 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Video Question Answering with Sparsified Inputs
Nov 27, 2023



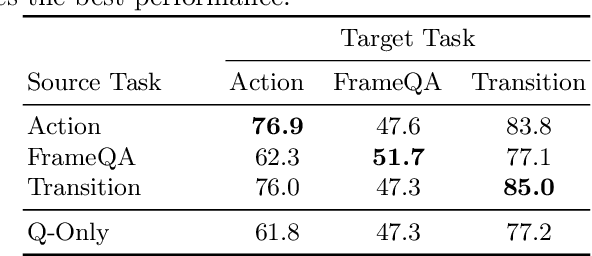
In Video Question Answering, videos are often processed as a full-length sequence of frames to ensure minimal loss of information. Recent works have demonstrated evidence that sparse video inputs are sufficient to maintain high performance. However, they usually discuss the case of single frame selection. In our work, we extend the setting to multiple number of inputs and other modalities. We characterize the task with different input sparsity and provide a tool for doing that. Specifically, we use a Gumbel-based learnable selection module to adaptively select the best inputs for the final task. In this way, we experiment over public VideoQA benchmarks and provide analysis on how sparsified inputs affect the performance. From our experiments, we have observed only 5.2%-5.8% loss of performance with only 10% of video lengths, which corresponds to 2-4 frames selected from each video. Meanwhile, we also observed the complimentary behaviour between visual and textual inputs, even under highly sparsified settings, suggesting the potential of improving data efficiency for video-and-language tasks.
Decision Making for Human-in-the-loop Robotic Agents via Uncertainty-Aware Reinforcement Learning
Mar 14, 2023In a Human-in-the-Loop paradigm, a robotic agent is able to act mostly autonomously in solving a task, but can request help from an external expert when needed. However, knowing when to request such assistance is critical: too few requests can lead to the robot making mistakes, but too many requests can overload the expert. In this paper, we present a Reinforcement Learning based approach to this problem, where a semi-autonomous agent asks for external assistance when it has low confidence in the eventual success of the task. The confidence level is computed by estimating the variance of the return from the current state. We show that this estimate can be iteratively improved during training using a Bellman-like recursion. On discrete navigation problems with both fully- and partially-observable state information, we show that our method makes effective use of a limited budget of expert calls at run-time, despite having no access to the expert at training time.
RREx-BoT: Remote Referring Expressions with a Bag of Tricks
Jan 30, 2023



Household robots operate in the same space for years. Such robots incrementally build dynamic maps that can be used for tasks requiring remote object localization. However, benchmarks in robot learning often test generalization through inference on tasks in unobserved environments. In an observed environment, locating an object is reduced to choosing from among all object proposals in the environment, which may number in the 100,000s. Armed with this intuition, using only a generic vision-language scoring model with minor modifications for 3d encoding and operating in an embodied environment, we demonstrate an absolute performance gain of 9.84% on remote object grounding above state of the art models for REVERIE and of 5.04% on FAO. When allowed to pre-explore an environment, we also exceed the previous state of the art pre-exploration method on REVERIE. Additionally, we demonstrate our model on a real-world TurtleBot platform, highlighting the simplicity and usefulness of the approach. Our analysis outlines a "bag of tricks" essential for accomplishing this task, from utilizing 3d coordinates and context, to generalizing vision-language models to large 3d search spaces.
Video in 10 Bits: Few-Bit VideoQA for Efficiency and Privacy
Oct 18, 2022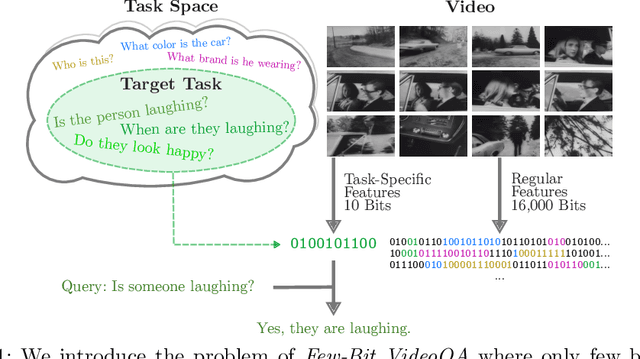

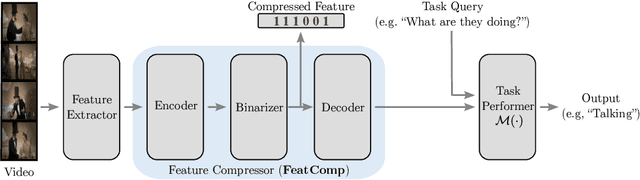
In Video Question Answering (VideoQA), answering general questions about a video requires its visual information. Yet, video often contains redundant information irrelevant to the VideoQA task. For example, if the task is only to answer questions similar to "Is someone laughing in the video?", then all other information can be discarded. This paper investigates how many bits are really needed from the video in order to do VideoQA by introducing a novel Few-Bit VideoQA problem, where the goal is to accomplish VideoQA with few bits of video information (e.g., 10 bits). We propose a simple yet effective task-specific feature compression approach to solve this problem. Specifically, we insert a lightweight Feature Compression Module (FeatComp) into a VideoQA model which learns to extract task-specific tiny features as little as 10 bits, which are optimal for answering certain types of questions. We demonstrate more than 100,000-fold storage efficiency over MPEG4-encoded videos and 1,000-fold over regular floating point features, with just 2.0-6.6% absolute loss in accuracy, which is a surprising and novel finding. Finally, we analyze what the learned tiny features capture and demonstrate that they have eliminated most of the non-task-specific information, and introduce a Bit Activation Map to visualize what information is being stored. This decreases the privacy risk of data by providing k-anonymity and robustness to feature-inversion techniques, which can influence the machine learning community, allowing us to store data with privacy guarantees while still performing the task effectively.
Visual Grounding in Video for Unsupervised Word Translation
Mar 26, 2020
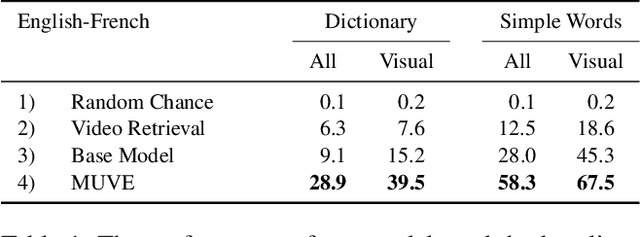
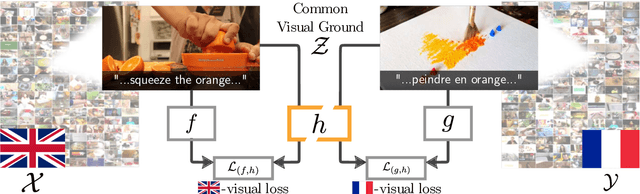
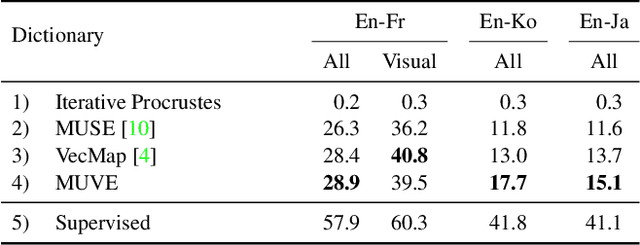
There are thousands of actively spoken languages on Earth, but a single visual world. Grounding in this visual world has the potential to bridge the gap between all these languages. Our goal is to use visual grounding to improve unsupervised word mapping between languages. The key idea is to establish a common visual representation between two languages by learning embeddings from unpaired instructional videos narrated in the native language. Given this shared embedding we demonstrate that (i) we can map words between the languages, particularly the 'visual' words; (ii) that the shared embedding provides a good initialization for existing unsupervised text-based word translation techniques, forming the basis for our proposed hybrid visual-text mapping algorithm, MUVE; and (iii) our approach achieves superior performance by addressing the shortcomings of text-based methods -- it is more robust, handles datasets with less commonality, and is applicable to low-resource languages. We apply these methods to translate words from English to French, Korean, and Japanese -- all without any parallel corpora and simply by watching many videos of people speaking while doing things.
* CVPR 2020
Beyond the Camera: Neural Networks in World Coordinates
Mar 12, 2020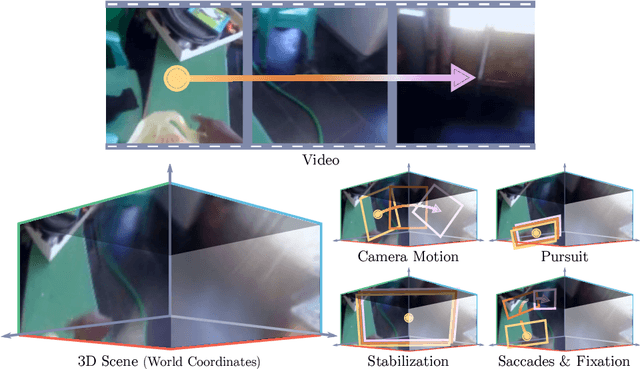
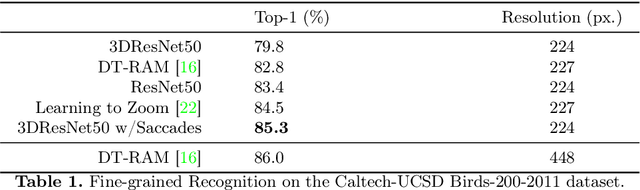

Eye movement and strategic placement of the visual field onto the retina, gives animals increased resolution of the scene and suppresses distracting information. This fundamental system has been missing from video understanding with deep networks, typically limited to 224 by 224 pixel content locked to the camera frame. We propose a simple idea, WorldFeatures, where each feature at every layer has a spatial transformation, and the feature map is only transformed as needed. We show that a network built with these WorldFeatures, can be used to model eye movements, such as saccades, fixation, and smooth pursuit, even in a batch setting on pre-recorded video. That is, the network can for example use all 224 by 224 pixels to look at a small detail one moment, and the whole scene the next. We show that typical building blocks, such as convolutions and pooling, can be adapted to support WorldFeatures using available tools. Experiments are presented on the Charades, Olympic Sports, and Caltech-UCSD Birds-200-2011 datasets, exploring action recognition, fine-grained recognition, and video stabilization.
Charades-Ego: A Large-Scale Dataset of Paired Third and First Person Videos
Apr 30, 2018


In Actor and Observer we introduced a dataset linking the first and third-person video understanding domains, the Charades-Ego Dataset. In this paper we describe the egocentric aspect of the dataset and present annotations for Charades-Ego with 68,536 activity instances in 68.8 hours of first and third-person video, making it one of the largest and most diverse egocentric datasets available. Charades-Ego furthermore shares activity classes, scripts, and methodology with the Charades dataset, that consist of additional 82.3 hours of third-person video with 66,500 activity instances. Charades-Ego has temporal annotations and textual descriptions, making it suitable for egocentric video classification, localization, captioning, and new tasks utilizing the cross-modal nature of the data.
Actor and Observer: Joint Modeling of First and Third-Person Videos
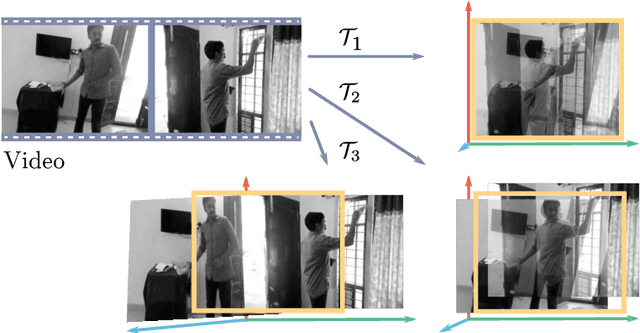
Apr 25, 2018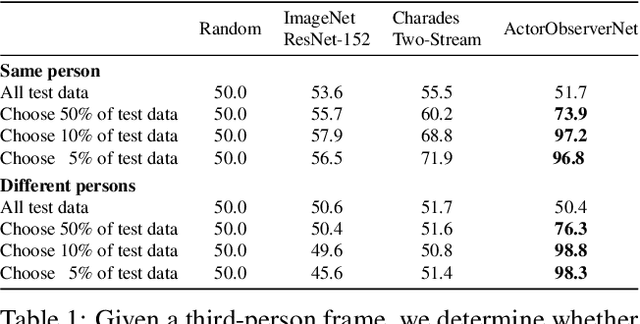


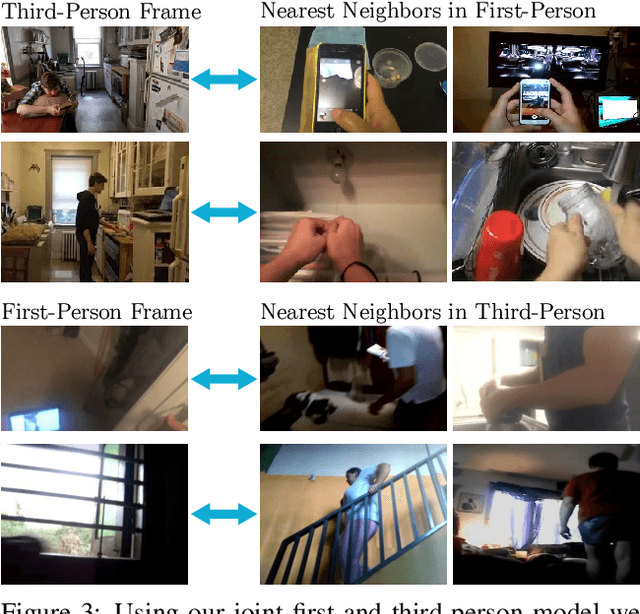
Several theories in cognitive neuroscience suggest that when people interact with the world, or simulate interactions, they do so from a first-person egocentric perspective, and seamlessly transfer knowledge between third-person (observer) and first-person (actor). Despite this, learning such models for human action recognition has not been achievable due to the lack of data. This paper takes a step in this direction, with the introduction of Charades-Ego, a large-scale dataset of paired first-person and third-person videos, involving 112 people, with 4000 paired videos. This enables learning the link between the two, actor and observer perspectives. Thereby, we address one of the biggest bottlenecks facing egocentric vision research, providing a link from first-person to the abundant third-person data on the web. We use this data to learn a joint representation of first and third-person videos, with only weak supervision, and show its effectiveness for transferring knowledge from the third-person to the first-person domain.
* CVPR 2018 spotlight presentation
What Actions are Needed for Understanding Human Actions in Videos?
Aug 09, 2017

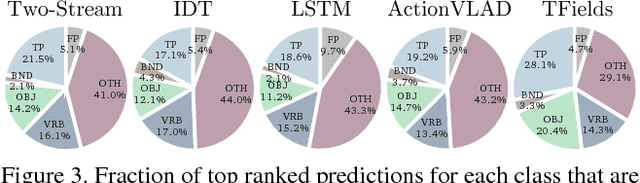
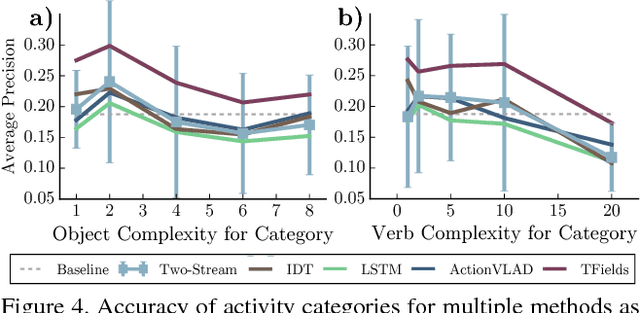
What is the right way to reason about human activities? What directions forward are most promising? In this work, we analyze the current state of human activity understanding in videos. The goal of this paper is to examine datasets, evaluation metrics, algorithms, and potential future directions. We look at the qualitative attributes that define activities such as pose variability, brevity, and density. The experiments consider multiple state-of-the-art algorithms and multiple datasets. The results demonstrate that while there is inherent ambiguity in the temporal extent of activities, current datasets still permit effective benchmarking. We discover that fine-grained understanding of objects and pose when combined with temporal reasoning is likely to yield substantial improvements in algorithmic accuracy. We present the many kinds of information that will be needed to achieve substantial gains in activity understanding: objects, verbs, intent, and sequential reasoning. The software and additional information will be made available to provide other researchers detailed diagnostics to understand their own algorithms.
Asynchronous Temporal Fields for Action Recognition
Jul 24, 2017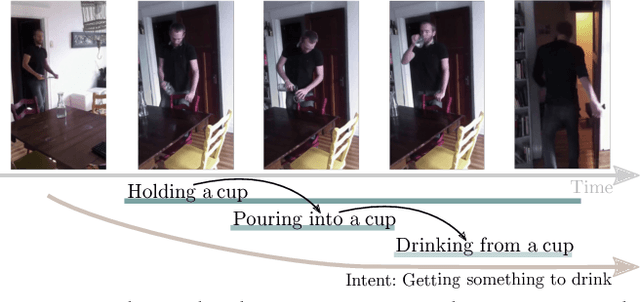

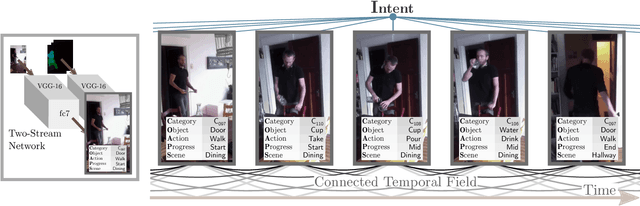
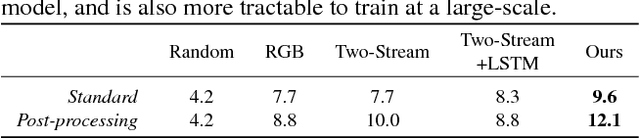
Actions are more than just movements and trajectories: we cook to eat and we hold a cup to drink from it. A thorough understanding of videos requires going beyond appearance modeling and necessitates reasoning about the sequence of activities, as well as the higher-level constructs such as intentions. But how do we model and reason about these? We propose a fully-connected temporal CRF model for reasoning over various aspects of activities that includes objects, actions, and intentions, where the potentials are predicted by a deep network. End-to-end training of such structured models is a challenging endeavor: For inference and learning we need to construct mini-batches consisting of whole videos, leading to mini-batches with only a few videos. This causes high-correlation between data points leading to breakdown of the backprop algorithm. To address this challenge, we present an asynchronous variational inference method that allows efficient end-to-end training. Our method achieves a classification mAP of 22.4% on the Charades benchmark, outperforming the state-of-the-art (17.2% mAP), and offers equal gains on the task of temporal localization.