 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenvalue Corrected Noisy Natural Gradient
Nov 30, 2018
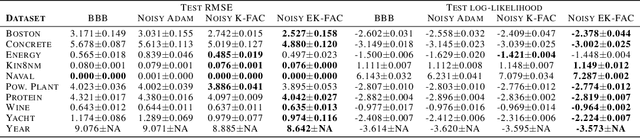
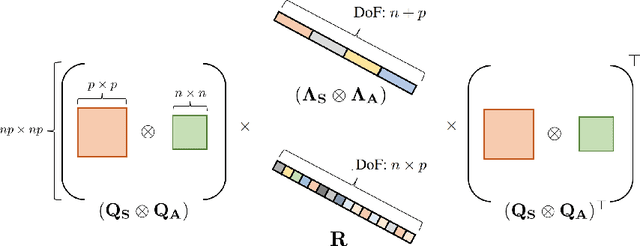
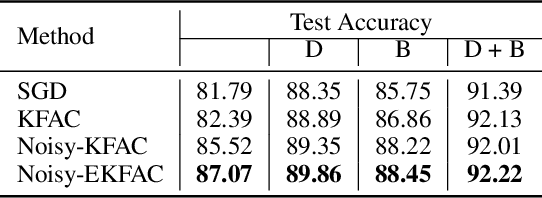
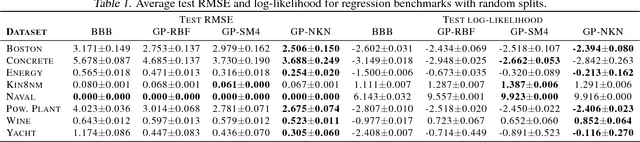
Variational Bayesian neural networks combine the flexibility of deep learning with Bayesian uncertainty estimation. However, inference procedures for flexible variational posteriors are computationally expensive. A recently proposed method, noisy natural gradient, is a surprisingly simple method to fit expressive posteriors by adding weight noise to regular natural gradient updates. Noisy K-FAC is an instance of noisy natural gradient that fits a matrix-variate Gaussian posterior with minor changes to ordinary K-FAC. Nevertheless, a matrix-variate Gaussian posterior does not capture an accurate diagonal variance. In this work, we extend on noisy K-FAC to obtain a more flexible posterior distribution called eigenvalue corrected matrix-variate Gaussian. The proposed method computes the full diagonal re-scaling factor in Kronecker-factored eigenbasis. Empirically, our approach consistently outperforms existing algorithms (e.g., noisy K-FAC) on regression and classification tasks.
Three Mechanisms of Weight Decay Regularization
Oct 29, 2018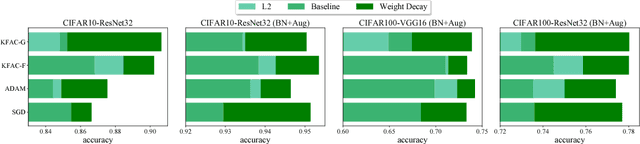
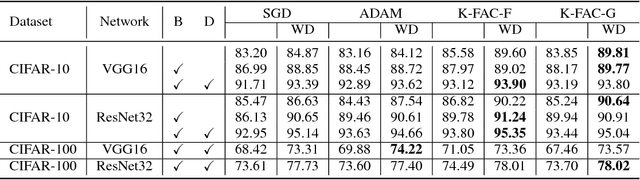
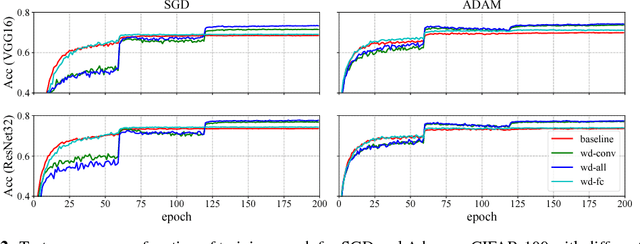
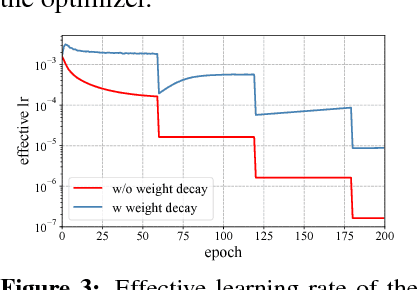
Weight decay is one of the standard tricks in the neural network toolbox, but the reasons for its regularization effect are poorly understood, and recent results have cast doubt on the traditional interpretation in terms of $L_2$ regularization. Literal weight decay has been shown to outperform $L_2$ regularization for optimizers for which they differ. We empirically investigate weight decay for three optimization algorithms (SGD, Adam, and K-FAC) and a variety of network architectures. We identify three distinct mechanisms by which weight decay exerts a regularization effect, depending on the particular optimization algorithm and architecture: (1) increasing the effective learning rate, (2) approximately regularizing the input-output Jacobian norm, and (3) reducing the effective damping coefficient for second-order optimization. Our results provide insight into how to improve the regularization of neural networks.
Differentiable Compositional Kernel Learning for Gaussian Processes
Aug 05, 2018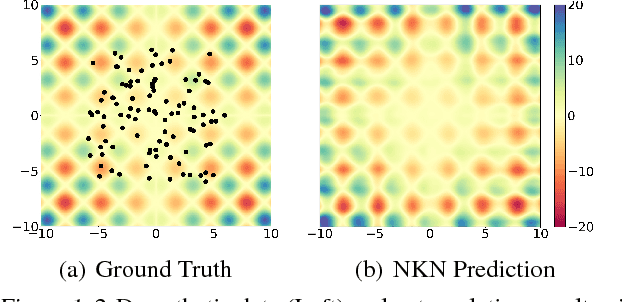

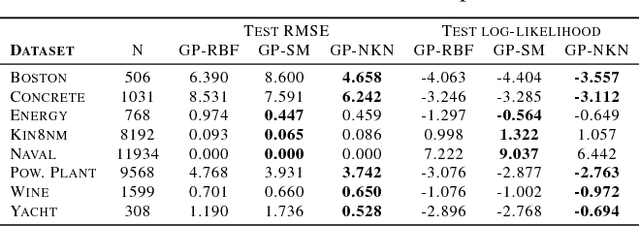
The generalization properties of Gaussian processes depend heavily on the choice of kernel, and this choice remains a dark art. We present the Neural Kernel Network (NKN), a flexible family of kernels represented by a neural network. The NKN architecture is based on the composition rules for kernels, so that each unit of the network corresponds to a valid kernel. It can compactly approximate compositional kernel structures such as those used by the Automatic Statistician (Lloyd et al., 2014), but because the architecture is differentiable, it is end-to-end trainable with gradient-based optimization. We show that the NKN is universal for the class of stationary kernels. Empirically we demonstrate pattern discovery and extrapolation abilities of NKN on several tasks that depend crucially on identifying the underlying structure, including time series and texture extrapolation, as well as Bayesian optimization.
Noisy Natural Gradient as Variational Inference
Feb 26, 2018
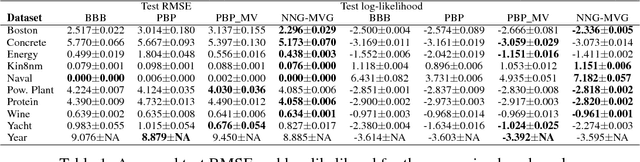
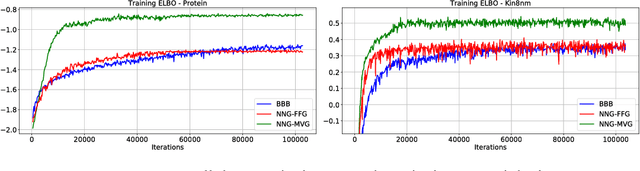
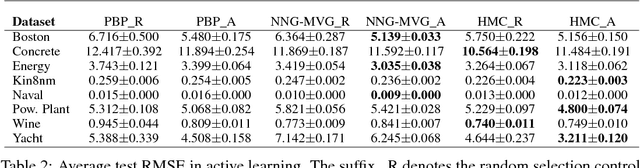
Variational Bayesian neural nets combine the flexibility of deep learning with Bayesian uncertainty estimation. Unfortunately, there is a tradeoff between cheap but simple variational families (e.g.~fully factorized) or expensive and complicated inference procedures. We show that natural gradient ascent with adaptive weight noise implicitly fits a variational posterior to maximize the evidence lower bound (ELBO). This insight allows us to train full-covariance, fully factorized, or matrix-variate Gaussian variational posteriors using noisy versions of natural gradient, Adam, and K-FAC, respectively, making it possible to scale up to modern-size ConvNets. On standard regression benchmarks, our noisy K-FAC algorithm makes better predictions and matches Hamiltonian Monte Carlo's predictive variances better than existing methods. Its improved uncertainty estimates lead to more efficient exploration in active learning, and intrinsic motivation for reinforcement learning.
Deformable Convolutional Networks
Jun 05, 2017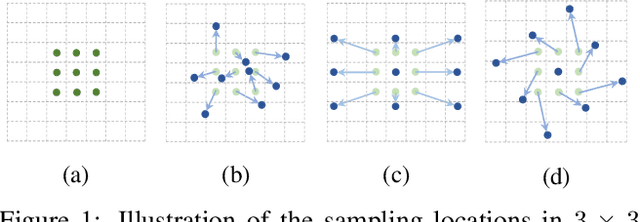
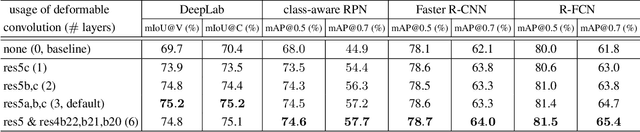
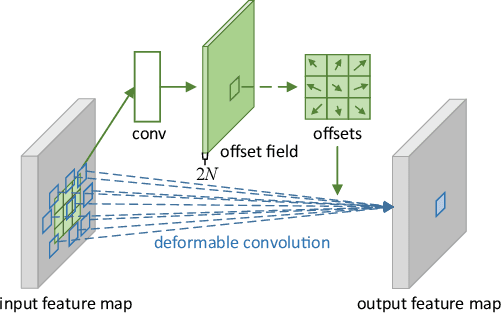
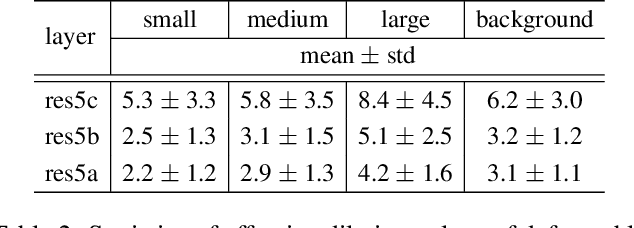
Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in its building modules. In this work, we introduce two new modules to enhance the transformation modeling capacity of CNNs, namely, deformable convolution and deformable RoI pooling. Both are based on the idea of augmenting the spatial sampling locations in the modules with additional offsets and learning the offsets from target tasks, without additional supervision. The new modules can readily replace their plain counterparts in existing CNNs and can be easily trained end-to-end by standard back-propagation, giving rise to deformable convolutional networks. Extensive experiments validate the effectiveness of our approach on sophisticated vision tasks of object detection and semantic segmentation. The code would be released.