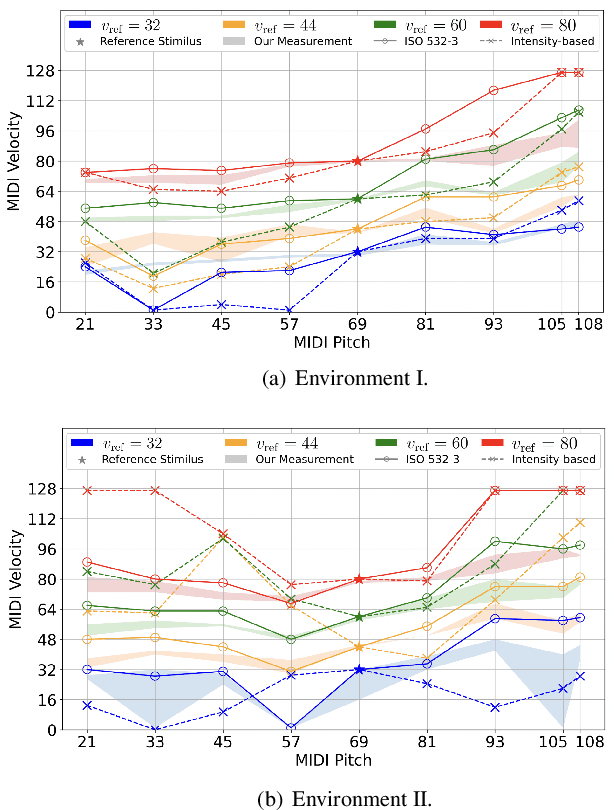
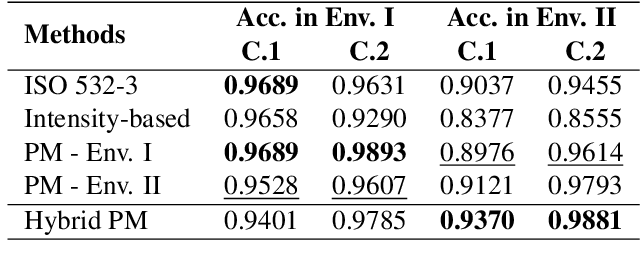
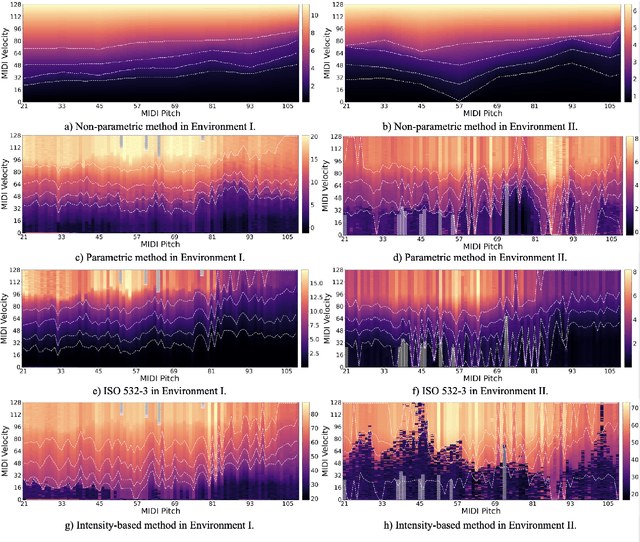
The relationship between perceptual loudness and physical attributes of sound is an important subject in both computer music and psychoacoustics. Early studies of "equal-loudness contour" can trace back to the 1920s and the measured loudness with respect to intensity and frequency has been revised many times since then. However, most studies merely focus on synthesized sound, and the induced theories on natural tones with complex timbre have rarely been justified. To this end, we investigate both theory and applications of natural-tone loudness perception in this paper via modeling piano tone. The theory part contains: 1) an accurate measurement of piano-tone equal-loudness contour of pitches, and 2) a machine-learning model capable of inferring loudness purely based on spectral features trained on human subject measurements. As for the application, we apply our theory to piano control transfer, in which we adjust the MIDI velocities on two different player pianos (in different acoustic environments) to achieve the same perceptual effect. Experiments show that both our theoretical loudness modeling and the corresponding performance control transfer algorithm significantly outperform their baselines.